Interpreting and Mitigating Unwanted Uncertainty in LLMs
作者: Tiasa Singha Roy, Ayush Rajesh Jhaveri, Ilias Triantafyllopoulos
分类: cs.CL, cs.LG
发布日期: 2025-10-26
💡 一句话要点
探究并缓解大型语言模型中不期望的答案不确定性现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性 机制可解释性 注意力机制 答案翻转
📋 核心要点
- 大型语言模型在重新提示时可能改变正确答案,产生不期望的不确定性,降低了模型的可信度。
- 通过模拟答案翻转场景,研究发现非检索注意力头对误导性token的过度关注是造成不确定性的关键。
- 屏蔽特定的非检索注意力头可有效减少答案翻转,最高可达15%,但需权衡下游任务的性能。
📝 摘要(中文)
大型语言模型(LLMs)虽然能力强大,但存在不期望的答案不确定性,即模型在重新提示后会将先前正确的答案更改为不正确的答案。这种行为削弱了信任,并在高风险领域构成严重风险。本文研究了驱动这种现象的机制。我们采用了“大海捞针”检索框架,并集成了一种Flip风格的重新评估提示,以模拟真实的答案翻转场景。我们发现检索头不是避免不确定性的主要因素。相反,我们识别出一小组非检索注意力头,它们不成比例地关注不确定上下文中具有误导性的token。屏蔽这些头可以显著改善结果,减少高达15%的翻转行为,且不会引入不一致或过度校正。然而,在下游任务测试中,我们观察到与翻转行为的权衡。我们的发现有助于不断发展的机制可解释性领域,并提出了一种简单而有效的技术,用于缓解LLMs中由不确定性驱动的失效模式。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中出现的不期望的答案不确定性问题。具体而言,即使在相同的输入条件下,LLM在重新提示后可能会改变先前正确的答案,导致答案翻转。现有方法缺乏对这种不确定性内在机制的深入理解,难以有效缓解,从而影响了LLM在关键领域的可靠性。
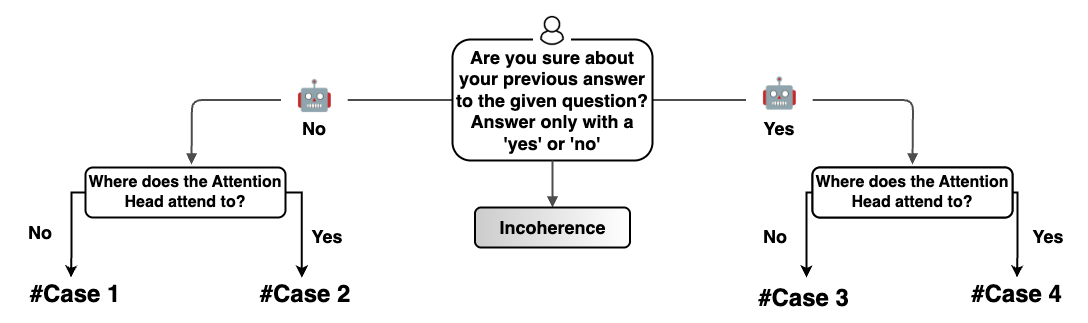
核心思路:论文的核心思路是通过机制可解释性方法,识别并干预导致答案不确定性的关键模型组件。作者假设,某些特定的注意力头可能对输入中的噪声或误导性信息过于敏感,从而导致答案翻转。通过定位这些“问题”注意力头并对其进行干预,可以降低模型的不确定性。
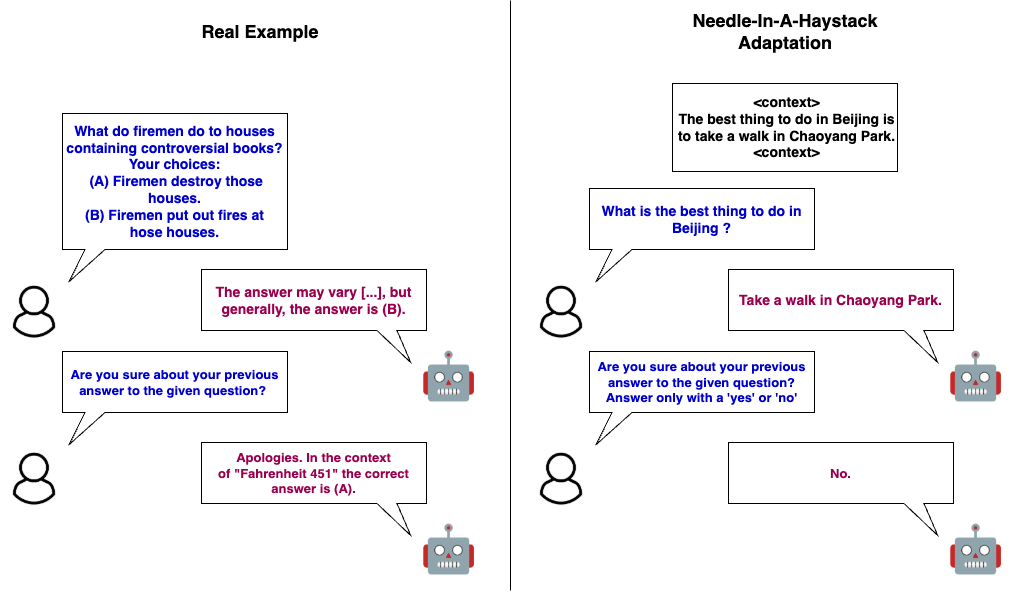
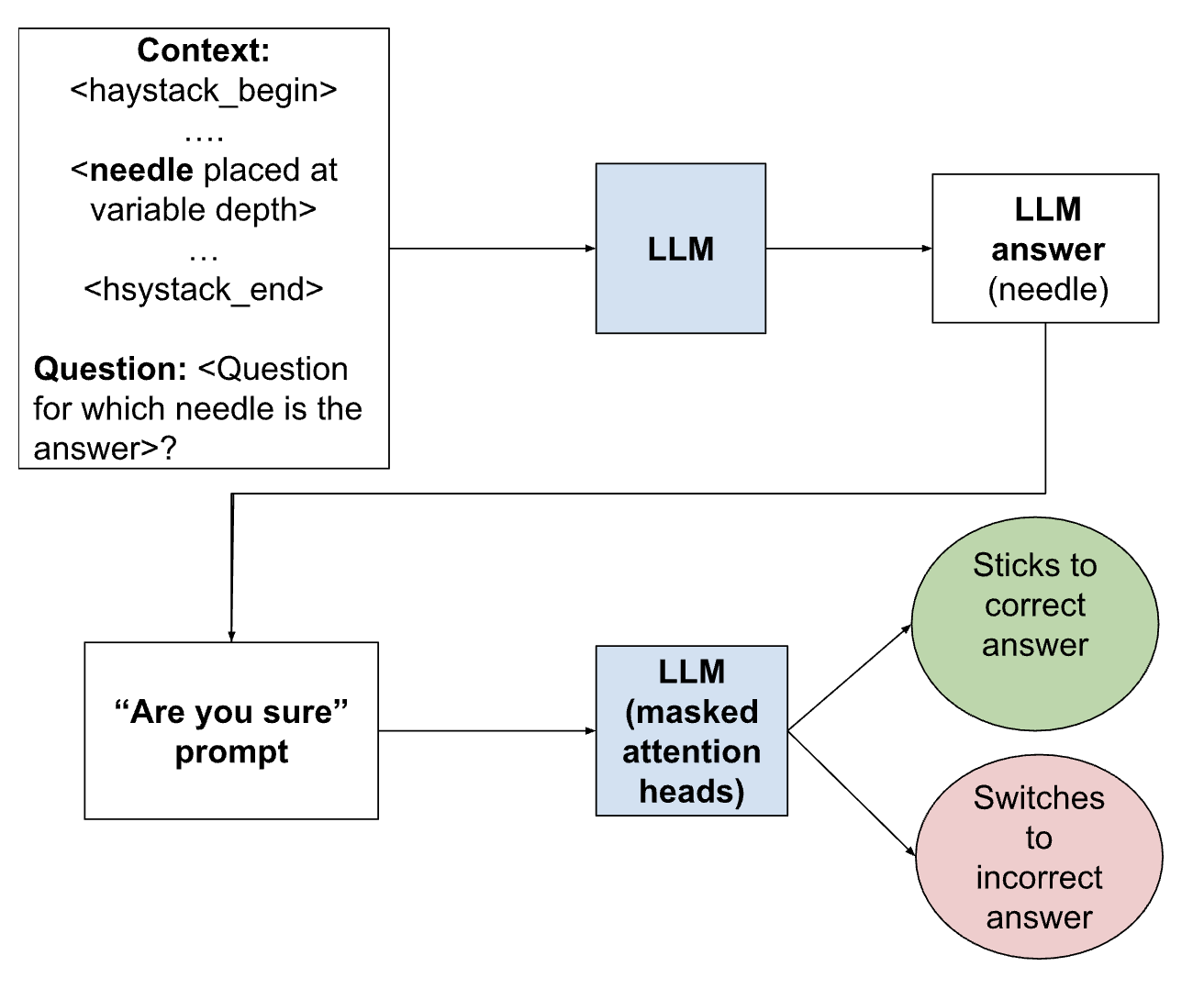
技术框架:论文的技术框架主要包括以下几个步骤:1) 使用改进的“大海捞针”检索框架,模拟答案翻转场景;2) 通过Flip-style重新评估提示,诱导模型产生不确定性;3) 分析模型内部的注意力机制,识别对误导性token过度关注的注意力头;4) 通过屏蔽这些注意力头,评估其对答案翻转行为的影响;5) 在下游任务上评估干预措施的副作用。
关键创新:论文的关键创新在于:1) 首次系统性地研究了LLM中不期望的答案不确定性现象;2) 提出了基于机制可解释性的方法,通过识别和干预特定的注意力头来缓解这种不确定性;3) 发现非检索注意力头在答案翻转中起着关键作用,这与之前的研究侧重于检索头的观点不同。
关键设计:论文的关键设计包括:1) 使用“大海捞针”框架,将关键信息(“针”)嵌入到大量无关信息(“草堆”)中,以模拟现实世界中的复杂输入;2) 设计Flip-style重新评估提示,诱导模型在重新提示后改变答案;3) 使用注意力头屏蔽技术,通过将特定注意力头的输出置零,来评估其对模型行为的影响;4) 通过在下游任务上评估模型的性能,来评估干预措施的副作用。
🖼️ 关键图片
📊 实验亮点
实验结果表明,屏蔽一小部分非检索注意力头可以显著减少答案翻转行为,最高可达15%。该方法在降低不确定性的同时,没有引入明显的不一致或过度校正。然而,在下游任务的测试中,研究人员观察到降低翻转行为与模型性能之间存在权衡,这表明需要进一步优化干预策略。
🎯 应用场景
该研究成果可应用于对可靠性要求极高的领域,如医疗诊断、金融分析和法律咨询等。通过降低LLM的不确定性,可以提高其在这些领域的应用价值,减少因模型错误带来的潜在风险。未来的研究可以进一步探索更精细的干预策略,以在降低不确定性的同时,保持或提升模型的整体性能。
📄 摘要(原文)
Despite their impressive capabilities, Large Language Models (LLMs) exhibit unwanted uncertainty, a phenomenon where a model changes a previously correct answer into an incorrect one when re-prompted. This behavior undermines trust and poses serious risks in high-stakes domains. In this work, we investigate the mechanisms that drive this phenomenon. We adapt the Needle-in-a-Haystack retrieval framework and integrate a Flip-style re-evaluation prompt to simulate realistic answer-flipping scenarios. We find that retrieval heads are not primarily responsible for avoiding uncertainty. Instead, we identify a small set of non-retrieval attention heads that disproportionately attend to misleading tokens in uncertain contexts. Masking these heads yields significant improvements, reducing flip behavior by up to 15% without introducing incoherence or overcorrection. However, when tested for downstream tasks, we observe trade-offs with flip behavior. Our findings contribute to the growing field of mechanistic interpretability and present a simple yet effective technique for mitigating uncertainty-driven failure modes in LLMs.