Frustratingly Easy Task-aware Pruning for Large Language Models
作者: Yuanhe Tian, Junjie Liu, Xican Yang, Haishan Ye, Yan Song
分类: cs.CL, cs.LG
发布日期: 2025-10-26
备注: 8 pages, 3 figures
💡 一句话要点
提出任务感知剪枝方法,在压缩大语言模型的同时保持特定任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 任务感知 参数重要性 模型压缩
📋 核心要点
- 现有LLM剪枝方法侧重于通用语言能力,忽略了特定任务的性能保持。
- 论文提出任务感知剪枝方法,融合通用和任务特定数据,区分参数重要性。
- 实验表明,该方法在保持任务性能的同时,有效压缩了LLM的参数空间。
📝 摘要(中文)
剪枝是降低大语言模型(LLM)资源需求的有效方法,使其能够在控制训练和推理成本的同时,发挥其强大的能力。现有LLM剪枝研究通常根据参数幅度和校准数据激活值对参数的重要性进行排序,并移除(或屏蔽)不太重要的参数,从而减小LLM的规模。然而,这些方法主要关注保持LLM生成流畅句子的能力,而忽略了在特定领域和任务上的性能。本文提出了一种简单而有效的LLM剪枝方法,在缩小参数空间的同时,保持任务特定的能力。我们首先分析了传统剪枝如何在通用领域校准下最小化损失扰动,并通过将任务特定的特征分布纳入现有剪枝算法的重要性计算中来扩展这一公式。因此,我们的框架使用通用和任务特定的校准数据计算单独的重要性分数,基于激活范数差异将参数划分为共享组和独占组,然后融合它们的分数以指导剪枝过程。这种设计使我们的方法能够与各种基础剪枝技术无缝集成,并在压缩下保持LLM的专业能力。在广泛使用的基准测试上的实验表明,我们的方法是有效的,并且在相同的剪枝比例和不同的设置下始终优于基线。
🔬 方法详解
问题定义:现有的大语言模型剪枝方法主要关注通用语言能力的保持,例如生成流畅的文本,而忽略了模型在特定任务上的性能。这意味着剪枝后的模型可能在通用任务上表现良好,但在特定领域或任务上的表现会显著下降。因此,如何设计一种剪枝方法,能够在压缩模型的同时,最大限度地保持其在特定任务上的性能,是一个重要的挑战。
核心思路:论文的核心思路是引入任务感知的剪枝策略。具体来说,该方法不仅考虑了通用数据的激活值,还考虑了任务特定数据的激活值,从而更准确地评估参数对于特定任务的重要性。通过区分参数在通用任务和特定任务中的作用,可以更有选择性地进行剪枝,从而在压缩模型的同时,更好地保持其在特定任务上的性能。
技术框架:该方法的技术框架主要包含以下几个阶段:1) 使用通用数据和任务特定数据分别对模型进行校准,计算参数的重要性分数。2) 基于激活范数差异将参数划分为共享组和独占组,其中共享组的参数对通用任务和特定任务都很重要,而独占组的参数只对特定任务重要。3) 将通用和任务特定的重要性分数进行融合,得到最终的参数重要性评估。4) 根据参数的重要性进行剪枝,移除不重要的参数。
关键创新:该方法最重要的技术创新点在于引入了任务感知的剪枝策略。与传统的剪枝方法只考虑通用数据的激活值不同,该方法同时考虑了通用数据和任务特定数据的激活值,从而更准确地评估参数对于特定任务的重要性。这种任务感知的剪枝策略可以更好地保持模型在特定任务上的性能。
关键设计:该方法的一个关键设计是参数分组策略,即基于激活范数差异将参数划分为共享组和独占组。这种分组策略可以帮助区分参数在通用任务和特定任务中的作用,从而更有选择性地进行剪枝。另一个关键设计是重要性分数融合策略,即如何将通用和任务特定的重要性分数进行融合,得到最终的参数重要性评估。论文中具体使用了加权平均的方法,其中权重可以根据任务的重要性进行调整。
🖼️ 关键图片

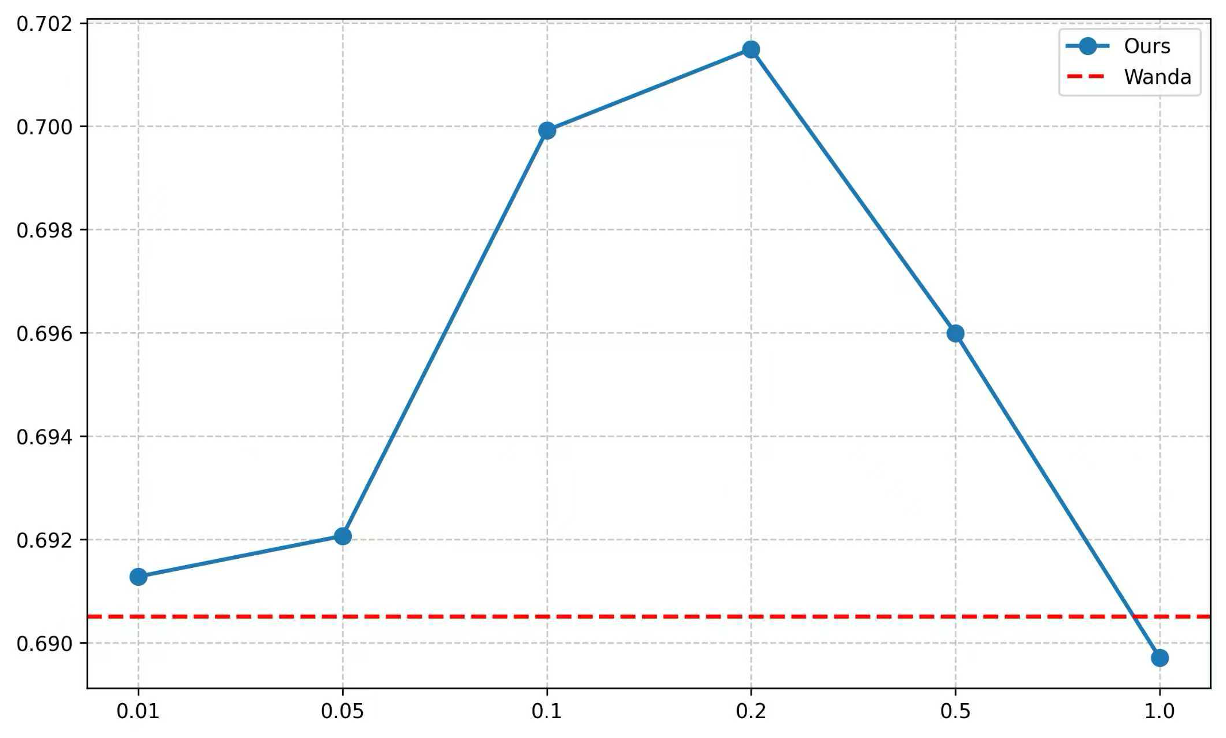

📊 实验亮点
实验结果表明,该方法在广泛使用的基准测试上始终优于基线方法,在相同的剪枝比例和不同的设置下,能够更好地保持模型在特定任务上的性能。例如,在某个特定任务上,该方法可以将模型的参数量减少50%,同时保持性能几乎不变,而基线方法的性能则会显著下降。这些结果表明,该方法是一种有效且实用的LLM剪枝方法。
🎯 应用场景
该研究成果可应用于各种需要部署大语言模型的场景,尤其是在资源受限的环境中,例如移动设备、嵌入式系统等。通过任务感知剪枝,可以在保证模型性能的同时,显著降低模型的存储空间和计算复杂度,从而使其能够更容易地部署到这些资源受限的环境中。此外,该方法还可以用于个性化模型定制,根据用户的特定需求,对模型进行剪枝,从而得到一个更小、更高效的模型。
📄 摘要(原文)
Pruning provides a practical solution to reduce the resources required to run large language models (LLMs) to benefit from their effective capabilities as well as control their cost for training and inference. Research on LLM pruning often ranks the importance of LLM parameters using their magnitudes and calibration-data activations and removes (or masks) the less important ones, accordingly reducing LLMs' size. However, these approaches primarily focus on preserving the LLM's ability to generate fluent sentences, while neglecting performance on specific domains and tasks. In this paper, we propose a simple yet effective pruning approach for LLMs that preserves task-specific capabilities while shrinking their parameter space. We first analyze how conventional pruning minimizes loss perturbation under general-domain calibration and extend this formulation by incorporating task-specific feature distributions into the importance computation of existing pruning algorithms. Thus, our framework computes separate importance scores using both general and task-specific calibration data, partitions parameters into shared and exclusive groups based on activation-norm differences, and then fuses their scores to guide the pruning process. This design enables our method to integrate seamlessly with various foundation pruning techniques and preserve the LLM's specialized abilities under compression. Experiments on widely used benchmarks demonstrate that our approach is effective and consistently outperforms the baselines with identical pruning ratios and different settings.