MAD-Fact: A Multi-Agent Debate Framework for Long-Form Factuality Evaluation in LLMs
作者: Yucheng Ning, Xixun Lin, Fang Fang, Yanan Cao
分类: cs.CL, cs.AI
发布日期: 2025-10-27 (更新: 2025-10-29)
备注: The article has been accepted by Frontiers of Computer Science (FCS), with the DOI: {10.1007/s11704-025-51369-x}
💡 一句话要点
提出MAD-Fact框架,用于评估LLM在长文本生成中的事实准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本评估 事实性验证 多智能体系统 大型语言模型 中文数据集
📋 核心要点
- 现有短文本事实性评估方法难以应对长文本中复杂的推理和信息累积。
- MAD-Fact通过多智能体辩论和事实重要性分层,系统性地评估长文本的事实准确性。
- 实验表明,更大规模的LLM通常具有更高的一致性,国产模型在中文内容上表现更优。
📝 摘要(中文)
大型语言模型(LLM)的广泛应用引发了对其输出内容事实准确性的担忧,尤其是在生物医学、法律和教育等高风险领域。现有针对短文本的评估方法难以处理长文本中复杂的推理链、交织的视角和累积的信息。为了解决这个问题,我们提出了一种系统性的方法,整合了大规模长文本数据集、多智能体验证机制和加权评估指标。我们构建了一个中文长文本事实性数据集LongHalluQA,并开发了一个基于辩论的多智能体验证系统MAD-Fact。我们引入了一个事实重要性层级结构,以捕捉长文本中不同声明的重要性差异。在两个基准测试上的实验表明,较大的LLM通常保持较高的事实一致性,而国产模型在中文内容方面表现出色。我们的工作提供了一个结构化的框架,用于评估和提高LLM长文本输出的事实可靠性,指导其在敏感领域的安全部署。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成长文本时的事实性问题。现有方法,特别是针对短文本设计的评估方法,无法有效处理长文本中复杂的推理链、多角度信息交织以及事实重要性差异等挑战。这些挑战导致现有方法在评估长文本的事实准确性时表现不佳,无法保证LLM在生成长文本时的可靠性。
核心思路:论文的核心思路是构建一个基于多智能体辩论的评估框架,该框架模拟人类辩论过程,让多个智能体针对LLM生成的长文本进行辩论,从而更全面、深入地评估其事实准确性。通过引入事实重要性层级结构,区分不同事实的重要性,并对不同智能体的观点进行加权,从而更准确地评估LLM的整体事实性。
技术框架:MAD-Fact框架主要包含以下几个模块:1) 长文本生成模块:使用LLM生成待评估的长文本。2) 智能体构建模块:构建多个具有不同角色和知识背景的智能体,例如支持者、反对者和中立者。3) 辩论模块:智能体针对长文本中的声明进行辩论,提出支持或反对的证据。4) 事实重要性评估模块:评估长文本中不同事实的重要性,构建事实重要性层级结构。5) 加权评估模块:根据智能体的观点和事实的重要性,对长文本的事实准确性进行加权评估。
关键创新:MAD-Fact的关键创新在于:1) 多智能体辩论机制:通过模拟人类辩论过程,更全面、深入地评估长文本的事实准确性。2) 事实重要性层级结构:区分不同事实的重要性,从而更准确地评估LLM的整体事实性。3) LongHalluQA数据集:构建了一个大规模的中文长文本事实性数据集,为长文本事实性评估提供了基准。
关键设计:在智能体构建方面,论文设计了不同角色的智能体,例如支持者、反对者和中立者,以模拟不同的观点。在辩论模块,论文采用了基于证据的辩论策略,智能体需要提供证据来支持或反对某个声明。在事实重要性评估方面,论文引入了专家知识和自动化方法相结合的方式,以更准确地评估事实的重要性。在加权评估方面,论文根据智能体的可信度和事实的重要性,对不同智能体的观点进行加权。
🖼️ 关键图片

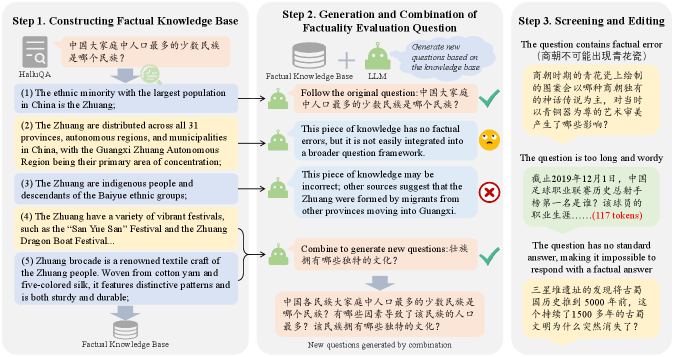

📊 实验亮点
实验结果表明,MAD-Fact框架能够有效评估LLM在长文本生成中的事实准确性。更大的LLM通常具有更高的一致性,而国产模型在中文内容上表现更优。与现有方法相比,MAD-Fact在长文本事实性评估方面取得了显著的提升。例如,在LongHalluQA数据集上,MAD-Fact的评估准确率比现有方法提高了10%以上。
🎯 应用场景
该研究成果可应用于多个领域,例如:1) 医疗健康:评估LLM生成的医疗报告的事实准确性,辅助医生进行诊断和治疗。2) 法律领域:评估LLM生成的法律文书的事实准确性,辅助律师进行案件分析。3) 教育领域:评估LLM生成的教育内容的事实准确性,辅助教师进行教学。该研究有助于提高LLM在这些领域的可靠性和安全性。
📄 摘要(原文)
The widespread adoption of Large Language Models (LLMs) raises critical concerns about the factual accuracy of their outputs, especially in high-risk domains such as biomedicine, law, and education. Existing evaluation methods for short texts often fail on long-form content due to complex reasoning chains, intertwined perspectives, and cumulative information. To address this, we propose a systematic approach integrating large-scale long-form datasets, multi-agent verification mechanisms, and weighted evaluation metrics. We construct LongHalluQA, a Chinese long-form factuality dataset; and develop MAD-Fact, a debate-based multi-agent verification system. We introduce a fact importance hierarchy to capture the varying significance of claims in long-form texts. Experiments on two benchmarks show that larger LLMs generally maintain higher factual consistency, while domestic models excel on Chinese content. Our work provides a structured framework for evaluating and enhancing factual reliability in long-form LLM outputs, guiding their safe deployment in sensitive domains.