Pedagogy-driven Evaluation of Generative AI-powered Intelligent Tutoring Systems
作者: Kaushal Kumar Maurya, Ekaterina Kochmar
分类: cs.CL
发布日期: 2025-10-26
备注: AIED 2025 (BlueSky). International Conference on Artificial Intelligence in Education. Cham: Springer Nature Switzerland, 2025
💡 一句话要点
针对生成式AI驱动的智能辅导系统,提出教学法驱动的评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 智能辅导系统 生成式AI 教学法驱动 评估框架 学习科学
📋 核心要点
- 现有智能辅导系统(ITS)的评估方法缺乏统一标准和教学法驱动的框架,导致评估结果主观且难以泛化。
- 该研究旨在构建基于学习科学原则的、公平、统一且可扩展的ITS评估方法,以解决现有评估体系的不足。
- 通过案例研究分析现有评估实践的挑战,并提出三个可行的研究方向,为未来ITS评估体系的建立提供指导。
📝 摘要(中文)
人工智能教育(AIED)是一个交叉学科领域,长期以来通过整合技术进步、教育理论和认知心理学的见解来开发智能辅导系统(ITS)。生成式AI(GenAI)模型的显著成功加速了由大型语言模型(LLM)驱动的ITS的开发,这些系统有潜力模仿类人、教学丰富的、认知需求高的辅导。然而,由于缺乏可靠、普遍接受且教学法驱动的评估框架和基准,这些系统的进展和影响在很大程度上无法追踪。目前大多数基于教育对话的ITS评估依赖于主观协议和非标准化基准,导致不一致和有限的泛化能力。本文从主流ITS开发中退后一步,提供了全面的最先进的评估实践,并通过来自细致和关怀的AIED研究的真实案例研究突出了相关的挑战。最后,基于先前跨学科AIED研究的见解,我们提出了三个实用的、可行的和理论上合理的研究方向,这些方向植根于学习科学原理,旨在为ITS建立公平、统一和可扩展的评估方法。
🔬 方法详解
问题定义:论文旨在解决由生成式AI驱动的智能辅导系统(ITS)评估中缺乏可靠、统一和教学法驱动的评估框架的问题。现有方法主要依赖主观协议和非标准化基准,导致评估结果缺乏一致性和泛化能力。这使得我们难以准确衡量和比较不同ITS的性能,阻碍了该领域的健康发展。
核心思路:论文的核心思路是回归教育的本质,强调教学法在ITS评估中的重要性。通过结合学习科学的原理,设计更贴合实际教学场景和学习规律的评估指标和方法。这有助于更全面、客观地评估ITS的教学效果和对学习者的影响。
技术框架:论文并没有提出一个具体的ITS系统架构,而是侧重于ITS的评估框架。该框架包含以下几个关键阶段:1) 梳理现有的ITS评估方法和挑战;2) 分析真实案例,揭示现有评估体系的不足;3) 基于学习科学原理,提出三个可行的研究方向,为构建更有效的评估体系提供指导。
关键创新:论文的关键创新在于强调了教学法驱动的评估理念,并将其与学习科学的原理相结合。这与以往侧重技术指标的评估方法形成了鲜明对比。通过关注ITS的教学效果、学习者的认知过程和学习体验,可以更全面地评估ITS的价值和潜力。
关键设计:论文并没有涉及具体的参数设置或网络结构设计,而是提出了三个关键的研究方向:1) 开发基于学习科学的评估指标,例如认知负荷、元认知能力等;2) 设计更贴合实际教学场景的评估任务,例如问题解决、协作学习等;3) 构建可扩展的评估平台,支持大规模的ITS评估和比较。
🖼️ 关键图片
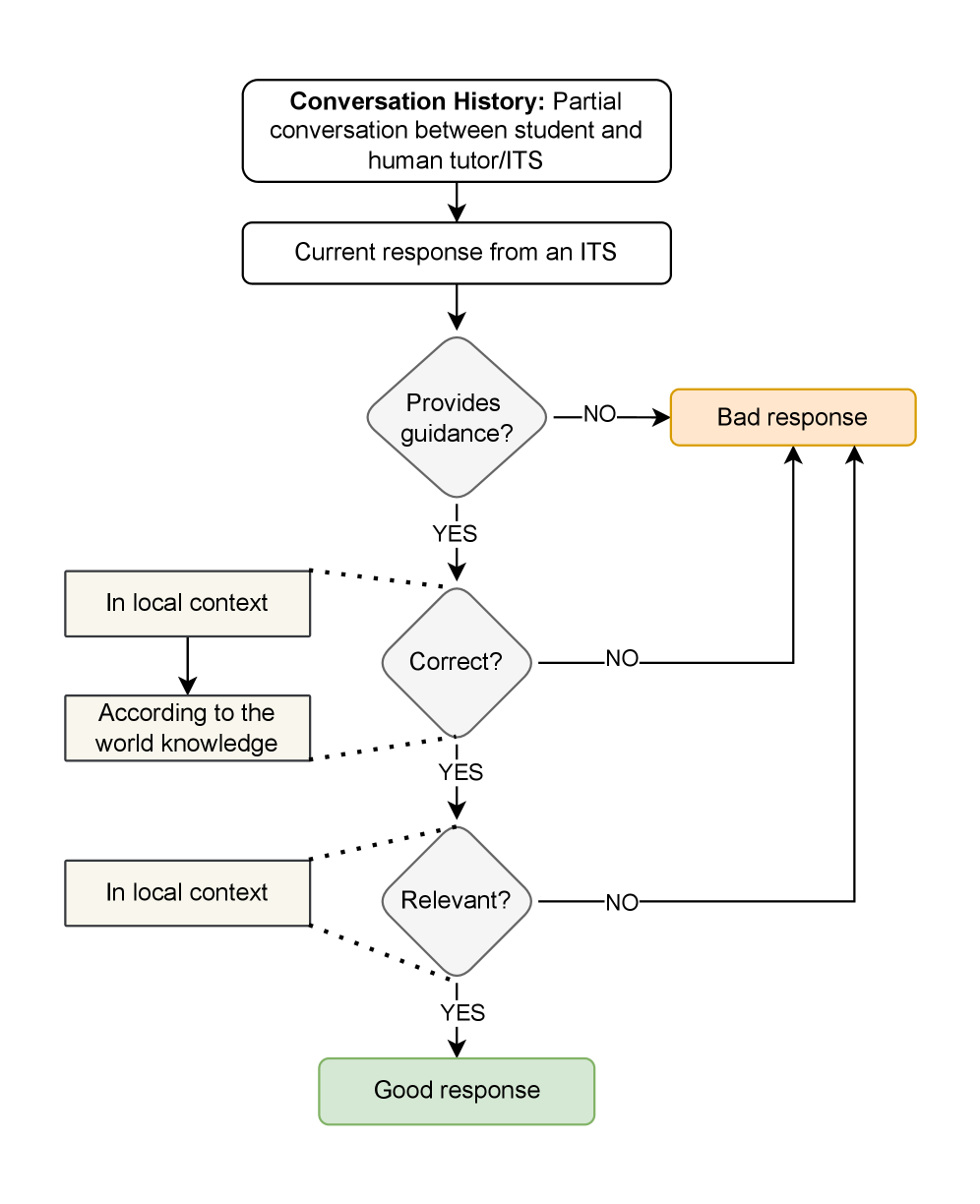
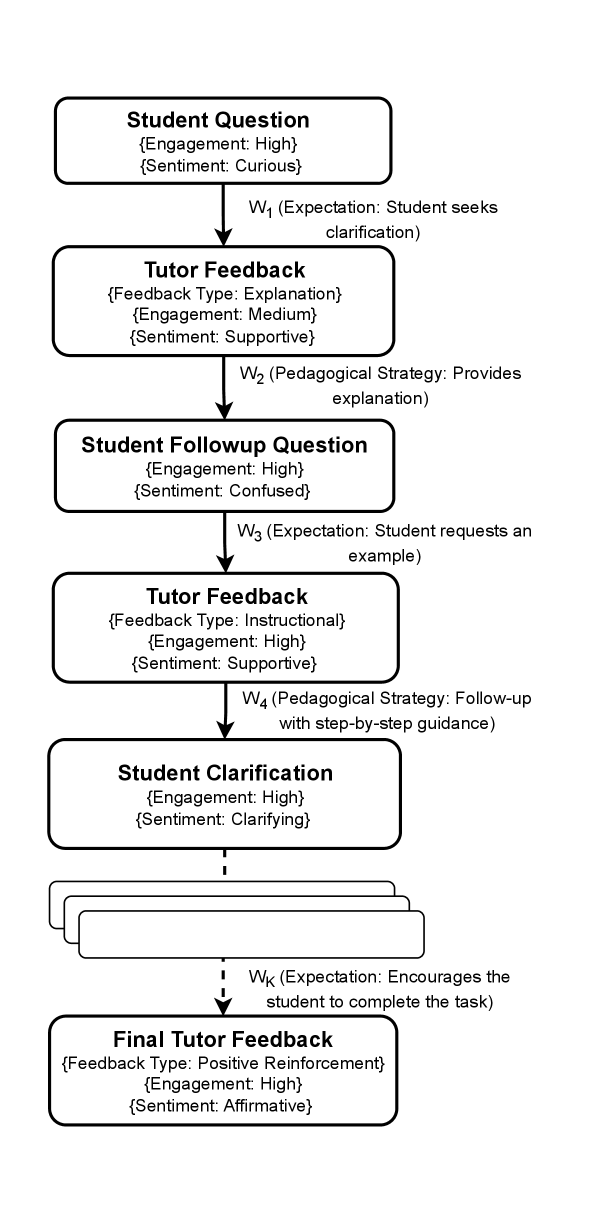
📊 实验亮点
该论文的主要贡献在于提出了教学法驱动的智能辅导系统评估理念,并结合学习科学原理,为构建更有效的评估体系提供了方向。虽然没有提供具体的性能数据,但通过案例研究揭示了现有评估体系的不足,并提出了三个可行的研究方向,为未来的研究奠定了基础。
🎯 应用场景
该研究成果可应用于教育领域,为智能辅导系统的设计、开发和评估提供指导。通过采用教学法驱动的评估框架,可以更有效地评估ITS的教学效果,促进个性化学习和提高教育质量。此外,该研究也有助于推动AIED领域的发展,促进人工智能技术在教育领域的更广泛应用。
📄 摘要(原文)
The interdisciplinary research domain of Artificial Intelligence in Education (AIED) has a long history of developing Intelligent Tutoring Systems (ITSs) by integrating insights from technological advancements, educational theories, and cognitive psychology. The remarkable success of generative AI (GenAI) models has accelerated the development of large language model (LLM)-powered ITSs, which have potential to imitate human-like, pedagogically rich, and cognitively demanding tutoring. However, the progress and impact of these systems remain largely untraceable due to the absence of reliable, universally accepted, and pedagogy-driven evaluation frameworks and benchmarks. Most existing educational dialogue-based ITS evaluations rely on subjective protocols and non-standardized benchmarks, leading to inconsistencies and limited generalizability. In this work, we take a step back from mainstream ITS development and provide comprehensive state-of-the-art evaluation practices, highlighting associated challenges through real-world case studies from careful and caring AIED research. Finally, building on insights from previous interdisciplinary AIED research, we propose three practical, feasible, and theoretically grounded research directions, rooted in learning science principles and aimed at establishing fair, unified, and scalable evaluation methodologies for ITSs.