SABlock: Semantic-Aware KV Cache Eviction with Adaptive Compression Block Size
作者: Jinhan Chen, Jianchun Liu, Hongli Xu, Xianjun Gao, Shilong Wang
分类: cs.CL
发布日期: 2025-10-26
💡 一句话要点
SABlock:基于语义感知的自适应块大小KV缓存淘汰,提升长文本LLM推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存淘汰 长文本LLM 语义感知 自适应压缩 大语言模型推理
📋 核心要点
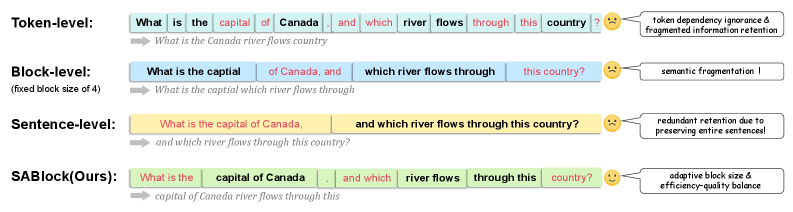
- 长文本LLM推理面临KV缓存内存占用过大的瓶颈,现有token、块或句子级别压缩方法难以兼顾语义连贯性和内存效率。
- SABlock通过语义分割对齐压缩边界,利用段引导的token评分优化重要性评估,并自适应确定块大小,在保证语义完整性的同时提升压缩效率。
- 实验表明,SABlock在相同内存预算下优于现有方法,例如在NIAH测试中,仅用少量KV条目即可达到接近完整缓存的检索准确率,并显著降低峰值内存使用和提升解码速度。
📝 摘要(中文)
针对长文本大语言模型(LLM)推理中KV缓存日益增长的内存占用问题,本文提出了一种名为SABlock的语义感知KV缓存淘汰框架,该框架采用自适应块大小。SABlock首先执行语义分割,使压缩边界与语言结构对齐,然后应用段引导的token评分来优化token重要性估计。最后,对于每个段,采用预算驱动的搜索策略自适应地确定最佳块大小,从而在给定的缓存预算下,既能保持语义完整性,又能提高压缩效率。在长文本基准测试上的大量实验表明,在相同的内存预算下,SABlock始终优于最先进的基线方法。例如,在Needle-in-a-Haystack (NIAH)测试中,SABlock仅使用96个KV条目即可实现99.9%的检索准确率,几乎与保留高达8K条目的完整缓存基线性能相匹配。在1,024的固定缓存预算下,SABlock进一步降低了46.28%的峰值内存使用量,并在128K上下文长度下实现了高达9.5倍的解码速度提升。
🔬 方法详解
问题定义:论文旨在解决长文本LLM推理过程中,KV缓存占用大量内存,导致推理效率降低的问题。现有方法如token级别、块级别或句子级别的压缩,要么损失过多语义信息,要么压缩效率不高,无法在语义连贯性和内存效率之间取得良好平衡。
核心思路:论文的核心思路是利用语义信息指导KV缓存的压缩和淘汰。通过将文本分割成语义相关的片段,并根据片段的重要性自适应地调整压缩块的大小,从而在保证语义完整性的前提下,尽可能地减少内存占用。
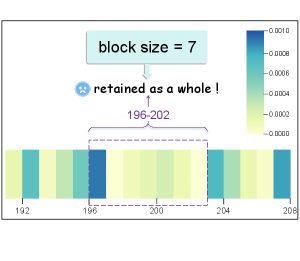
技术框架:SABlock框架主要包含三个阶段:1) 语义分割:使用预训练模型或规则将文本分割成语义相关的片段。2) 段引导的Token评分:根据片段的语义信息,对片段内的token进行重要性评分,更准确地评估每个token对模型性能的影响。3) 自适应块大小确定:在给定的缓存预算下,针对每个片段,搜索最佳的块大小,以最大程度地保留语义信息并提高压缩效率。
关键创新:SABlock的关键创新在于其语义感知的压缩和淘汰策略。与传统的基于token或块的压缩方法不同,SABlock充分利用了文本的语义信息,使得压缩边界与语言结构对齐,从而更好地保留了语义的连贯性。此外,自适应块大小的确定策略也使得SABlock能够根据不同片段的重要性,灵活地调整压缩力度,进一步提高了压缩效率。
关键设计:语义分割可以使用现有的NLP模型(如句子分割模型)或基于规则的方法。Token评分可以基于注意力权重、梯度或其他与模型性能相关的指标。自适应块大小的搜索策略可以使用贪心算法或动态规划等方法,在给定的缓存预算下,找到最佳的块大小组合。损失函数的设计需要考虑语义信息的保留程度和压缩效率。
🖼️ 关键图片
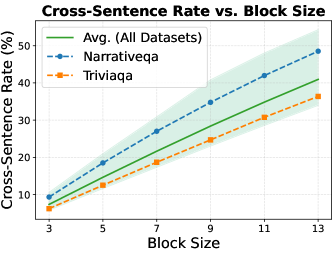
📊 实验亮点
SABlock在Needle-in-a-Haystack (NIAH)测试中,仅使用96个KV条目即可实现99.9%的检索准确率,接近完整缓存(8K条目)的性能。在固定缓存预算为1024的情况下,SABlock降低了46.28%的峰值内存使用量,并在128K上下文长度下实现了高达9.5倍的解码速度提升,显著优于现有技术。
🎯 应用场景
SABlock可应用于各种需要处理长文本的大语言模型应用场景,例如长文档摘要、机器翻译、问答系统、代码生成等。通过降低KV缓存的内存占用,SABlock可以提高LLM的推理速度和可扩展性,使其能够在资源受限的设备上运行,并支持处理更长的上下文。
📄 摘要(原文)
The growing memory footprint of the Key-Value (KV) cache poses a severe scalability bottleneck for long-context Large Language Model (LLM) inference. While KV cache eviction has emerged as an effective solution by discarding less critical tokens, existing token-, block-, and sentence-level compression methods struggle to balance semantic coherence and memory efficiency. To this end, we introduce SABlock, a \underline{s}emantic-aware KV cache eviction framework with \underline{a}daptive \underline{block} sizes. Specifically, SABlock first performs semantic segmentation to align compression boundaries with linguistic structures, then applies segment-guided token scoring to refine token importance estimation. Finally, for each segment, a budget-driven search strategy adaptively determines the optimal block size that preserves semantic integrity while improving compression efficiency under a given cache budget. Extensive experiments on long-context benchmarks demonstrate that SABlock consistently outperforms state-of-the-art baselines under the same memory budgets. For instance, on Needle-in-a-Haystack (NIAH), SABlock achieves 99.9% retrieval accuracy with only 96 KV entries, nearly matching the performance of the full-cache baseline that retains up to 8K entries. Under a fixed cache budget of 1,024, SABlock further reduces peak memory usage by 46.28% and achieves up to 9.5x faster decoding on a 128K context length.