A Comprehensive Dataset for Human vs. AI Generated Text Detection
作者: Rajarshi Roy, Nasrin Imanpour, Ashhar Aziz, Shashwat Bajpai, Gurpreet Singh, Shwetangshu Biswas, Kapil Wanaskar, Parth Patwa, Subhankar Ghosh, Shreyas Dixit, Nilesh Ranjan Pal, Vipula Rawte, Ritvik Garimella, Gaytri Jena, Amit Sheth, Vasu Sharma, Aishwarya Naresh Reganti, Vinija Jain, Aman Chadha, Amitava Das
分类: cs.CL
发布日期: 2025-10-26
备注: Defactify4 @AAAI 2025
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
构建大规模人机生成文本检测数据集,促进AI生成内容溯源与鉴别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成文本检测 大型语言模型 数据集构建 文本溯源 自然语言处理
📋 核心要点
- 现有AI生成文本检测方法缺乏大规模、多样化的数据集支持,难以有效应对快速发展的LLM所带来的挑战。
- 本研究构建了一个包含真实新闻和多种LLM生成文本的大规模数据集,旨在促进更可靠的AI生成文本检测和溯源方法。
- 实验结果表明,在区分人机生成文本和模型归因任务上,该数据集可作为基准,为后续研究提供有力支撑。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展导致AI生成的文本越来越像人类写作,引发了对内容真实性、错误信息和可信度的担忧。为了可靠地检测AI生成的文本并将其归因于特定模型,需要大规模、多样化且良好标注的数据集。本文提出了一个包含超过58,000个文本样本的综合数据集,该数据集结合了真实的《纽约时报》文章和由多个最先进的LLM(包括Gemma-2-9b、Mistral-7B、Qwen-2-72B、LLaMA-8B、Yi-Large和GPT-4-o)生成的合成版本。该数据集提供原始文章摘要作为提示,以及完整的人工撰写的叙述。我们为两个关键任务建立了基线结果:区分人工撰写和AI生成的文本,准确率为58.35%;将AI文本归因于其生成模型,准确率为8.92%。通过将真实的新闻内容与现代生成模型相结合,该数据集旨在促进鲁棒的检测和归因方法的开发,从而在生成式AI时代促进信任和透明度。我们的数据集可在https://huggingface.co/datasets/gsingh1-py/train 获取。
🔬 方法详解
问题定义:论文旨在解决AI生成文本检测和溯源问题。随着大型语言模型(LLMs)能力的提升,AI生成的文本越来越难以与人类撰写的文本区分,这给内容真实性、信息安全和知识产权保护带来了挑战。现有方法缺乏足够大规模和多样化的数据集进行训练和评估,难以有效应对新型LLM的生成文本。
核心思路:论文的核心思路是构建一个包含真实新闻文章和多种先进LLM生成文本的大规模数据集,为AI生成文本检测和溯源研究提供基准。通过提供多样化的数据,可以训练出更鲁棒的模型,从而提高检测和溯源的准确性。
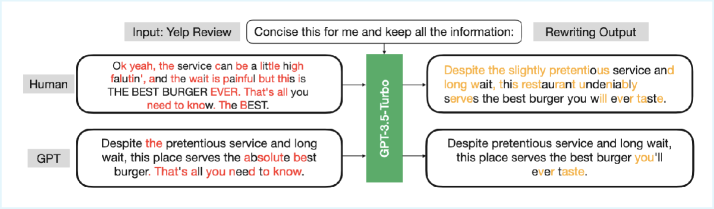
技术框架:该数据集构建流程主要包括以下几个阶段:1) 从《纽约时报》获取真实新闻文章及其摘要;2) 使用多个先进的LLM(如Gemma-2-9b、Mistral-7B、Qwen-2-72B、LLaMA-8B、Yi-Large和GPT-4-o)以新闻摘要作为提示生成对应的AI文本;3) 将真实新闻文章和AI生成文本进行标注,形成最终的数据集。
关键创新:该数据集的关键创新在于其规模和多样性。它包含了超过58,000个文本样本,涵盖了多种主题和风格,并且使用了多个最先进的LLM进行生成,从而能够更好地模拟真实世界中AI生成文本的分布。此外,数据集还提供了原始文章摘要作为提示,方便研究人员进行可控的文本生成和检测实验。
关键设计:数据集的关键设计包括:1) 选择《纽约时报》作为真实文本来源,保证了文本的质量和权威性;2) 选择多个具有代表性的LLM进行文本生成,覆盖了不同架构和训练方式的模型;3) 提供原始文章摘要作为提示,方便研究人员控制生成文本的内容和风格;4) 对每个文本样本进行详细标注,包括是否为AI生成、生成模型的名称等。
🖼️ 关键图片

📊 实验亮点
该论文构建的数据集在区分人机生成文本任务上取得了58.35%的准确率,在AI文本归因任务上取得了8.92%的准确率。这些结果为后续研究提供了基线,表明该数据集具有一定的挑战性和实用价值。未来研究可以通过引入更先进的模型和技术,进一步提高检测和归因的准确率。
🎯 应用场景
该数据集可广泛应用于AI生成内容检测、虚假信息识别、内容溯源、版权保护等领域。通过训练基于该数据集的模型,可以有效识别AI生成的文本,降低虚假信息传播的风险,并为内容创作者提供版权保护。未来,该数据集可以扩展到更多领域和语言,为构建可信赖的AI生态系统做出贡献。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.