AutoBench: Automating LLM Evaluation through Reciprocal Peer Assessment
作者: Dario Loi, Elena Maria Muià, Federico Siciliano, Giovanni Trappolini, Vincenzo Crisà, Peter Kruger, Fabrizio Silvestri
分类: cs.CL, cs.AI
发布日期: 2025-10-26
💡 一句话要点
AutoBench:通过互惠互评自动评估大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 互惠互评 动态基准 自动化评估 模型排名
📋 核心要点
- 现有静态基准测试集存在污染问题,且难以适应快速发展的大语言模型,限制了评估的有效性和可靠性。
- AutoBench通过让模型相互评估,动态生成评估任务,并采用迭代加权机制,提升评估的公平性和准确性。
- 实验结果表明,AutoBench与现有基准测试具有高度相关性,且多评判者设计优于单评判者,验证了其有效性。
📝 摘要(中文)
本文介绍AutoBench,一个全自动、自维持的框架,用于通过互惠互评来评估大型语言模型(LLM)。本文对AutoBench方法进行了严格的科学验证,该方法最初是由eZecute S.R.L.开发的一个开源项目。与遭受测试集污染和适应性有限的静态基准不同,AutoBench动态生成新的评估任务,模型在不同的领域交替充当问题生成器、竞争者和评判者。一种迭代加权机制放大了始终可靠的评估者的影响力,将同行评判聚合为基于共识的排名,反映了集体的模型一致性。实验表明,AutoBench与包括MMLU-Pro和GPQA在内的已建立基准具有很强的相关性(分别为78%和63%),验证了这种同行驱动的评估范例。多评判者设计明显优于单评判者基线,证实了分布式评估产生更稳健和与人类一致的评估。AutoBench为静态基准提供了一种可扩展、抗污染的替代方案,用于持续评估不断发展的语言模型。
🔬 方法详解
问题定义:现有的大语言模型(LLM)评估方法主要依赖于静态基准测试集,这些测试集容易受到数据污染的影响,即模型可能在训练过程中已经见过这些测试数据,从而导致评估结果虚高。此外,静态基准测试集难以跟上LLM快速发展的步伐,无法全面评估模型的新能力。因此,需要一种动态、自适应的评估方法,能够有效应对数据污染,并全面评估LLM的性能。
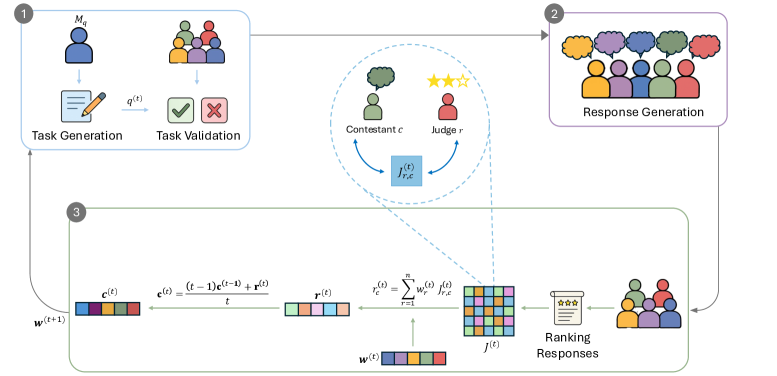
核心思路:AutoBench的核心思路是采用互惠互评的方式来评估LLM。具体来说,就是让不同的LLM在评估过程中扮演不同的角色,包括问题生成者、解答者和评判者。通过这种方式,可以动态生成新的评估任务,避免数据污染,并从多个角度评估LLM的性能。此外,AutoBench还采用了一种迭代加权机制,用于提高评估的准确性和可靠性。
技术框架:AutoBench的整体框架包括以下几个主要模块:1) 问题生成模块:负责生成新的评估问题,可以根据不同的领域和难度生成多样化的题目。2) 解答模块:负责让LLM回答生成的问题。3) 评判模块:负责让LLM对其他LLM的回答进行评分。4) 权重更新模块:根据LLM在评估过程中的表现,更新其权重,提高可靠评估者的影响力。整个流程是一个迭代的过程,不断生成新的问题,让LLM相互评估,并更新权重,最终得到一个基于共识的排名。
关键创新:AutoBench最重要的技术创新点在于其互惠互评的评估范式。与传统的静态基准测试相比,AutoBench能够动态生成评估任务,避免数据污染,并从多个角度评估LLM的性能。此外,AutoBench的迭代加权机制能够提高评估的准确性和可靠性,使得评估结果更加客观公正。
关键设计:AutoBench的关键设计包括:1) 问题生成策略:采用多样化的策略生成不同领域和难度的题目,以全面评估LLM的性能。2) 评分标准:设计合理的评分标准,确保LLM能够客观公正地评价其他LLM的回答。3) 权重更新算法:采用迭代加权算法,根据LLM在评估过程中的表现,动态调整其权重,提高可靠评估者的影响力。具体的参数设置和损失函数等细节,论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
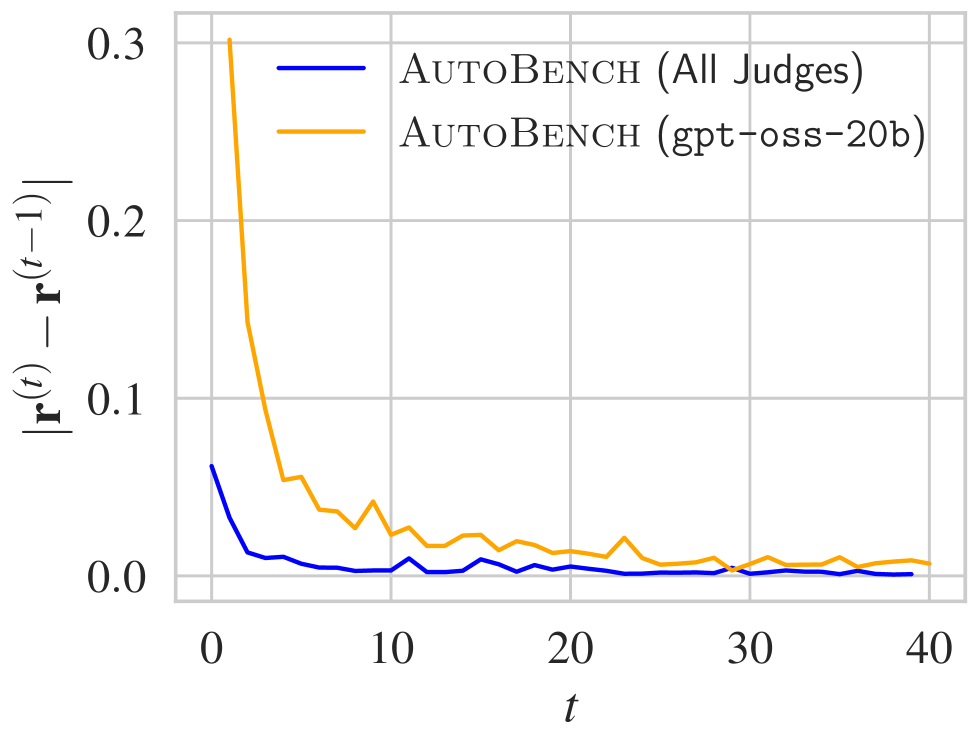
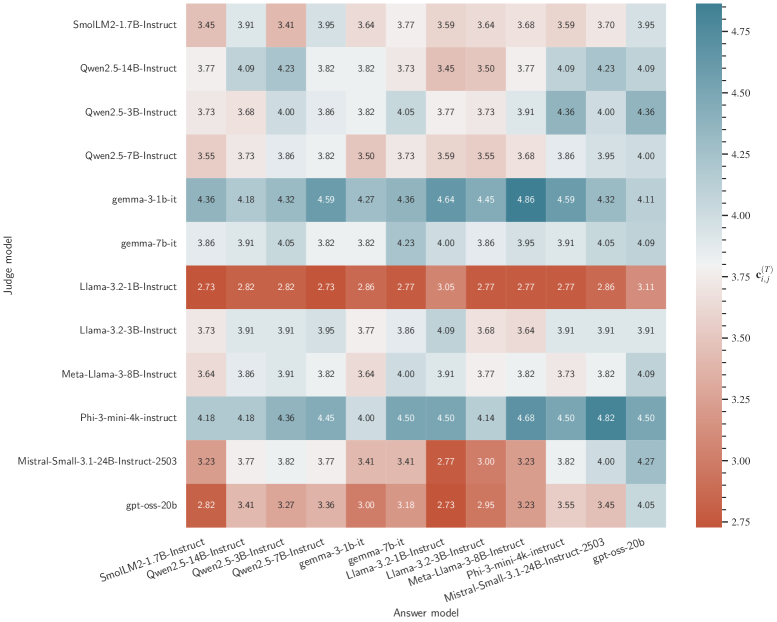
AutoBench与MMLU-Pro和GPQA等现有基准测试具有很强的相关性,相关性分别达到78%和63%。此外,多评判者设计明显优于单评判者基线,表明分布式评估能够产生更稳健和与人类一致的评估结果。这些实验结果验证了AutoBench的有效性和可靠性。
🎯 应用场景
AutoBench可应用于大语言模型的持续评估和优化,帮助开发者快速发现模型的优缺点,并针对性地进行改进。此外,AutoBench还可以用于比较不同LLM的性能,为用户选择合适的模型提供参考。该研究有望推动LLM评估领域的进步,促进LLM技术的进一步发展。
📄 摘要(原文)
We present AutoBench, a fully automated and self-sustaining framework for evaluating Large Language Models (LLMs) through reciprocal peer assessment. This paper provides a rigorous scientific validation of the AutoBench methodology, originally developed as an open-source project by eZecute S.R.L.. Unlike static benchmarks that suffer from test-set contamination and limited adaptability, AutoBench dynamically generates novel evaluation tasks while models alternately serve as question generators, contestants, and judges across diverse domains. An iterative weighting mechanism amplifies the influence of consistently reliable evaluators, aggregating peer judgments into consensus-based rankings that reflect collective model agreement. Our experiments demonstrate strong correlations with established benchmarks including MMLU-Pro and GPQA (respectively 78\% and 63\%), validating this peer-driven evaluation paradigm. The multi-judge design significantly outperforms single-judge baselines, confirming that distributed evaluation produces more robust and human-consistent assessments. AutoBench offers a scalable, contamination-resistant alternative to static benchmarks for the continuous evaluation of evolving language models.