Leveraging Large Language Models to Identify Conversation Threads in Collaborative Learning
作者: Prerna Ravi, Dong Won Lee, Beatriz Flamia, Jasmine David, Brandon Hanks, Cynthia Breazeal, Emma Anderson, Grace Lin
分类: cs.CL
发布日期: 2025-10-26
备注: In Submission: Journal of Educational Data Mining (jEDM) 2026
💡 一句话要点
利用大型语言模型识别协作学习中的对话主题,提升会话分析性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对话主题识别 协作学习 会话分析 自然语言处理
📋 核心要点
- 同步口语对话中,由于发言重叠和隐式线索,难以准确识别对话主题,这阻碍了协作学习分析。
- 论文提出一种利用大型语言模型(LLM)并结合显式对话主题链接的方法,以改善会话分析的编码性能。
- 实验结果表明,提供清晰的对话主题信息能够显著提高LLM的编码性能,并提升下游分析的准确性。
📝 摘要(中文)
理解小组对话中思想的发展和流动对于分析协作学习至关重要。对话主题是这些互动的一个关键结构特征,它指的是话语自然地组织成相互交织的、随时间演变的主题线索。虽然对话主题在异步文本环境中得到了广泛研究,但由于重叠的发言和隐含的线索,检测同步口语对话中的主题仍然具有挑战性。同时,大型语言模型(LLM)在自动化话语分析方面显示出潜力,但通常难以处理依赖于追踪这些会话链接的长上下文任务。在本文中,我们研究了显式的对话主题链接是否可以改善基于LLM的群体对话关系行为编码。我们贡献了一个系统的指南,用于识别同步多人对话文本中的主题,并对不同的LLM提示策略进行基准测试,以实现自动主题识别。然后,我们测试了主题识别如何影响会话分析框架的下游编码性能,该框架捕捉了核心协作行为,如同意、构建和启发。我们的结果表明,提供清晰的对话主题信息可以提高LLM的编码性能,并强调了下游分析对结构良好的对话的严重依赖。我们还讨论了时间和成本方面的实际权衡,强调了人机混合方法可以在哪里产生最佳价值。总之,这项工作推进了结合LLM和强大的会话主题结构的方法,以理解复杂的、实时的群体互动。
🔬 方法详解
问题定义:论文旨在解决在同步多人对话中,难以准确识别和追踪对话主题的问题。现有方法在处理口语对话的复杂性(如发言重叠、隐式线索)时表现不佳,导致对话分析的准确性受限。大型语言模型虽然具备潜力,但在长上下文和依赖会话链接的任务中面临挑战。
核心思路:论文的核心思路是利用显式的对话主题链接来辅助大型语言模型(LLM)进行会话分析。通过明确地标注和提供对话主题信息,可以帮助LLM更好地理解对话的上下文和逻辑关系,从而提高编码的准确性。这种方法旨在弥补LLM在处理长上下文和复杂对话结构方面的不足。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 开发一套系统的指南,用于识别同步多人对话文本中的对话主题。2) 设计不同的LLM提示策略,并进行基准测试,以评估其在自动对话主题识别方面的性能。3) 将对话主题信息作为输入,用于LLM进行下游的会话分析编码任务,例如识别协作行为(同意、构建、启发等)。4) 评估提供对话主题信息对LLM编码性能的影响。
关键创新:论文的关键创新在于将显式的对话主题链接引入到基于LLM的会话分析中。与以往直接使用LLM进行编码的方法不同,该研究强调了对话结构的重要性,并通过提供清晰的对话主题信息来增强LLM的理解能力。这种方法能够更有效地利用LLM的潜力,并提高会话分析的准确性。
关键设计:论文的关键设计包括:1) 详细的对话主题识别指南,确保标注的一致性和准确性。2) 多种LLM提示策略,探索最佳的对话主题信息输入方式。3) 使用会话分析框架(例如,识别协作行为)作为下游任务,评估对话主题信息对实际应用的影响。具体的参数设置、损失函数和网络结构等技术细节在论文中未明确提及,属于未知信息。
🖼️ 关键图片
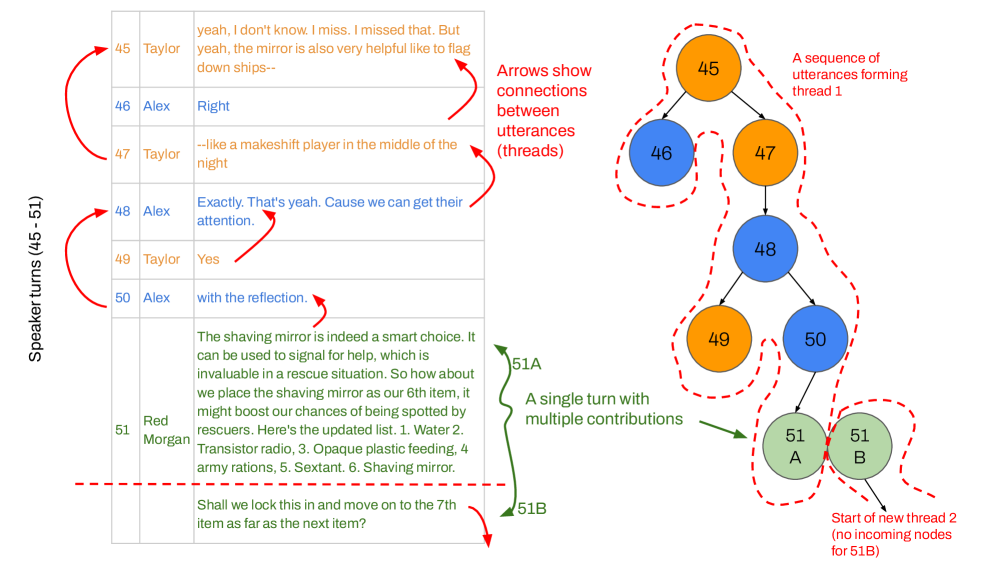

📊 实验亮点
实验结果表明,提供清晰的对话主题信息能够显著提高LLM的编码性能。具体而言,在会话分析框架的下游编码任务中,LLM在识别协作行为(如同意、构建和启发)方面的准确性得到了提升。论文还强调了人机混合方法在时间和成本方面的优势,表明通过结合人工标注和LLM自动分析,可以实现最佳的会话分析效果。
🎯 应用场景
该研究成果可应用于在线教育、团队协作、客户服务等领域。通过自动识别和分析对话主题,可以更好地理解学习过程、优化团队沟通、提升客户满意度。未来,该技术有望应用于更广泛的人机交互场景,例如智能助手、虚拟会议等。
📄 摘要(原文)
Understanding how ideas develop and flow in small-group conversations is critical for analyzing collaborative learning. A key structural feature of these interactions is threading, the way discourse talk naturally organizes into interwoven topical strands that evolve over time. While threading has been widely studied in asynchronous text settings, detecting threads in synchronous spoken dialogue remains challenging due to overlapping turns and implicit cues. At the same time, large language models (LLMs) show promise for automating discourse analysis but often struggle with long-context tasks that depend on tracing these conversational links. In this paper, we investigate whether explicit thread linkages can improve LLM-based coding of relational moves in group talk. We contribute a systematic guidebook for identifying threads in synchronous multi-party transcripts and benchmark different LLM prompting strategies for automated threading. We then test how threading influences performance on downstream coding of conversational analysis frameworks, that capture core collaborative actions such as agreeing, building, and eliciting. Our results show that providing clear conversational thread information improves LLM coding performance and underscores the heavy reliance of downstream analysis on well-structured dialogue. We also discuss practical trade-offs in time and cost, emphasizing where human-AI hybrid approaches can yield the best value. Together, this work advances methods for combining LLMs and robust conversational thread structures to make sense of complex, real-time group interactions.