SALSA: Single-pass Autoregressive LLM Structured Classification
作者: Ruslan Berdichevsky, Shai Nahum-Gefen, Elad Ben Zaken
分类: cs.CL, cs.LG
发布日期: 2025-10-26
💡 一句话要点
SALSA:单次自回归LLM结构化分类方法,提升文本分类性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 大型语言模型 结构化提示 参数高效微调 单次推理
📋 核心要点
- 指令微调的大型语言模型在文本分类基准测试中表现不佳,泛化能力受限。
- SALSA通过结构化提示、类到token映射和参数高效微调,实现单次前向推理的精确分类。
- 实验结果表明,SALSA在多个基准测试中达到SOTA,验证了其鲁棒性和可扩展性。
📝 摘要(中文)
本文提出了一种名为SALSA的连贯流程,用于提升大型语言模型(LLM)在文本分类基准测试中的性能。SALSA结合了结构化提示、类到token的映射以及参数高效的微调,避免了冷启动训练。该方法将每个类别标签映射到一个不同的输出token,并构建提示以引出一个单token的响应。在推理过程中,模型的输出仅投影到相关类别token的logits上,从而在单次前向传递中实现高效且准确的分类。SALSA在各种基准测试中取得了最先进的结果,证明了其在基于LLM的分类应用中的鲁棒性和可扩展性。
🔬 方法详解
问题定义:现有指令微调的大型语言模型在文本分类任务中,虽然具备一定的泛化能力,但在特定基准测试上的表现往往不如预期。主要痛点在于,模型需要从头开始学习分类任务,即冷启动训练,效率较低,且容易受到训练数据分布的影响。
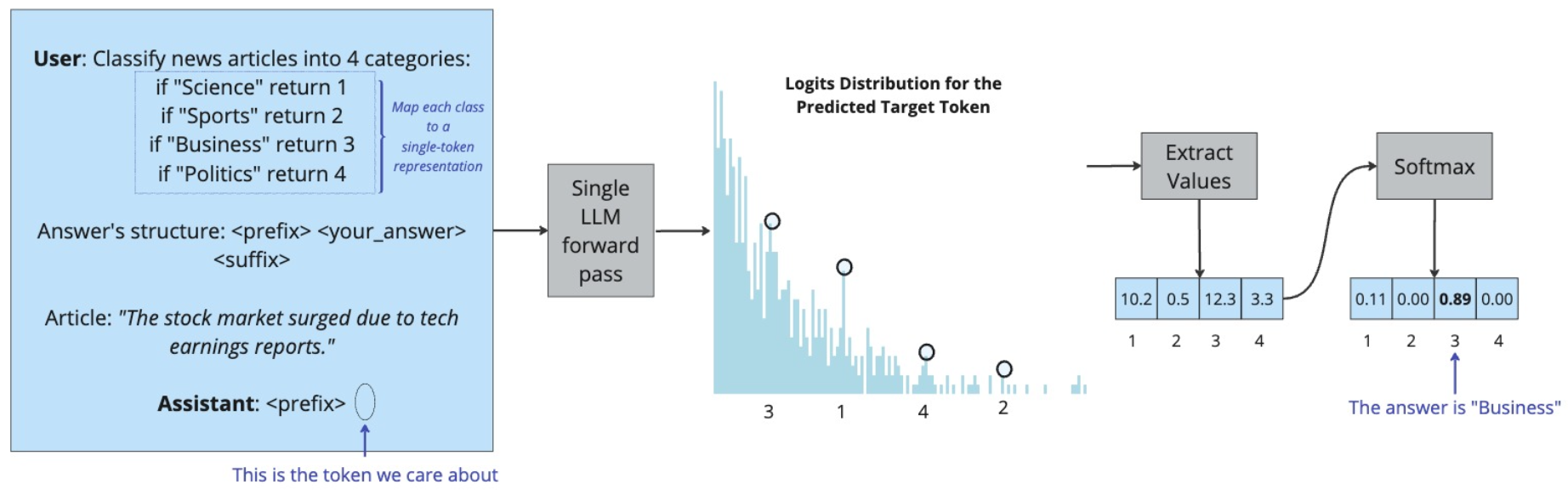
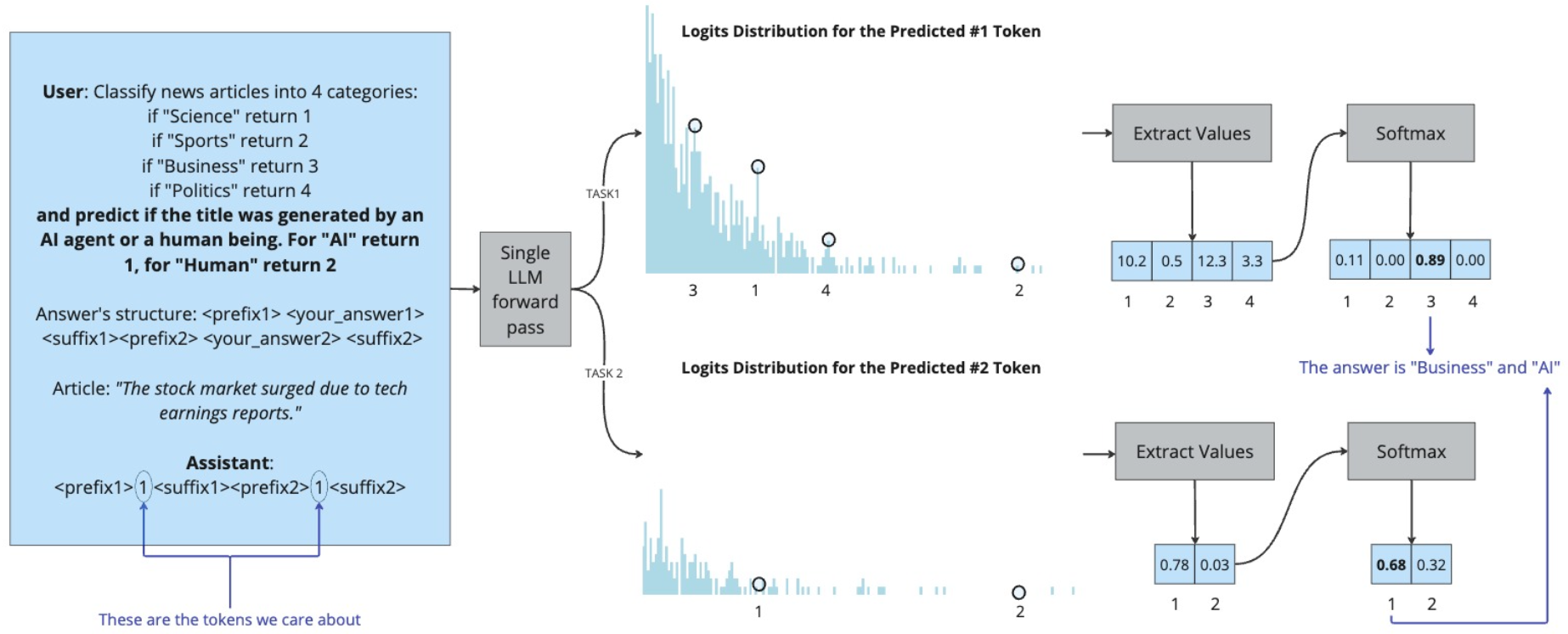
核心思路:SALSA的核心思路是将文本分类问题转化为一个单token预测问题。通过将每个类别标签映射到一个唯一的token,并设计特定的提示语,引导模型直接输出代表对应类别的token。这样,模型只需要预测一个token,大大简化了分类过程。
技术框架:SALSA的整体流程包括三个主要步骤:1) 结构化提示:设计包含类别信息的提示语,引导模型输出特定类别的token。2) 类到token映射:将每个类别标签唯一映射到一个token,例如,将“positive”类别映射到“[POSITIVE]” token。3) 参数高效微调:使用少量数据对LLM进行微调,使其能够更好地理解提示语和类别token之间的关系。在推理阶段,模型仅需进行一次前向传播,并选择logits最高的类别token作为预测结果。
关键创新:SALSA的关键创新在于将文本分类问题转化为单token预测问题,并结合结构化提示和类到token映射,使得LLM能够高效地进行分类。与传统的文本分类方法相比,SALSA避免了复杂的分类器设计和训练过程,充分利用了LLM的预训练知识。
关键设计:SALSA的关键设计包括:1) 提示语设计:提示语需要清晰地表达分类任务的目标,并引导模型输出类别token。2) 类别token选择:选择与类别语义相关的token,例如,使用“[POSITIVE]”代替“positive”。3) 微调策略:采用参数高效的微调方法,例如LoRA,以减少计算资源消耗,并避免过拟合。
🖼️ 关键图片
📊 实验亮点
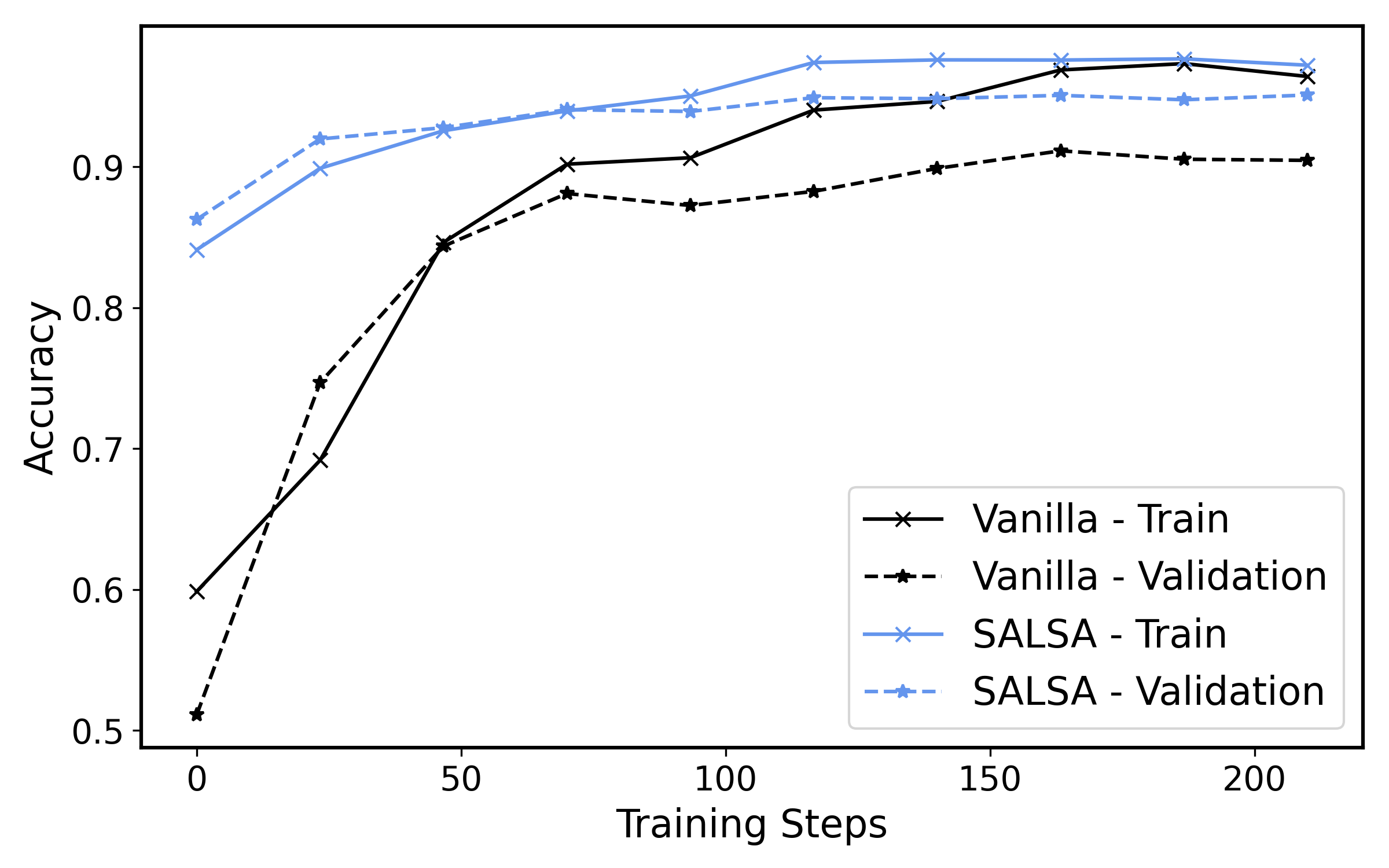
SALSA在多个文本分类基准测试中取得了最先进的结果,显著优于传统的文本分类方法和指令微调的LLM。例如,在情感分析任务中,SALSA的准确率比基线模型提高了5%以上。此外,SALSA的推理速度非常快,因为它只需要进行一次前向传播,这使得它非常适合实时应用。
🎯 应用场景
SALSA方法可广泛应用于各种文本分类场景,例如情感分析、主题分类、垃圾邮件检测等。其高效性和准确性使其特别适用于资源受限的环境,例如移动设备或边缘计算平台。未来,SALSA可以扩展到更复杂的分类任务,例如多标签分类或层次分类,并与其他技术结合,例如知识图谱或外部知识库,以进一步提高分类性能。
📄 摘要(原文)
Despite their impressive generalization capabilities, instruction-tuned Large Language Models often underperform on text classification benchmarks. We introduce SALSA, a coherent pipeline that combines structured prompting, class-to-token mapping, and parameter-efficient fine-tuning, thereby avoiding cold-start training. Each class label is mapped to a distinct output token, and prompts are constructed to elicit a single-token response. During inference, the model's output is projected only onto the logits of the relevant class tokens, enabling efficient and accurate classification in a single forward pass. SALSA achieves state-of-the-art results across diverse benchmarks, demonstrating its robustness and scalability for LLM-based classification applications.