PANORAMA: A Dataset and Benchmarks Capturing Decision Trails and Rationales in Patent Examination
作者: Hyunseung Lim, Sooyohn Nam, Sungmin Na, Ji Yong Cho, June Yong Yang, Hyungyu Shin, Yoonjoo Lee, Juho Kim, Moontae Lee, Hwajung Hong
分类: cs.CY, cs.CL
发布日期: 2025-10-25
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
构建PANORAMA数据集,模拟专利审查决策过程,评估LLM在专利审查中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 专利审查 自然语言处理 大型语言模型 数据集 决策过程
📋 核心要点
- 现有专利审查NLP方法侧重于预测授权结果,忽略了审查员的逐步评估过程和决策依据。
- PANORAMA数据集通过保留完整的专利审查决策过程,模拟专利审查员的实际工作流程。
- 实验表明,LLM在专利审查的特定步骤(如检索)表现良好,但在新颖性和非显而易见性评估方面存在不足。
📝 摘要(中文)
本文提出了PANORAMA数据集,旨在解决自然语言处理(NLP)领域中专利审查的挑战,尤其是在大型语言模型(LLM)出现后。专利审查需要对提交的权利要求是否符合新颖性和非显而易见性的法定标准进行细致的人工判断。以往的研究通常将此问题简化为预测任务,忽略了审查员逐步评估的过程和审查意见书中的理由。PANORAMA包含8143份美国专利审查记录,保留了完整的决策过程,包括原始申请、所有引用的参考文献、非最终驳回和授权通知。该数据集将审查过程分解为顺序基准,模拟专利专业人员的审查流程,并评估LLM在每个步骤中的能力。实验表明,LLM在检索相关现有技术和定位相关段落方面表现相对较好,但在评估专利权利要求的新颖性和非显而易见性方面存在困难。该数据集已在Hugging Face上公开。
🔬 方法详解
问题定义:专利审查是一个复杂的NLP任务,需要判断专利申请是否满足新颖性和非显而易见性的标准。现有方法通常将其简化为预测任务,忽略了审查员的逐步评估过程,缺乏对决策依据的深入理解,难以衡量现有技术在专利审查流程中的真实能力。
核心思路:PANORAMA数据集的核心思路是构建一个包含完整专利审查决策过程的数据集,模拟专利审查员的实际工作流程。通过将审查过程分解为顺序基准,可以更细粒度地评估LLM在每个步骤中的能力,从而更全面地了解LLM在专利审查中的优势和不足。
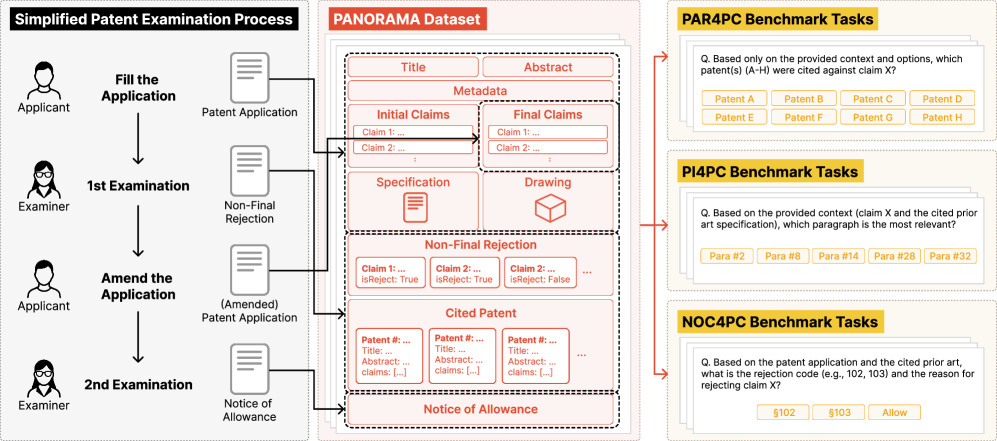
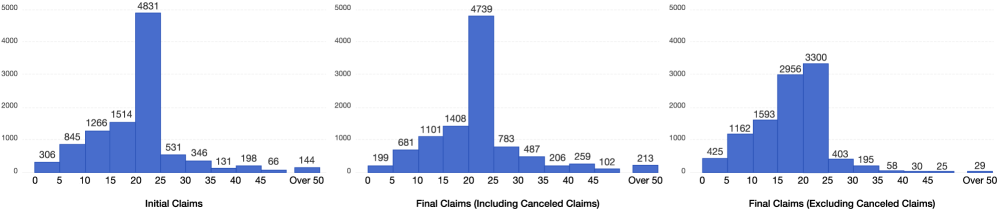
技术框架:PANORAMA数据集包含8143份美国专利审查记录,包括原始申请、所有引用的参考文献、非最终驳回和授权通知等。数据集将专利审查过程分解为多个步骤,例如:1) 检索相关现有技术;2) 定位相关段落;3) 评估专利权利要求的新颖性;4) 评估专利权利要求的非显而易见性。每个步骤都对应一个基准任务,用于评估LLM的性能。
关键创新:PANORAMA数据集的关键创新在于其完整性和细粒度。它不仅包含了完整的专利审查决策过程,还将其分解为多个步骤,从而可以更全面地评估LLM在专利审查中的能力。此外,PANORAMA数据集还提供了审查意见书中的理由,这有助于研究人员更好地理解审查员的决策过程。
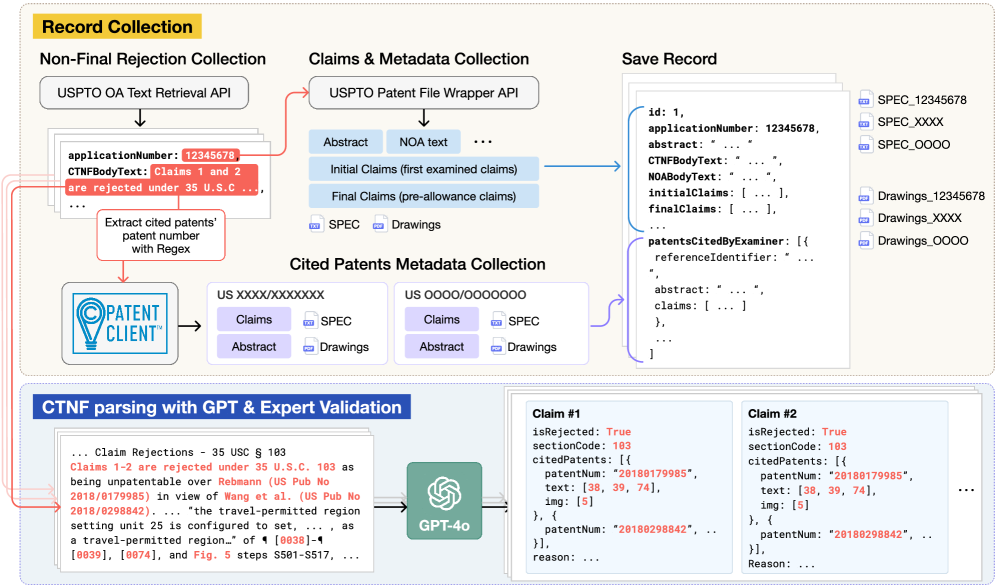
关键设计:PANORAMA数据集的设计重点在于模拟真实的专利审查流程。数据集中的每个步骤都对应一个实际的审查任务,例如检索相关现有技术、定位相关段落、评估专利权利要求的新颖性和非显而易见性。数据集还包含了审查意见书中的理由,这有助于研究人员更好地理解审查员的决策过程。数据集的构建过程中,作者们仔细地处理了数据,确保数据的质量和一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在检索相关现有技术和定位相关段落方面表现相对较好,但在评估专利权利要求的新颖性和非显而易见性方面存在困难。这表明,在专利领域应用NLP技术,需要更深入地理解专利审查的本质,并开发更有效的模型来模拟审查员的决策过程。
🎯 应用场景
PANORAMA数据集可用于训练和评估NLP模型在专利审查领域的应用,例如辅助专利检索、自动生成审查意见书、预测专利授权结果等。该数据集有助于提高专利审查的效率和质量,并促进专利领域的创新。
📄 摘要(原文)
Patent examination remains an ongoing challenge in the NLP literature even after the advent of large language models (LLMs), as it requires an extensive yet nuanced human judgment on whether a submitted claim meets the statutory standards of novelty and non-obviousness against previously granted claims -- prior art -- in expert domains. Previous NLP studies have approached this challenge as a prediction task (e.g., forecasting grant outcomes) with high-level proxies such as similarity metrics or classifiers trained on historical labels. However, this approach often overlooks the step-by-step evaluations that examiners must make with profound information, including rationales for the decisions provided in office actions documents, which also makes it harder to measure the current state of techniques in patent review processes. To fill this gap, we construct PANORAMA, a dataset of 8,143 U.S. patent examination records that preserves the full decision trails, including original applications, all cited references, Non-Final Rejections, and Notices of Allowance. Also, PANORAMA decomposes the trails into sequential benchmarks that emulate patent professionals' patent review processes and allow researchers to examine large language models' capabilities at each step of them. Our findings indicate that, although LLMs are relatively effective at retrieving relevant prior art and pinpointing the pertinent paragraphs, they struggle to assess the novelty and non-obviousness of patent claims. We discuss these results and argue that advancing NLP, including LLMs, in the patent domain requires a deeper understanding of real-world patent examination. Our dataset is openly available at https://huggingface.co/datasets/LG-AI-Research/PANORAMA.