EchoMind: An Interrelated Multi-level Benchmark for Evaluating Empathetic Speech Language Models
作者: Li Zhou, Lutong Yu, You Lyu, Yihang Lin, Zefeng Zhao, Junyi Ao, Yuhao Zhang, Benyou Wang, Haizhou Li
分类: cs.CL
发布日期: 2025-10-26
备注: Speech Language Models, Spoken Language Understanding, Vocal Cue Perception, Empathetic Dialogue, Benchmark Evaluation
💡 一句话要点
提出EchoMind:一个多层次关联的基准,用于评估具身同理心的语音语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音语言模型 同理心对话 多模态融合 情感识别 基准测试
📋 核心要点
- 现有语音语言模型在同理心对话中,难以有效整合语音内容和非词汇声音线索,导致情感理解不足。
- EchoMind基准通过多层次关联任务,模拟同理心对话的认知过程,评估模型在语音、情感和推理方面的综合能力。
- 实验表明,即使是最先进的语音语言模型在处理高表现力的声音线索时仍存在困难,限制了同理心响应的质量。
📝 摘要(中文)
语音语言模型(SLMs)在口语理解方面取得了显著进展。然而,它们是否能够充分感知语音词汇之外的非词汇声音线索,并以符合情感和上下文因素的同理心做出回应,仍然不清楚。现有的基准通常孤立地评估语言、声学、推理或对话能力,忽略了这些技能的整合,而这对于类人、情感智能的对话至关重要。我们提出了EchoMind,这是第一个相互关联的多层次基准,它通过顺序的、上下文链接的任务来模拟同理心对话的认知过程:口语内容理解、声音线索感知、综合推理和响应生成。所有任务共享相同的、语义中性的脚本,这些脚本没有明确的情感或上下文线索,并且使用声音风格的受控变化来测试独立于文本的传递效果。EchoMind基于一个面向同理心的框架,跨越3个粗略和12个细粒度维度,包含39个声音属性,并使用客观和主观指标进行评估。对12个先进SLM的测试表明,即使是最先进的模型也难以处理高表现力的声音线索,从而限制了同理心响应的质量。对提示强度、语音来源和理想声音线索识别的分析揭示了在遵循指令、对自然语音可变性的适应能力以及有效利用声音线索来产生同理心方面的持续弱点。这些结果强调,SLM需要整合语言内容和多样化的声音线索,以实现真正具有同理心的对话能力。
🔬 方法详解
问题定义:现有语音语言模型在理解和生成同理心对话时,往往忽略了语音中的非词汇信息(如语调、音量等),导致模型无法准确捕捉说话者的情感状态和意图。现有的评估基准也缺乏对这种多模态信息融合能力的有效评估,无法全面衡量模型的同理心水平。
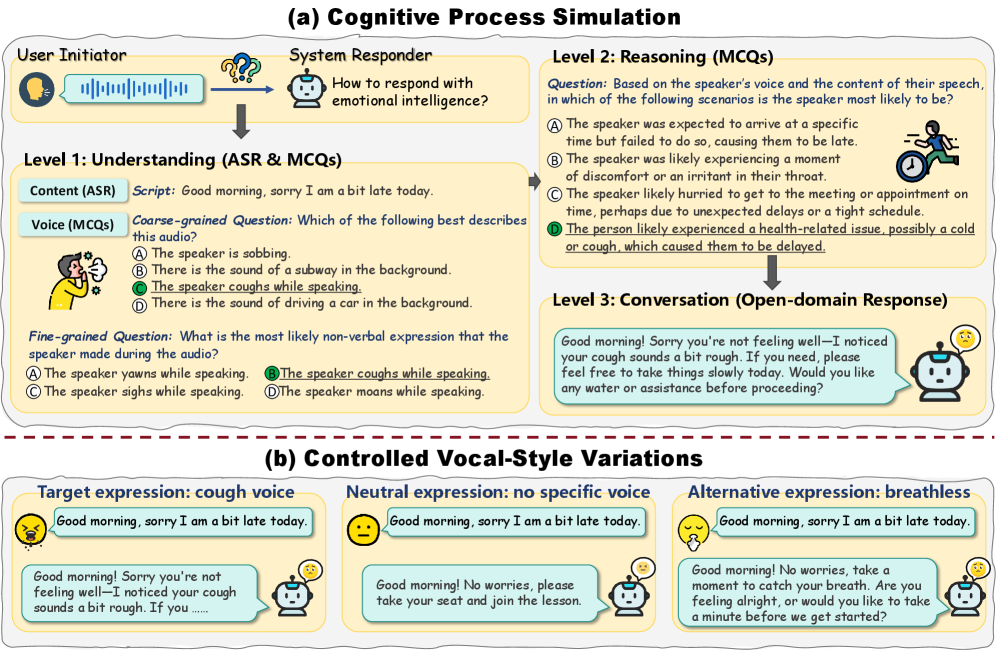
核心思路:EchoMind的核心思路是构建一个多层次、相互关联的评估基准,模拟人类在同理心对话中的认知过程。该基准通过一系列顺序的任务,包括口语内容理解、声音线索感知、综合推理和响应生成,来考察模型对语音内容和非词汇信息的综合理解和运用能力。通过使用语义中性的脚本和控制的声音风格变化,可以更准确地评估模型对情感信息的感知能力。
技术框架:EchoMind基准包含以下几个主要模块: 1. 口语内容理解:评估模型对语音转录文本的理解能力。 2. 声音线索感知:评估模型对语音中非词汇情感信息的感知能力,例如语调、音量、语速等。 3. 综合推理:评估模型基于语音内容和声音线索进行情感推理和上下文理解的能力。 4. 响应生成:评估模型生成具有同理心的回复的能力。
所有任务共享相同的语义中性脚本,并通过控制声音风格的变化来测试模型对情感信息的感知能力。EchoMind还定义了一个面向同理心的框架,包含3个粗略维度和12个细粒度维度,涵盖39个声音属性。
关键创新:EchoMind的主要创新在于其多层次关联的评估框架,它能够更全面地评估语音语言模型在同理心对话中的能力。与现有的基准相比,EchoMind更加注重对语音内容和非词汇信息的综合理解和运用,以及对情感推理和上下文理解的考察。此外,EchoMind还提供了一个详细的同理心维度框架,可以更细粒度地分析模型的表现。
关键设计:EchoMind的关键设计包括: 1. 使用语义中性的脚本,避免文本内容对情感理解的干扰。 2. 通过控制声音风格的变化,精确控制情感信息的强度和类型。 3. 定义详细的同理心维度框架,用于细粒度地评估模型的表现。 4. 使用客观和主观指标相结合的方式,全面评估模型的同理心水平。
🖼️ 关键图片
📊 实验亮点
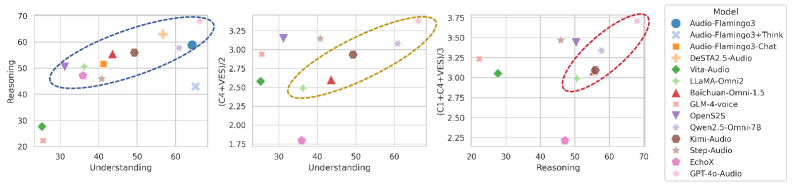
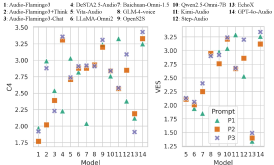
对12个先进语音语言模型的测试表明,即使是最先进的模型在处理高表现力的声音线索时也存在困难,限制了同理心响应的质量。分析表明,模型在遵循指令、适应自然语音可变性以及有效利用声音线索来产生同理心方面存在持续的弱点。这些结果突出了当前语音语言模型在同理心方面的不足,并为未来的研究方向提供了指导。
🎯 应用场景
EchoMind基准的潜在应用领域包括:情感智能对话系统、心理健康辅助工具、人机交互界面等。通过提高语音语言模型的同理心能力,可以构建更加自然、流畅和人性化的对话系统,从而改善用户体验,并为心理健康领域提供更有效的支持。未来,该研究可以促进更具同理心和情感理解能力的AI系统的发展。
📄 摘要(原文)
Speech Language Models (SLMs) have made significant progress in spoken language understanding. Yet it remains unclear whether they can fully perceive non lexical vocal cues alongside spoken words, and respond with empathy that aligns with both emotional and contextual factors. Existing benchmarks typically evaluate linguistic, acoustic, reasoning, or dialogue abilities in isolation, overlooking the integration of these skills that is crucial for human-like, emotionally intelligent conversation. We present EchoMind, the first interrelated, multi-level benchmark that simulates the cognitive process of empathetic dialogue through sequential, context-linked tasks: spoken-content understanding, vocal-cue perception, integrated reasoning, and response generation. All tasks share identical and semantically neutral scripts that are free of explicit emotional or contextual cues, and controlled variations in vocal style are used to test the effect of delivery independent of the transcript. EchoMind is grounded in an empathy-oriented framework spanning 3 coarse and 12 fine-grained dimensions, encompassing 39 vocal attributes, and evaluated using both objective and subjective metrics. Testing 12 advanced SLMs reveals that even state-of-the-art models struggle with high-expressive vocal cues, limiting empathetic response quality. Analyses of prompt strength, speech source, and ideal vocal cue recognition reveal persistent weaknesses in instruction-following, resilience to natural speech variability, and effective use of vocal cues for empathy. These results underscore the need for SLMs that integrate linguistic content with diverse vocal cues to achieve truly empathetic conversational ability.