Rule-Based Explanations for Retrieval-Augmented LLM Systems
作者: Joel Rorseth, Parke Godfrey, Lukasz Golab, Divesh Srivastava, Jarek Szlichta
分类: cs.CL
发布日期: 2025-10-26
💡 一句话要点
提出基于规则的解释方法,用于增强检索的大语言模型系统,提升可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 检索增强生成 可解释性 规则学习 Apriori剪枝
📋 核心要点
- 现有方法缺乏对RAG-LLM系统输出结果来源的有效解释,难以理解模型决策过程。
- 提出基于If-Then规则的解释框架,通过关联检索信息源与LLM输出,揭示模型推理逻辑。
- 借鉴Apriori剪枝思想优化规则生成过程,并通过实验验证了方法的效率和有效性。
📝 摘要(中文)
本文首次提出使用If-Then规则来解释新兴的检索增强生成(RAG)大语言模型(LLM)系统。由于RAG使LLM系统能够在推理时整合检索到的信息源,因此连接信息源存在与否的规则可以解释输出的来源。例如,“如果检索到《泰晤士高等教育》排名文章,则LLM将牛津大学排在第一位”。为了生成此类规则,一种暴力方法将使用所有信息源组合来探测LLM,并检查任何信息源的存在或缺失是否导致相同的输出。本文提出优化方法来加速规则生成,其灵感来自频繁项集挖掘中的Apriori剪枝,但在本文的新问题范围内重新定义。最后,通过定性和定量实验证明了本文解决方案的价值和效率。
🔬 方法详解
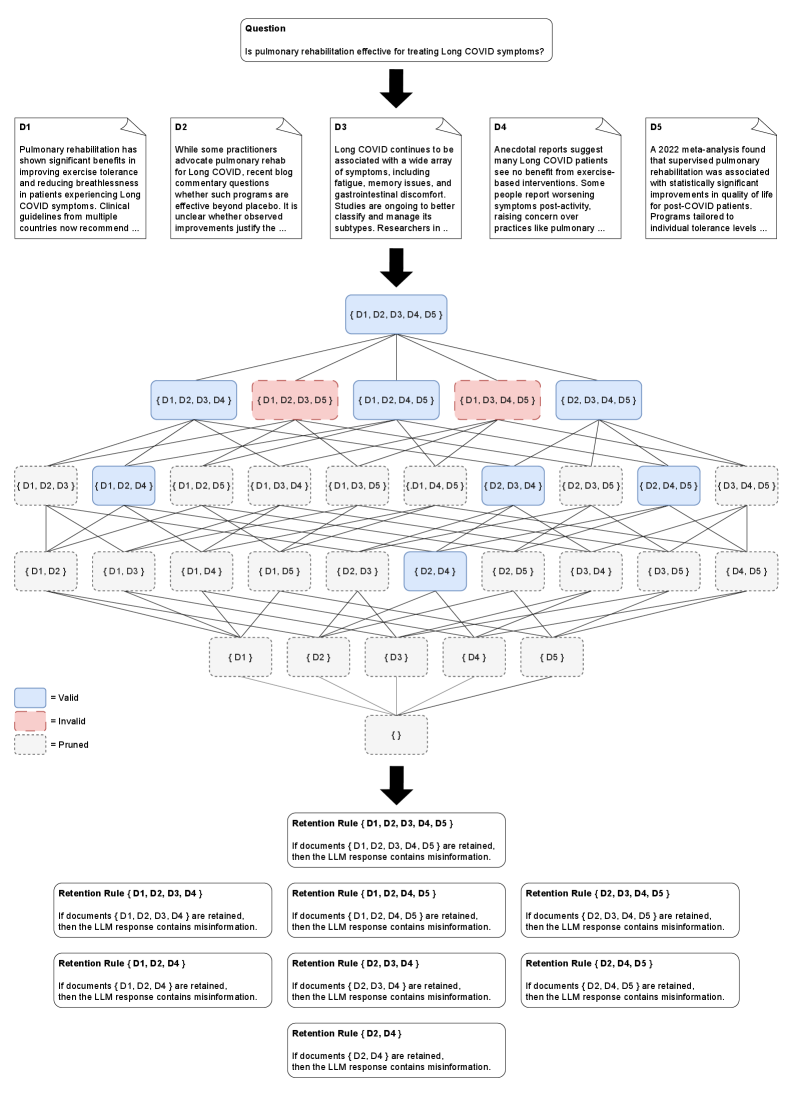
问题定义:论文旨在解决RAG-LLM系统缺乏可解释性的问题。现有方法难以追踪LLM输出结果的来源,用户无法理解模型为何做出特定决策。暴力搜索所有信息源组合以生成解释规则的计算成本过高,效率低下。
核心思路:论文的核心思路是利用If-Then规则来关联检索到的信息源与LLM的输出结果。通过分析哪些信息源的存在或缺失会导致特定的输出,从而揭示LLM的推理逻辑。借鉴频繁项集挖掘中的Apriori剪枝算法,优化规则生成过程,减少计算量。
技术框架:该方法主要包含以下几个阶段:1) 检索信息源:RAG系统根据用户查询检索相关的信息源。2) LLM生成:LLM基于检索到的信息源生成输出结果。3) 规则生成:该阶段是核心,通过分析不同信息源组合下的LLM输出,生成If-Then规则。4) 规则评估:评估生成的规则的质量和可靠性。
关键创新:最重要的技术创新点在于将规则学习方法应用于RAG-LLM系统的可解释性问题,并借鉴Apriori剪枝算法优化规则生成过程。与现有方法相比,该方法能够提供更清晰、更易于理解的解释,并且具有更高的效率。
关键设计:规则生成过程中的剪枝策略是关键设计。类似于Apriori算法,该方法首先生成长度为1的规则,然后逐步增加规则的长度。在每个步骤中,都会根据已生成的规则进行剪枝,排除那些不可能产生有效规则的信息源组合。具体的参数设置和损失函数(如果存在)在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了所提出方法的效率和有效性。定性实验表明,生成的规则能够清晰地解释LLM的输出结果。定量实验表明,优化的规则生成方法能够显著减少计算量,提高规则生成的效率。具体的性能数据和提升幅度在摘要中未提供,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要可解释性的RAG-LLM系统,例如问答系统、知识图谱推理、医疗诊断等。通过提供基于规则的解释,可以提高用户对模型决策的信任度,并帮助开发者更好地理解和改进模型。
📄 摘要(原文)
If-then rules are widely used to explain machine learning models; e.g., "if employed = no, then loan application = rejected." We present the first proposal to apply rules to explain the emerging class of large language models (LLMs) with retrieval-augmented generation (RAG). Since RAG enables LLM systems to incorporate retrieved information sources at inference time, rules linking the presence or absence of sources can explain output provenance; e.g., "if a Times Higher Education ranking article is retrieved, then the LLM ranks Oxford first." To generate such rules, a brute force approach would probe the LLM with all source combinations and check if the presence or absence of any sources leads to the same output. We propose optimizations to speed up rule generation, inspired by Apriori-like pruning from frequent itemset mining but redefined within the scope of our novel problem. We conclude with qualitative and quantitative experiments demonstrating our solutions' value and efficiency.