Ming-UniAudio: Speech LLM for Joint Understanding, Generation and Editing with Unified Representation
作者: Canxiang Yan, Chunxiang Jin, Dawei Huang, Haibing Yu, Han Peng, Hui Zhan, Jie Gao, Jing Peng, Jingdong Chen, Jun Zhou, Kaimeng Ren, Ming Yang, Mingxue Yang, Qiang Xu, Qin Zhao, Ruijie Xiong, Shaoxiong Lin, Xuezhi Wang, Yi Yuan, Yifei Wu, Yongjie Lyu, Zhengyu He, Zhihao Qiu, Zhiqiang Fang, Ziyuan Huang
分类: cs.CL, cs.AI, cs.SD, eess.AS
发布日期: 2025-10-26
备注: 32 pages, 8 figures
💡 一句话要点
Ming-UniAudio:统一语音表示的语音LLM,用于联合理解、生成和编辑
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 语音语言模型 语音理解 语音生成 语音编辑 连续语音分词 统一表示 自然语言指令
📋 核心要点
- 现有语音模型在理解和生成任务的token表示上存在竞争需求,导致难以进行基于指令的自由形式编辑。
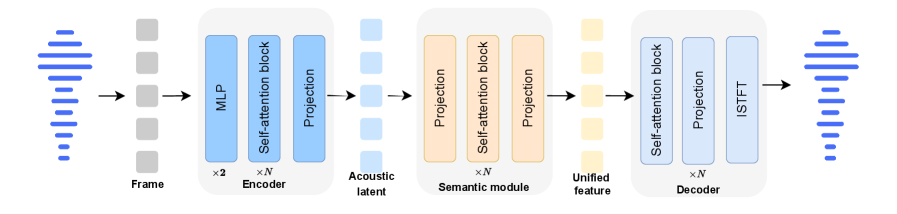
- 提出了一种统一的框架,核心是统一的连续语音分词器MingTok-Audio,有效整合语义和声学特征,适用于理解和生成任务。
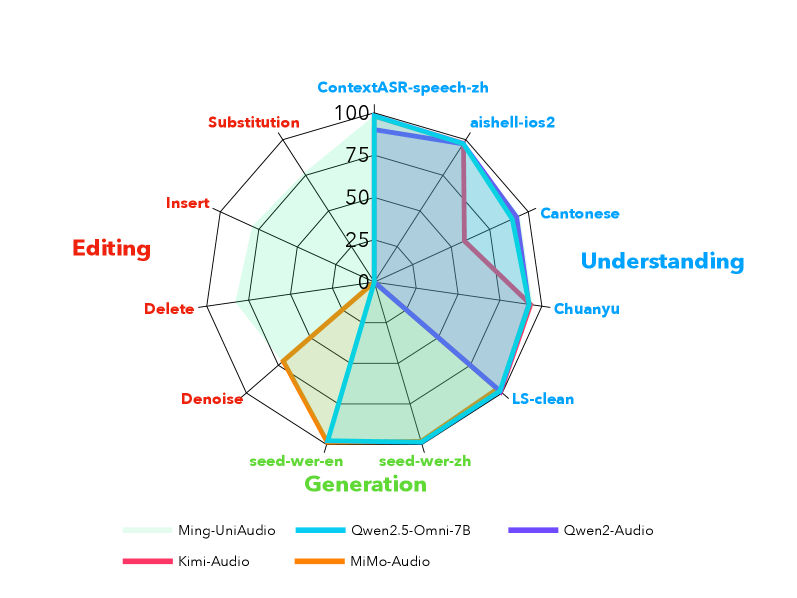
- Ming-UniAudio在ContextASR基准测试中取得了新的SOTA记录,并在中文语音克隆方面表现出色,同时开源了相关模型。
📝 摘要(中文)
本文提出了一种新的框架,用于统一语音理解、生成和编辑。该框架的核心是一个统一的连续语音分词器MingTok-Audio,它是第一个有效整合语义和声学特征的连续分词器,使其适用于理解和生成任务。基于此,开发了语音语言模型Ming-UniAudio,在生成和理解能力之间取得了平衡,并在ContextASR基准测试的12个指标中的8个上创造了新的SOTA记录。特别是在中文语音克隆方面,实现了极具竞争力的Seed-TTS-WER 0.95。利用这个基础模型,进一步训练了一个专门的语音编辑模型Ming-UniAudio-Edit,这是第一个能够仅通过自然语言指令进行通用、自由形式语音编辑的语音语言模型,无需时间戳条件即可处理语义和声学修改。为了严格评估编辑能力并为未来的研究奠定基础,引入了Ming-Freeform-Audio-Edit,这是第一个为基于指令的自由形式语音编辑量身定制的综合基准,具有多样化的场景和跨越语义正确性、声学质量和指令对齐的评估维度。开放了连续音频分词器、统一的基础模型和基于自由形式指令的编辑模型,以促进统一的音频理解、生成和操作的发展。
🔬 方法详解
问题定义:现有语音模型在语音理解和语音生成任务中,对token表示的需求存在冲突。这种差异使得语音语言模型难以执行基于指令的自由形式编辑,例如在不改变语义的情况下修改语音的音色,或者在不影响语音质量的情况下修改内容。现有方法通常需要单独的模型或复杂的流程来处理不同的任务,缺乏统一性和灵活性。
核心思路:本文的核心思路是设计一个统一的连续语音分词器,能够同时捕获语音的语义和声学特征,从而为语音理解、生成和编辑任务提供一个通用的表示。通过这种统一的表示,可以避免不同任务之间的表示冲突,并简化模型的训练和推理过程。此外,利用大型语言模型(LLM)的强大能力,实现基于自然语言指令的语音编辑。
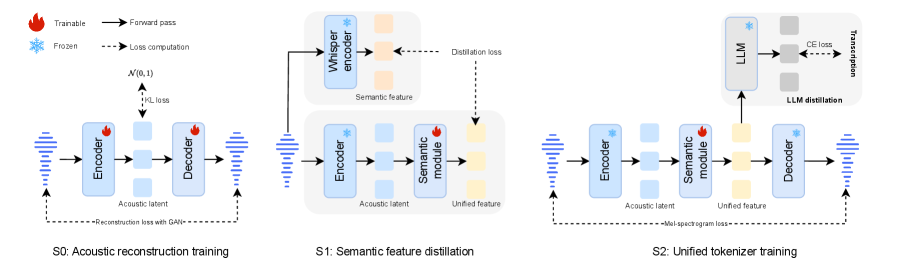
技术框架:该框架包含以下主要模块:1) 统一连续语音分词器MingTok-Audio:将原始语音信号转换为统一的连续token表示,同时包含语义和声学信息。2) 语音语言模型Ming-UniAudio:基于MingTok-Audio的token表示,利用Transformer架构进行训练,实现语音理解和生成能力。3) 语音编辑模型Ming-UniAudio-Edit:在Ming-UniAudio的基础上进行微调,使其能够根据自然语言指令对语音进行编辑。4) 评估基准Ming-Freeform-Audio-Edit:用于评估语音编辑模型的性能,包括语义正确性、声学质量和指令对齐等指标。
关键创新:最重要的技术创新点在于MingTok-Audio,它是第一个能够有效整合语义和声学特征的连续语音分词器。与传统的离散token表示相比,连续token表示能够更好地保留语音的细节信息,从而提高语音生成和编辑的质量。此外,Ming-UniAudio-Edit是第一个能够仅通过自然语言指令进行通用、自由形式语音编辑的语音语言模型,无需时间戳条件。
关键设计:MingTok-Audio的具体实现细节未知,但可以推测其可能采用了自监督学习的方法,例如对比学习或掩码预测,来学习语音的语义和声学表示。Ming-UniAudio和Ming-UniAudio-Edit可能采用了Transformer架构,并使用了大量的语音数据进行训练。损失函数的设计可能包括语音重建损失、语义分类损失和指令对齐损失等。
🖼️ 关键图片
📊 实验亮点
Ming-UniAudio在ContextASR基准测试的12个指标中的8个上创造了新的SOTA记录,证明了其强大的语音理解和生成能力。在中文语音克隆方面,实现了极具竞争力的Seed-TTS-WER 0.95,表明其在语音合成方面也具有很高的水平。Ming-UniAudio-Edit是第一个能够仅通过自然语言指令进行通用、自由形式语音编辑的语音语言模型。
🎯 应用场景
该研究成果可应用于语音助手、语音合成、语音编辑等领域。例如,用户可以通过自然语言指令修改语音助手的回复,或者对录音进行编辑和修复。该技术还可以用于语音克隆,生成具有特定音色的语音。未来,该技术有望实现更加智能和个性化的语音交互。
📄 摘要(原文)
Existing speech models suffer from competing requirements on token representations by understanding and generation tasks. This discrepancy in representation prevents speech language models from performing instruction-based free-form editing. To solve this challenge, we introduce a novel framework that unifies speech understanding, generation, and editing. The core of our unified model is a unified continuous speech tokenizer MingTok-Audio, the first continuous tokenizer to effectively integrate semantic and acoustic features, which makes it suitable for both understanding and generation tasks. Based on this unified continuous audio tokenizer, we developed the speech language model Ming-UniAudio, which achieved a balance between generation and understanding capabilities. Ming-UniAudio sets new state-of-the-art (SOTA) records on 8 out of 12 metrics on the ContextASR benchmark. Notably, for Chinese voice cloning, it achieves a highly competitive Seed-TTS-WER of 0.95. Leveraging this foundational model, we further trained a dedicated speech editing model Ming-UniAudio-Edit, the first speech language model that enables universal, free-form speech editing guided solely by natural language instructions, handling both semantic and acoustic modifications without timestamp condition. To rigorously assess the editing capability and establish a foundation for future research, we introduce Ming-Freeform-Audio-Edit, the first comprehensive benchmark tailored for instruction-based free-form speech editing, featuring diverse scenarios and evaluation dimensions spanning semantic correctness, acoustic quality, and instruction alignment. We open-sourced the continuous audio tokenizer, the unified foundational model, and the free-form instruction-based editing model to facilitate the development of unified audio understanding, generation, and manipulation.