Evaluating LLMs' Reasoning Over Ordered Procedural Steps
作者: Adrita Anika, Md Messal Monem Miah
分类: cs.CL, cs.LG
发布日期: 2025-10-25 (更新: 2025-11-15)
备注: Accepted to IJCNLP-AACL 2025 Findings
💡 一句话要点
评估LLM在排序程序步骤上的推理能力,以食谱重建为场景
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 程序推理 序列重建 食谱数据集 排序评估
📋 核心要点
- 现有LLM在处理步骤顺序至关重要的程序序列推理方面存在不足,尤其是在长序列和乱序严重的情况下。
- 本文提出通过重建打乱的食谱步骤序列来评估LLM的程序推理能力,关注模型对步骤顺序的理解和还原。
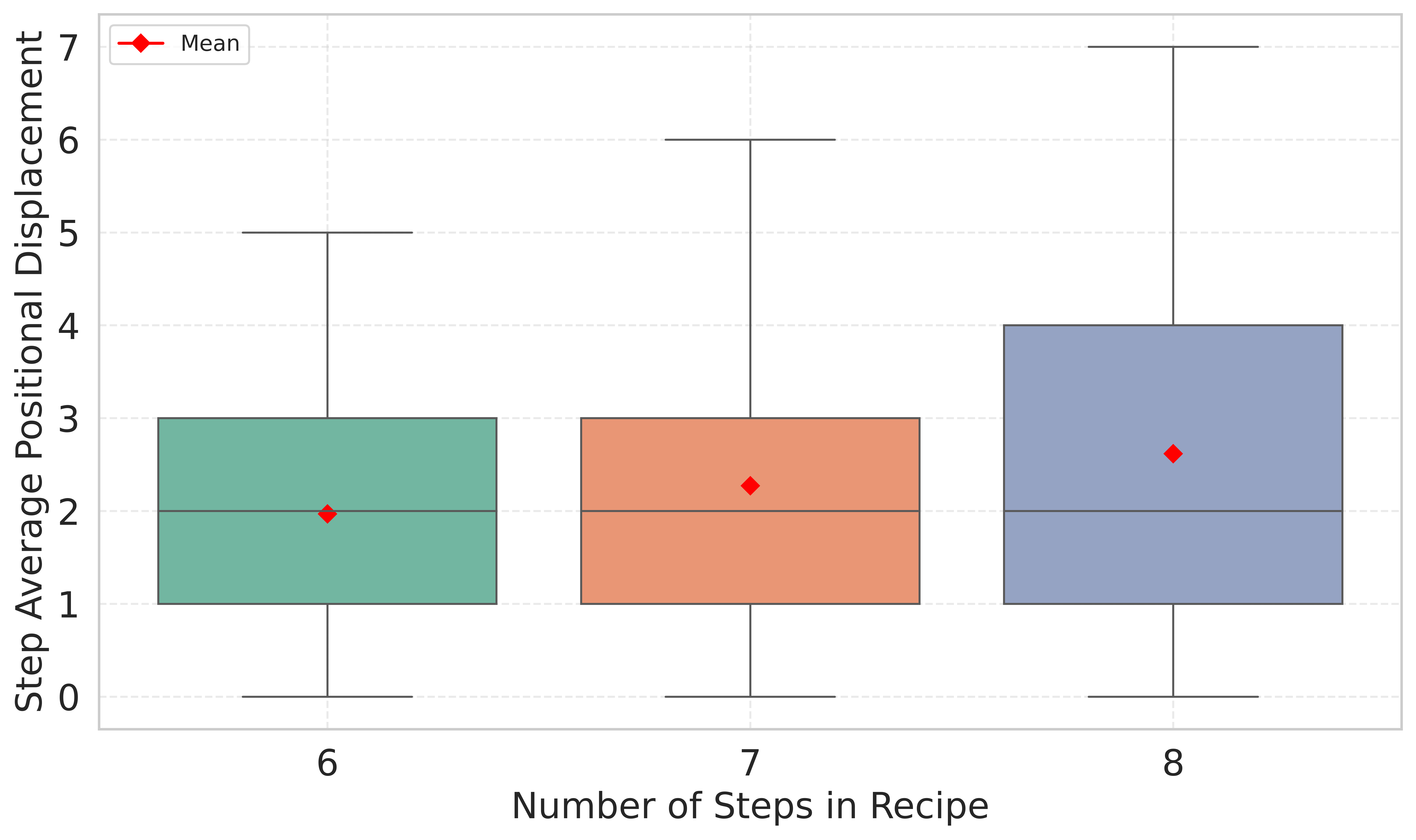
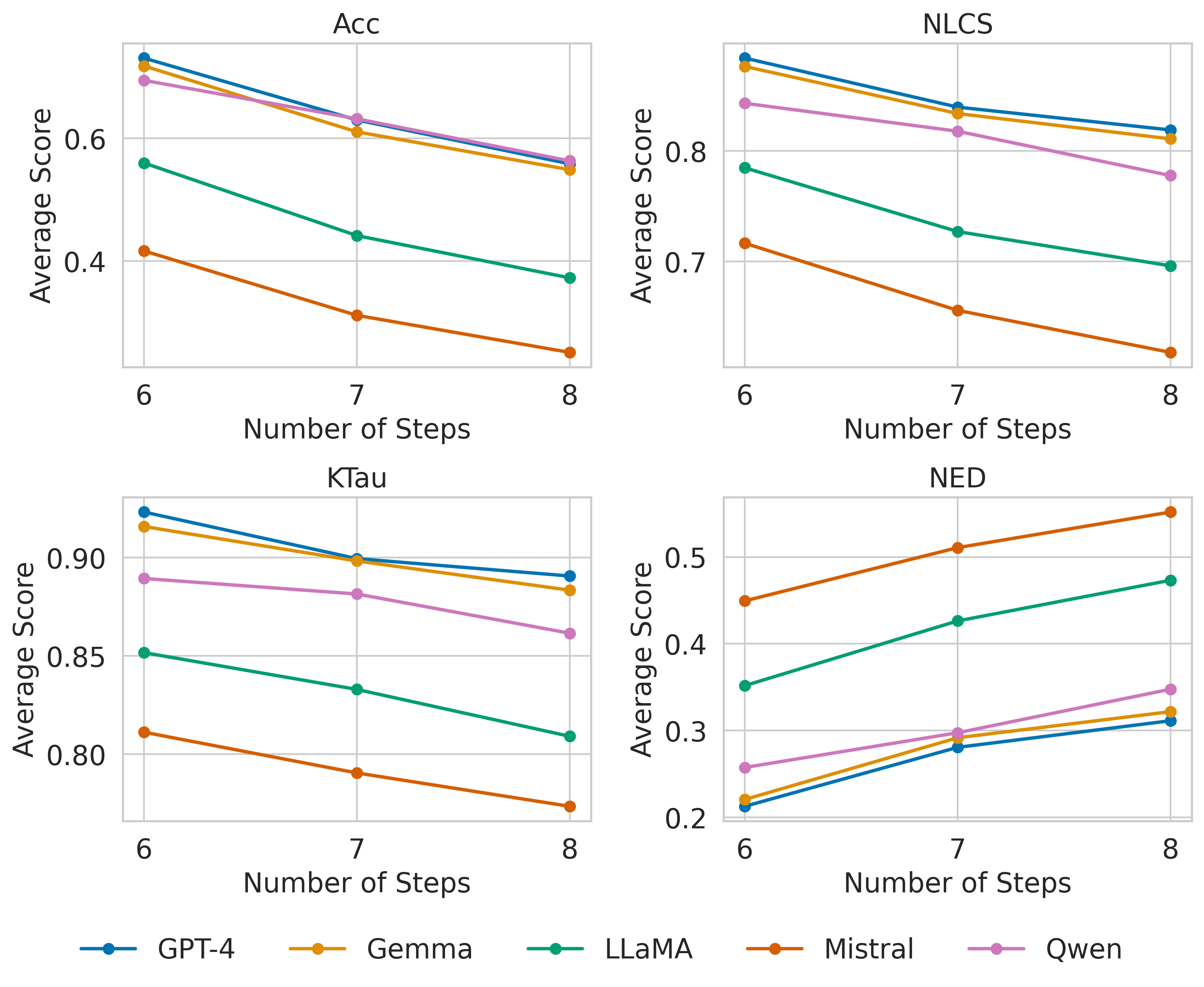
- 实验结果表明,LLM在处理更长和更混乱的食谱序列时性能显著下降,揭示了其在程序推理方面的局限性。
📝 摘要(中文)
本文研究了大型语言模型(LLM)在程序序列上的推理能力,其中步骤的顺序直接影响结果。我们专注于从被打乱的程序步骤中重建全局排序序列的任务,并使用一个精选的食谱数据集,因为在食谱领域中,正确的步骤排序对于任务成功至关重要。我们在零样本和少样本设置下评估了多个LLM,并提出了一个全面的评估框架,该框架采用了来自排序和序列比对的成熟指标,包括Kendall's Tau、归一化最长公共子序列(NLCS)和归一化编辑距离(NED),这些指标捕捉了排序质量的互补方面。我们的分析表明,模型性能随着序列长度的增加而下降,反映了更长过程的复杂性。我们还发现,输入中更大的步骤位移,对应于更严重的打乱,会导致进一步的性能下降。这些发现突出了当前LLM在程序推理方面的局限性,尤其是在处理更长和更混乱的输入时。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在处理需要按顺序执行的程序性任务时的推理能力。现有方法在处理长序列和乱序严重的序列时,性能会显著下降,无法准确地重建原始序列。食谱重建任务需要模型理解每个步骤之间的依赖关系,并按照正确的顺序排列它们,这对LLM提出了挑战。
核心思路:论文的核心思路是将程序推理问题转化为序列重建问题,通过评估LLM重建被打乱的食谱步骤序列的能力来衡量其程序推理能力。选择食谱作为研究对象是因为食谱的步骤顺序对最终结果至关重要,并且易于理解和评估。
技术框架:整体框架包括以下几个步骤:1)构建食谱数据集,其中包含一系列按顺序排列的步骤;2)对食谱步骤进行随机打乱,生成乱序的输入序列;3)使用LLM对乱序序列进行排序,生成重建后的序列;4)使用多种评估指标(Kendall's Tau, NLCS, NED)比较重建序列和原始序列,评估LLM的排序性能。
关键创新:论文的关键创新在于提出了一个基于食谱重建的程序推理评估框架,并采用了多种排序和序列比对指标来全面评估LLM的排序质量。此外,论文还分析了序列长度和步骤位移对LLM性能的影响,揭示了LLM在处理复杂程序推理任务时的局限性。
关键设计:论文使用了三种评估指标:Kendall's Tau用于衡量两个排序之间的相关性;Normalized Longest Common Subsequence (NLCS) 用于衡量两个序列的最长公共子序列的长度,并进行归一化;Normalized Edit Distance (NED) 用于衡量两个序列之间的编辑距离,并进行归一化。这些指标从不同的角度评估了LLM重建序列的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在食谱重建任务中的性能随着序列长度的增加而下降,并且随着输入序列中步骤位移的增加而降低。例如,在长序列和高位移的情况下,模型的Kendall's Tau值显著降低,表明模型难以正确重建原始序列。这些结果突出了当前LLM在程序推理方面的局限性。
🎯 应用场景
该研究成果可应用于提升LLM在自动化流程规划、机器人任务执行、智能助手等领域的性能。通过提高LLM对程序步骤的理解和排序能力,可以使其更好地完成需要按顺序执行的任务,例如自动生成软件安装指南、控制机器人完成复杂操作等,具有重要的实际应用价值。
📄 摘要(原文)
Reasoning over procedural sequences, where the order of steps directly impacts outcomes, is a critical capability for large language models (LLMs). In this work, we study the task of reconstructing globally ordered sequences from shuffled procedural steps, using a curated dataset of food recipes, a domain where correct sequencing is essential for task success. We evaluate several LLMs under zero-shot and few-shot settings and present a comprehensive evaluation framework that adapts established metrics from ranking and sequence alignment. These include Kendall's Tau, Normalized Longest Common Subsequence (NLCS), and Normalized Edit Distance (NED), which capture complementary aspects of ordering quality. Our analysis shows that model performance declines with increasing sequence length, reflecting the added complexity of longer procedures. We also find that greater step displacement in the input, corresponding to more severe shuffling, leads to further degradation. These findings highlight the limitations of current LLMs in procedural reasoning, especially with longer and more disordered inputs.