LooGLE v2: Are LLMs Ready for Real World Long Dependency Challenges?
作者: Ziyuan He, Yuxuan Wang, Jiaqi Li, Kexin Liang, Muhan Zhang
分类: cs.CL, cs.AI
发布日期: 2025-10-26
备注: NeurIPS 2025 Datasets and Benchmarks Track
💡 一句话要点
LooGLE v2:评估LLM在真实世界长依赖任务中的能力,揭示其局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 长依赖任务 大型语言模型 基准测试 真实世界应用
📋 核心要点
- 现有LLM在长依赖任务中的长文本理解能力不足,尤其是在真实世界场景下。
- 提出LooGLE v2基准,包含法律、金融等领域长文本,评估LLM处理长依赖任务的能力。
- 实验表明,即使是最佳模型在LooGLE v2上表现也有限,揭示了LLM在长文本理解方面的局限性。
📝 摘要(中文)
大型语言模型(LLMs)的上下文窗口最近不断扩展,但它们在长依赖任务中的长上下文理解能力仍然存在根本性的局限性,并且未被充分探索。在许多现实世界的长上下文应用中,这种差距尤其显著,而这些应用很少被基准测试。本文介绍了LooGLE v2,这是一个新颖的基准,旨在评估LLM在真实世界应用和场景中的长上下文能力。我们的基准包括自动收集的真实世界长文本,范围从16k到2M tokens,涵盖法律、金融、游戏和代码等领域。相应地,我们精心设计了10种特定领域的长依赖任务,并通过可扩展的数据管理流程生成了1,934个具有各种多样性和复杂性的QA实例,以满足进一步的实际需求。我们对6个本地部署的和4个基于API的LLM进行了全面评估。评估结果表明,即使是性能最佳的模型在我们的基准测试中也仅获得了59.2%的总体得分。尽管上下文窗口很大,但流行的LLM只能理解比它们声称的短得多的上下文长度,这揭示了它们在处理具有长依赖性的真实世界任务方面的重大局限性,并突出了模型在实际长上下文理解方面有很大的改进空间。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)虽然拥有越来越大的上下文窗口,但在处理真实世界中存在的长依赖关系的任务时,其长文本理解能力仍然不足。现有的基准测试很少关注真实世界的长文本应用,无法充分评估LLMs在这些场景下的性能。因此,需要一个更贴近实际应用场景的基准来评估LLMs的长文本理解能力。
核心思路:LooGLE v2的核心思路是构建一个包含真实世界长文本的基准数据集,并设计相应的长依赖任务,以评估LLMs在实际应用场景下的长文本理解能力。通过对不同领域的长文本进行分析,并设计多样化的QA实例,可以更全面地评估LLMs的长文本理解能力。
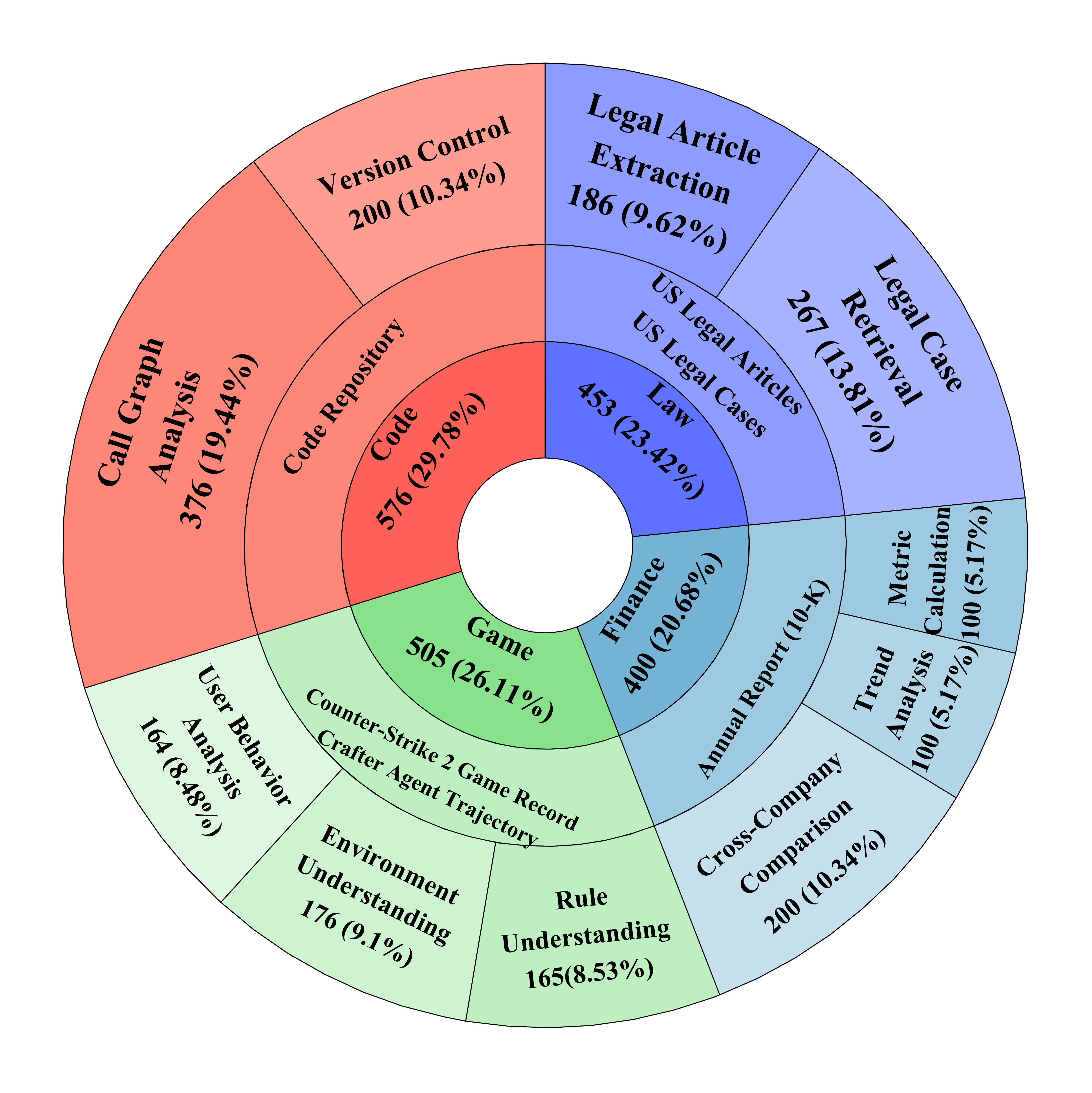
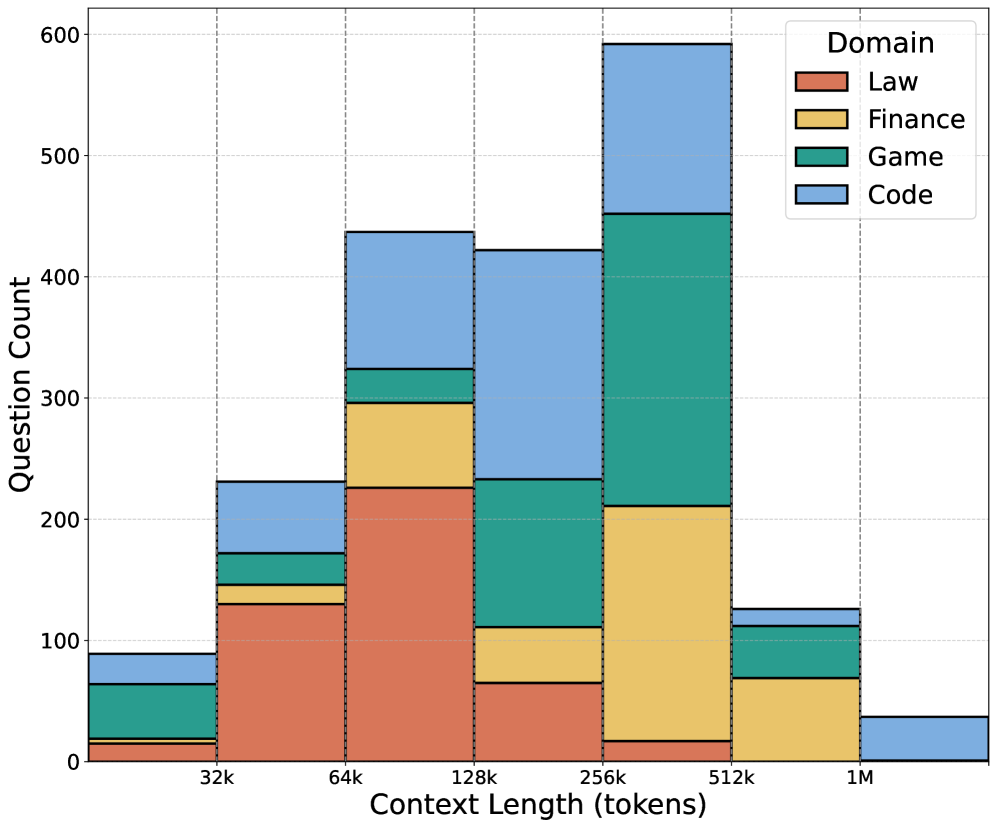
技术框架:LooGLE v2的整体框架包括以下几个主要模块:1) 数据收集模块:自动收集来自法律、金融、游戏和代码等领域的真实世界长文本,文本长度范围从16k到2M tokens。2) 任务设计模块:针对每个领域,设计特定类型的长依赖任务,例如法律领域的合同条款理解、金融领域的财务报表分析等。3) 数据生成模块:通过可扩展的数据管理流程,生成包含各种多样性和复杂性的QA实例,总共生成了1,934个QA实例。4) 评估模块:使用生成的QA实例对LLMs进行评估,并计算模型的准确率等指标。
关键创新:LooGLE v2的关键创新在于其真实性和多样性。与现有的基准测试相比,LooGLE v2使用了真实世界的长文本数据,更贴近实际应用场景。此外,LooGLE v2还设计了多种类型的长依赖任务,涵盖了不同的领域和应用场景,可以更全面地评估LLMs的长文本理解能力。
关键设计:LooGLE v2的关键设计包括:1) 长文本数据的选择:选择来自不同领域的真实世界长文本,以保证数据的真实性和多样性。2) 任务类型的选择:针对每个领域,设计特定类型的长依赖任务,以保证任务的相关性和挑战性。3) QA实例的生成:通过可扩展的数据管理流程,生成包含各种多样性和复杂性的QA实例,以保证评估的全面性和准确性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,即使是性能最佳的LLM在LooGLE v2基准上的总体得分仅为59.2%,表明现有LLM在处理真实世界长依赖任务方面存在显著局限性。该研究还发现,LLM能够有效理解的上下文长度远小于其声称的上下文窗口大小,揭示了模型在长文本理解方面的瓶颈。
🎯 应用场景
LooGLE v2基准的潜在应用领域包括:评估和改进LLM在处理法律文件、金融报告、游戏文本和代码等长文本任务中的能力。该研究的实际价值在于帮助开发者更好地了解LLM在长文本理解方面的局限性,并为模型改进提供指导。未来,该基准可以促进LLM在实际应用场景中的更广泛应用。
📄 摘要(原文)
Large language models (LLMs) are equipped with increasingly extended context windows recently, yet their long context understanding capabilities over long dependency tasks remain fundamentally limited and underexplored. This gap is especially significant in many real-world long-context applications that were rarely benchmarked. In this paper, we introduce LooGLE v2, a novel benchmark designed to evaluate LLMs' long context ability in real-world applications and scenarios. Our benchmark consists of automatically collected real-world long texts, ranging from 16k to 2M tokens, encompassing domains in law, finance, game and code. Accordingly, we delicately design 10 types of domain-specific long-dependency tasks and generate 1,934 QA instances with various diversity and complexity in a scalable data curation pipeline for further practical needs. We conduct a comprehensive assessment of 6 locally deployed and 4 API-based LLMs. The evaluation results show that even the best-performing model achieves only a 59.2% overall score on our benchmark. Despite the extensive context windows, popular LLMs are only capable of understanding a much shorter length of context than they claim to be, revealing significant limitations in their ability to handle real-world tasks with long dependencies and highlighting substantial room for model improvement in practical long-context understanding.