Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
作者: Federica Gamba, Aman Sinha, Timothee Mickus, Raul Vazquez, Patanjali Bhamidipati, Claudio Savelli, Ahana Chattopadhyay, Laura A. Zanella, Yash Kankanampati, Binesh Arakkal Remesh, Aryan Ashok Chandramania, Rohit Agarwal, Chuyuan Li, Ioana Buhnila, Radhika Mamidi
分类: cs.CL
发布日期: 2025-10-25
💡 一句话要点
提出CAP数据集,用于检测科学文本生成中大型语言模型的幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学文本生成 大型语言模型 幻觉检测 多语种 数据集
📋 核心要点
- 大型语言模型在科学文本生成中存在幻觉问题,导致事实性错误,尤其是在专业术语和复杂推理的场景下。
- CAP数据集旨在提供一个多语种的、带有标注的科学问答数据集,用于训练和评估LLM的幻觉检测能力。
- 该数据集包含9种语言,涵盖高资源和低资源语种,并提供了token序列和logits等信息,便于深入分析。
📝 摘要(中文)
本文介绍了CAP(Confabulations from ACL Publications)数据集,这是一个多语种资源,用于研究大型语言模型(LLM)在科学文本生成中的幻觉问题。CAP关注科学领域,该领域中幻觉会扭曲事实知识。然而,在这个领域中,专业术语、统计推理和上下文相关的解释进一步加剧了这些扭曲,特别是考虑到LLM缺乏真正的理解、有限的上下文理解以及对表面泛化的偏见。CAP在跨语言环境中运行,涵盖五种高资源语言(英语、法语、印地语、意大利语和西班牙语)和四种低资源语言(孟加拉语、古吉拉特语、马拉雅拉姆语和泰卢固语)。该数据集包含900个精心策划的科学问题和来自16个公开模型的7000多个LLM生成的答案,以问答对的形式提供,以及token序列和相应的logits。每个实例都用一个二元标签进行注释,指示是否存在科学幻觉(表示为事实性错误),以及一个流畅性标签,捕捉文本的语言质量或自然性问题。CAP公开发布,以促进对幻觉检测、LLM的多语言评估以及更可靠的科学NLP系统开发的深入研究。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成科学文本时出现的幻觉问题,即生成不符合事实或与原文不一致的内容。现有方法难以有效检测和缓解这些幻觉,尤其是在涉及专业术语、统计推理和上下文依赖的科学领域。现有数据集通常缺乏科学领域的针对性,且多为单语种,难以满足多语言环境下的需求。
核心思路:论文的核心思路是构建一个高质量、多语种的科学问答数据集,并对每个答案进行幻觉标注。通过这个数据集,可以训练和评估LLM的幻觉检测能力,并促进更可靠的科学NLP系统的开发。数据集的设计考虑了科学领域的特殊性,包括专业术语、统计推理和上下文依赖,从而更有效地捕捉和评估LLM的幻觉行为。
技术框架:CAP数据集的构建流程主要包括以下几个阶段:1) 从ACL出版物中选取科学文本;2) 基于选取的文本,人工编写科学问题;3) 使用多个LLM生成针对这些问题的答案;4) 对生成的答案进行人工标注,标注其是否包含幻觉(事实性错误)以及流畅性。数据集以问答对的形式提供,同时包含token序列和相应的logits,便于进行更深入的分析。
关键创新:CAP数据集的关键创新在于其专注于科学领域,并提供多语种的标注数据。与现有数据集相比,CAP更贴近实际应用场景,能够更有效地评估LLM在科学文本生成中的幻觉问题。此外,CAP数据集还提供了token序列和logits等信息,为研究人员提供了更丰富的分析维度。
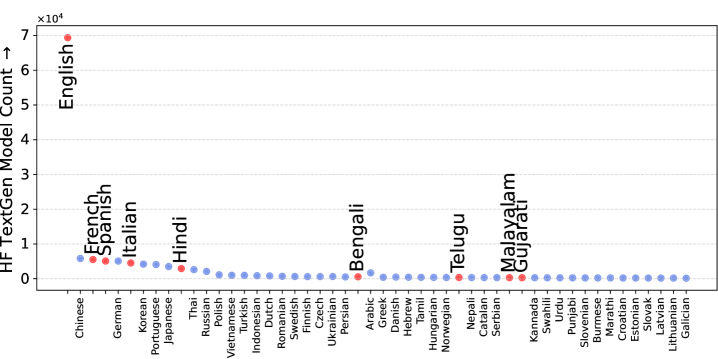
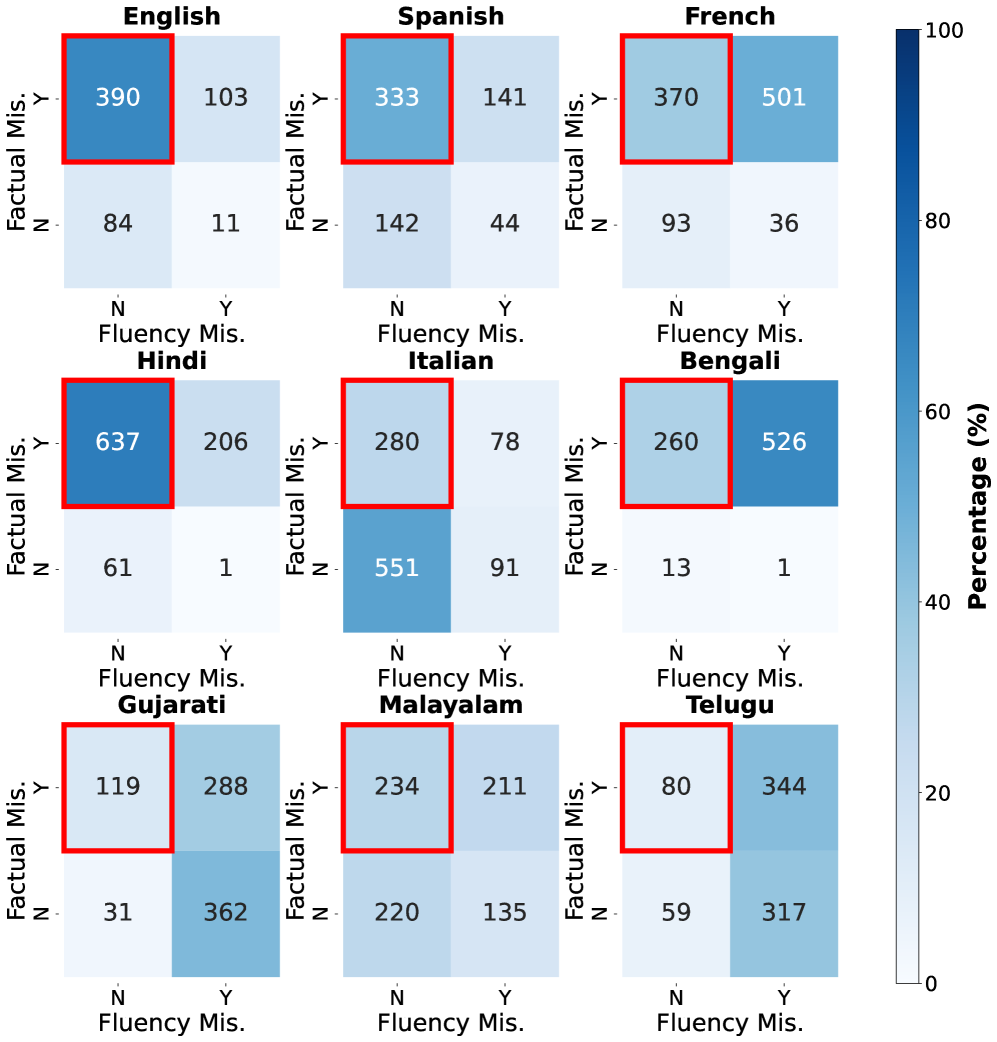
关键设计:CAP数据集包含9种语言,包括5种高资源语言(英语、法语、印地语、意大利语和西班牙语)和4种低资源语言(孟加拉语、古吉拉特语、马拉雅拉姆语和泰卢固语)。数据集共包含900个问题和7000多个LLM生成的答案。每个答案都经过人工标注,标注其是否包含幻觉(二元标签)以及流畅性。标注人员需要具备一定的科学背景知识,以确保标注的准确性。
🖼️ 关键图片

📊 实验亮点
CAP数据集包含来自16个公开LLM的7000多个答案,覆盖9种语言,为多语言幻觉检测提供了丰富的资源。该数据集的标注质量经过严格控制,确保了标注的准确性和一致性。通过该数据集,研究人员可以深入分析LLM在科学文本生成中的幻觉行为,并开发更有效的幻觉检测和缓解方法。
🎯 应用场景
CAP数据集可用于训练和评估大型语言模型在科学文本生成中的可靠性,提高科学文献检索、自动摘要、机器翻译等应用的质量。该数据集还有助于开发更可靠的科学NLP系统,减少错误信息的传播,并促进科学研究的进步。
📄 摘要(原文)
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.