Cross-Lingual Stability and Bias in Instruction-Tuned Language Models for Humanitarian NLP
作者: Poli Nemkova, Amrit Adhikari, Matthew Pearson, Vamsi Krishna Sadu, Mark V. Albert
分类: cs.CL, cs.AI
发布日期: 2025-10-26
💡 一句话要点
针对人道主义NLP,评估指令调优语言模型在跨语言稳定性与偏差上的表现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言自然语言处理 人权监测 大型语言模型 跨语言稳定性 指令调优 低资源语言 校准偏差
📋 核心要点
- 现有方法在低资源语言的人权监测中缺乏充分验证,开源LLM的跨语言可靠性未知。
- 通过系统比较商业和开源LLM,量化成本与跨语言可靠性的权衡,揭示模型稳定性的决定因素。
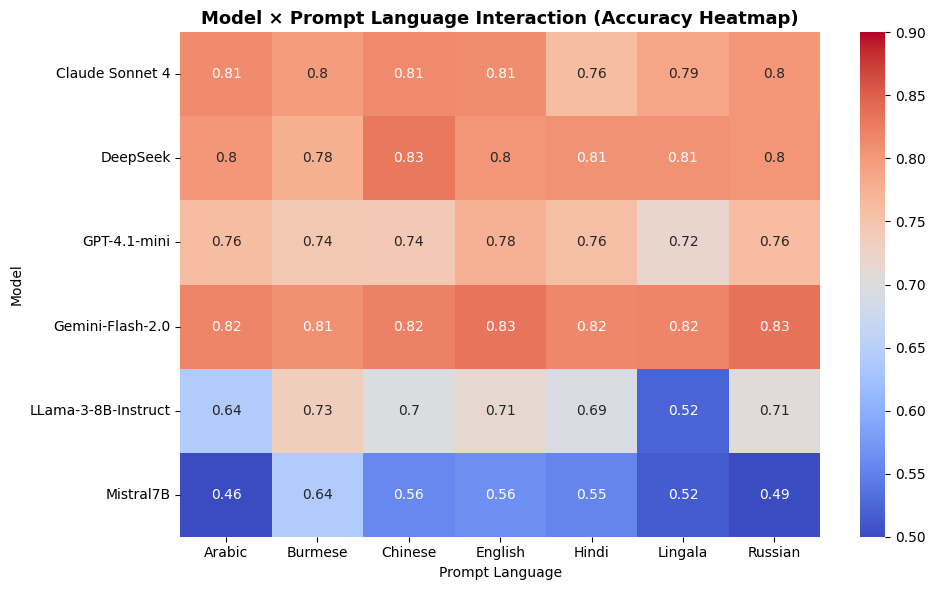
- 实验表明,指令对齐而非模型规模是跨语言稳定性的关键,对齐模型在低资源语言中表现更佳。
📝 摘要(中文)
人道主义组织面临关键选择:投资昂贵的商业API,还是依赖免费的开源模型进行多语言人权监测。虽然商业系统提供可靠性,但开源替代方案缺乏实证验证,尤其是在冲突地区常见的低资源语言方面。本文首次系统地比较了商业和开源大型语言模型(LLM)在七种语言的人权侵犯检测方面的表现,量化了资源受限组织面临的成本-可靠性权衡。通过78,000次多语言推断,我们评估了六个模型——四个指令对齐模型(Claude-Sonnet-4、DeepSeek-V3、Gemini-Flash-2.0、GPT-4.1-mini)和两个开源模型(LLaMA-3-8B、Mistral-7B)——使用标准分类指标和新的跨语言可靠性指标:校准偏差(CD)、决策偏差(B)、语言鲁棒性得分(LRS)和语言稳定性得分(LSS)。结果表明,对齐而非规模决定了稳定性:对齐模型在类型学上遥远且低资源的语言(例如,林加拉语、缅甸语)中保持近乎不变的准确性和平衡的校准,而开源模型表现出显着的提示语言敏感性和校准漂移。这些发现表明,多语言对齐能够实现语言无关的推理,并为在多语言部署中平衡预算限制与可靠性的人道主义组织提供实用指导。
🔬 方法详解
问题定义:论文旨在解决人道主义组织在多语言人权监测中,如何选择合适的语言模型的问题。现有方法要么依赖昂贵的商业API,要么使用未经充分验证的开源模型,尤其是在低资源语言环境下,开源模型的可靠性存在疑问。因此,论文要解决的核心问题是:如何在成本约束下,选择具有良好跨语言稳定性和低偏差的语言模型,以确保人权监测的准确性和可靠性。
核心思路:论文的核心思路是通过系统性的实验评估,比较商业和开源LLM在多语言环境下的性能,并引入新的跨语言可靠性指标,量化模型的稳定性和偏差。通过分析实验结果,揭示影响模型稳定性的关键因素,为资源受限的人道主义组织提供选择模型的指导。
技术框架:论文的技术框架主要包括以下几个部分:1)构建多语言人权侵犯检测数据集,涵盖七种语言。2)选择六个具有代表性的LLM进行评估,包括四个指令对齐模型和两个开源模型。3)使用标准分类指标(如准确率、F1值)评估模型的性能。4)引入新的跨语言可靠性指标,包括校准偏差(CD)、决策偏差(B)、语言鲁棒性得分(LRS)和语言稳定性得分(LSS),用于评估模型的稳定性和偏差。5)分析实验结果,比较不同模型的性能,并揭示影响模型稳定性的关键因素。
关键创新:论文最重要的技术创新点在于提出了新的跨语言可靠性指标,用于量化LLM在多语言环境下的稳定性和偏差。这些指标能够更全面地评估模型的性能,弥补了传统分类指标的不足。此外,论文还首次系统地比较了商业和开源LLM在人权侵犯检测任务中的表现,为该领域的研究提供了重要的参考。
关键设计:论文的关键设计包括:1)选择具有代表性的LLM,涵盖商业和开源模型,以及不同规模的模型。2)构建高质量的多语言数据集,确保数据集的平衡性和代表性。3)设计合理的实验方案,控制实验变量,确保实验结果的可靠性。4)使用多种评估指标,包括标准分类指标和新的跨语言可靠性指标,全面评估模型的性能。具体的参数设置、损失函数、网络结构等技术细节取决于所使用的LLM,论文主要关注模型的整体性能和跨语言稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,指令对齐是影响LLM跨语言稳定性的关键因素。对齐模型(如Claude-Sonnet-4)在低资源语言(如林加拉语、缅甸语)中保持了近乎不变的准确性和平衡的校准,而开源模型(如LLaMA-3-8B、Mistral-7B)表现出显著的提示语言敏感性和校准漂移。这表明,多语言对齐能够提升模型的语言无关推理能力。
🎯 应用场景
该研究成果可直接应用于人道主义援助和人权监测领域,帮助相关组织在资源有限的情况下,选择合适的语言模型进行多语言信息处理和分析。通过选择具有良好跨语言稳定性和低偏差的模型,可以提高人权监测的准确性和可靠性,从而更好地保护弱势群体的权益。此外,该研究也为多语言自然语言处理领域的研究提供了新的思路和方法。
📄 摘要(原文)
Humanitarian organizations face a critical choice: invest in costly commercial APIs or rely on free open-weight models for multilingual human rights monitoring. While commercial systems offer reliability, open-weight alternatives lack empirical validation -- especially for low-resource languages common in conflict zones. This paper presents the first systematic comparison of commercial and open-weight large language models (LLMs) for human-rights-violation detection across seven languages, quantifying the cost-reliability trade-off facing resource-constrained organizations. Across 78,000 multilingual inferences, we evaluate six models -- four instruction-aligned (Claude-Sonnet-4, DeepSeek-V3, Gemini-Flash-2.0, GPT-4.1-mini) and two open-weight (LLaMA-3-8B, Mistral-7B) -- using both standard classification metrics and new measures of cross-lingual reliability: Calibration Deviation (CD), Decision Bias (B), Language Robustness Score (LRS), and Language Stability Score (LSS). Results show that alignment, not scale, determines stability: aligned models maintain near-invariant accuracy and balanced calibration across typologically distant and low-resource languages (e.g., Lingala, Burmese), while open-weight models exhibit significant prompt-language sensitivity and calibration drift. These findings demonstrate that multilingual alignment enables language-agnostic reasoning and provide practical guidance for humanitarian organizations balancing budget constraints with reliability in multilingual deployment.