Beyond Semantics: How Temporal Biases Shape Retrieval in Transformer and State-Space Models
作者: Anooshka Bajaj, Deven Mahesh Mistry, Sahaj Singh Maini, Yash Aggarwal, Zoran Tiganj
分类: cs.CL, cs.AI
发布日期: 2025-10-26
💡 一句话要点
研究Transformer和状态空间模型中的时间偏差对上下文学习检索的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 时间偏差 Transformer 状态空间模型 情景记忆 语言模型 归纳头
📋 核心要点
- 现有LLM的上下文学习受时间关系和语义关系共同影响,但时间关系的影响机制尚不明确。
- 通过设计特定序列,隔离时间因素,研究Transformer和状态空间模型在检索时间分离事件时的偏差。
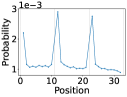
- 实验发现模型对序列开头和结尾附近的token存在时间偏差,且Transformer中的归纳头与此现象相关。
📝 摘要(中文)
本文研究了上下文学习中时间关系和语义关系如何影响大型语言模型(LLM)检索上下文信息。类似于人类情景记忆,通过区分不同时间发生的事件来检索特定事件,本文探讨了包括Transformer和状态空间模型在内的各种预训练LLM区分和检索时间上分离的事件的能力。具体来说,本文使用包含同一token多次出现的序列来提示模型,该token在序列末尾重新出现。通过固定这些重复token的位置并置换所有其他token,消除了语义混淆,并隔离了时间效应对下一个token预测的影响。结果表明,模型始终将最高概率分配给重复token之后的token,但对输入序列的开头或结尾附近的token存在明显的偏差。消融实验表明,Transformer中的这种现象与归纳头有关。进一步分析具有部分重叠的独特语义上下文,表明嵌入在提示中间的记忆不太可靠。尽管架构不同,状态空间模型和Transformer模型表现出相当的时间偏差。这些发现加深了对上下文学习中时间偏差的理解,并说明了这些偏差如何实现时间分离和情景检索。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在上下文学习中,时间信息如何影响模型的检索行为。现有方法主要关注语义关系,而忽略了时间关系的影响。论文通过控制语义信息,着重分析时间偏差对模型性能的影响。现有方法缺乏对时间偏差的深入理解,可能导致模型在处理时序相关任务时表现不佳。
核心思路:论文的核心思路是通过设计特定的输入序列,消除语义混淆,从而隔离时间因素对模型预测的影响。具体来说,论文使用包含重复token的序列,并固定重复token的位置,然后随机排列其他token,以此来观察模型对不同时间位置的token的偏好。这种方法能够有效地将时间信息从语义信息中分离出来,从而更好地研究时间偏差。
技术框架:论文的技术框架主要包括以下几个步骤:1) 构建包含重复token的输入序列;2) 使用Transformer和状态空间模型对序列进行预测;3) 分析模型对不同位置token的预测概率;4) 进行消融实验,探究时间偏差的来源。整体流程简单清晰,易于复现。
关键创新:论文的关键创新在于其研究方法,即通过控制语义信息来隔离时间信息,从而能够更清晰地观察时间偏差对模型的影响。此外,论文还发现Transformer中的归纳头与时间偏差有关,这为理解Transformer的工作机制提供了新的视角。
关键设计:论文的关键设计包括:1) 使用重复token来标记时间位置;2) 通过随机排列其他token来消除语义混淆;3) 使用下一个token预测任务来评估模型对不同时间位置token的偏好;4) 通过消融实验来探究时间偏差的来源。这些设计使得论文能够有效地研究时间偏差对模型的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Transformer和状态空间模型都表现出明显的时间偏差,即模型更倾向于预测序列开头和结尾附近的token。消融实验表明,Transformer中的归纳头与这种时间偏差有关。此外,研究还发现,嵌入在提示中间的记忆不如开头和结尾的记忆可靠。
🎯 应用场景
该研究成果可应用于提升LLM在时序数据处理方面的能力,例如时间序列预测、事件顺序推理等。通过理解和缓解时间偏差,可以提高模型在需要区分时间信息的任务中的性能。此外,该研究也为设计更有效的情景记忆模型提供了新的思路。
📄 摘要(原文)
In-context learning is governed by both temporal and semantic relationships, shaping how Large Language Models (LLMs) retrieve contextual information. Analogous to human episodic memory, where the retrieval of specific events is enabled by separating events that happened at different times, this work probes the ability of various pretrained LLMs, including transformer and state-space models, to differentiate and retrieve temporally separated events. Specifically, we prompted models with sequences containing multiple presentations of the same token, which reappears at the sequence end. By fixing the positions of these repeated tokens and permuting all others, we removed semantic confounds and isolated temporal effects on next-token prediction. Across diverse sequences, models consistently placed the highest probabilities on tokens following a repeated token, but with a notable bias for those nearest the beginning or end of the input. An ablation experiment linked this phenomenon in transformers to induction heads. Extending the analysis to unique semantic contexts with partial overlap further demonstrated that memories embedded in the middle of a prompt are retrieved less reliably. Despite architectural differences, state-space and transformer models showed comparable temporal biases. Our findings deepen the understanding of temporal biases in in-context learning and offer an illustration of how these biases can enable temporal separation and episodic retrieval.