Once Upon an Input: Reasoning via Per-Instance Program Synthesis
作者: Adam Stein, Neelay Velingker, Mayur Naik, Eric Wong
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-26
备注: Accepted at NeurIPS 2025. 34 pages, 7 figures
💡 一句话要点
提出Per-Instance Program Synthesis (PIPS)方法,提升LLM在复杂推理任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 程序合成 大型语言模型 复杂推理 结构化反馈 实例级别优化
📋 核心要点
- 现有LLM在复杂推理任务中表现不佳,CoT和PoT等方法虽有改进,但在算法领域易产生不良解。
- PIPS方法在实例层面生成和优化程序,利用结构化反馈,无需任务指导或显式测试用例。
- 实验表明,PIPS在多个基准测试中显著提升了LLM的推理准确率,并减少了不良程序生成。
📝 摘要(中文)
大型语言模型(LLMs)在零样本推理方面表现出色,但在复杂的多步骤推理方面仍然面临挑战。诸如思维链(CoT)和程序思维(PoT)等增强LLM中间推理步骤的方法虽然提高了性能,但经常产生不良解决方案,尤其是在算法领域。本文提出了一种Per-Instance Program Synthesis(PIPS)方法,该方法在实例级别生成和改进程序,使用结构化反馈,无需依赖于特定任务的指导或显式测试用例。为了进一步提高性能,PIPS 结合了一种置信度指标,该指标在每个实例的基础上动态选择直接推理或程序合成。在三个前沿 LLM 和 30 个基准测试(包括 Big Bench Extra Hard (BBEH) 的所有任务、视觉问答任务、关系推理任务和数学推理任务)上的实验表明,与 PoT 和 CoT 相比,PIPS 将绝对调和平均准确率分别提高了高达 8.6% 和 9.4%,并且与使用 Gemini-2.0-Flash 的 PoT 相比,算法任务上不良程序生成减少了 65.1%。
🔬 方法详解
问题定义:现有的大型语言模型在复杂的多步骤推理任务中表现不足,尤其是在算法领域。即使使用思维链(CoT)或程序思维(PoT)等方法,也容易生成不理想的解决方案,缺乏可靠性和准确性。这些方法通常依赖于任务特定的指导或显式测试用例,泛化能力有限。
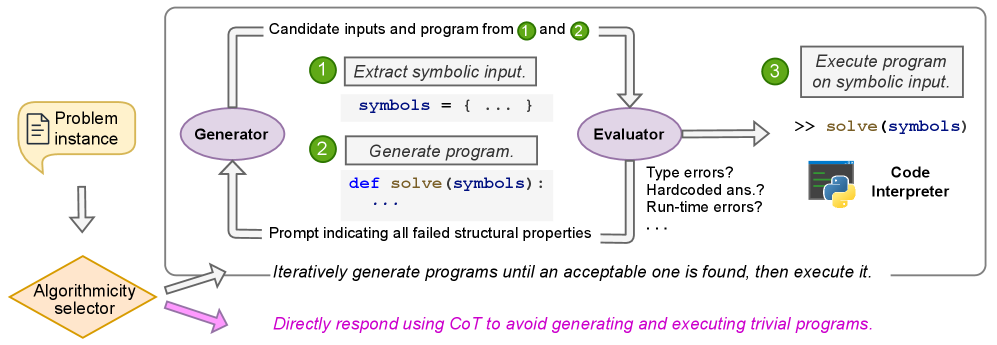
核心思路:PIPS的核心思路是在每个实例的基础上动态地生成和优化程序。它不依赖于预定义的规则或任务特定的指导,而是通过结构化的反馈来迭代改进程序。这种方法允许模型根据输入实例的特性进行自适应推理,从而提高性能和鲁棒性。
技术框架:PIPS的整体框架包括以下几个主要阶段:1) 初始程序生成:使用LLM生成针对特定输入实例的初始程序。2) 结构化反馈:分析程序的执行结果,并生成结构化的反馈信息,例如程序中的错误或低效部分。3) 程序优化:利用反馈信息,对程序进行迭代优化,例如修复错误、改进算法效率等。4) 置信度评估:评估当前程序的置信度,并决定是否继续优化或直接输出结果。5) 动态选择:基于置信度指标,动态选择使用程序合成的结果或直接推理的结果。
关键创新:PIPS最重要的创新点在于其per-instance的程序合成和优化机制。与传统的CoT或PoT方法不同,PIPS不依赖于预定义的程序模板或规则,而是根据每个输入实例的特性动态生成和优化程序。此外,PIPS还引入了置信度指标,用于动态选择程序合成或直接推理的结果,进一步提高了性能。
关键设计:PIPS的关键设计包括:1) 结构化反馈机制:如何有效地分析程序的执行结果,并生成有用的反馈信息。2) 程序优化算法:如何利用反馈信息,对程序进行迭代优化。3) 置信度评估方法:如何准确地评估程序的置信度,并用于动态选择。这些设计细节直接影响了PIPS的性能和效果。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述,但此处无法完全展开。
🖼️ 关键图片

📊 实验亮点
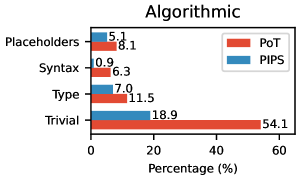
实验结果表明,PIPS在多个基准测试中显著提升了LLM的推理性能。例如,在Big Bench Extra Hard (BBEH) 的所有任务中,PIPS 的绝对调和平均准确率比 PoT 和 CoT 分别提高了高达 8.6% 和 9.4%。此外,与使用 Gemini-2.0-Flash 的 PoT 相比,PIPS 在算法任务上不良程序生成减少了 65.1%。这些结果表明,PIPS 是一种有效的复杂推理方法。
🎯 应用场景
PIPS方法具有广泛的应用前景,可以应用于各种需要复杂推理的任务,例如:算法问题求解、数学推理、视觉问答、关系推理等。该方法可以提高LLM在这些任务中的性能和可靠性,使其能够更好地解决实际问题。未来,PIPS还可以应用于机器人控制、自动驾驶等领域,实现更智能化的决策和控制。
📄 摘要(原文)
Large language models (LLMs) excel at zero-shot inference but continue to struggle with complex, multi-step reasoning. Recent methods that augment LLMs with intermediate reasoning steps such as Chain of Thought (CoT) and Program of Thought (PoT) improve performance but often produce undesirable solutions, especially in algorithmic domains. We introduce Per-Instance Program Synthesis (PIPS), a method that generates and refines programs at the instance-level using structural feedback without relying on task-specific guidance or explicit test cases. To further improve performance, PIPS incorporates a confidence metric that dynamically chooses between direct inference and program synthesis on a per-instance basis. Experiments across three frontier LLMs and 30 benchmarks including all tasks of Big Bench Extra Hard (BBEH), visual question answering tasks, relational reasoning tasks, and mathematical reasoning tasks show that PIPS improves the absolute harmonic mean accuracy by up to 8.6% and 9.4% compared to PoT and CoT respectively, and reduces undesirable program generations by 65.1% on the algorithmic tasks compared to PoT with Gemini-2.0-Flash.