VisJudge-Bench: Aesthetics and Quality Assessment of Visualizations
作者: Yupeng Xie, Zhiyang Zhang, Yifan Wu, Sirong Lu, Jiayi Zhang, Zhaoyang Yu, Jinlin Wang, Sirui Hong, Bang Liu, Chenglin Wu, Yuyu Luo
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-10-25 (更新: 2026-01-31)
备注: 62 pages, 27 figures, 8 tables. Accepted at ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出VisJudge-Bench,用于评估多模态大语言模型在可视化美学和质量评估方面的能力,并提出VisJudge模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可视化评估 多模态大语言模型 基准数据集 美学评估 质量评估
📋 核心要点
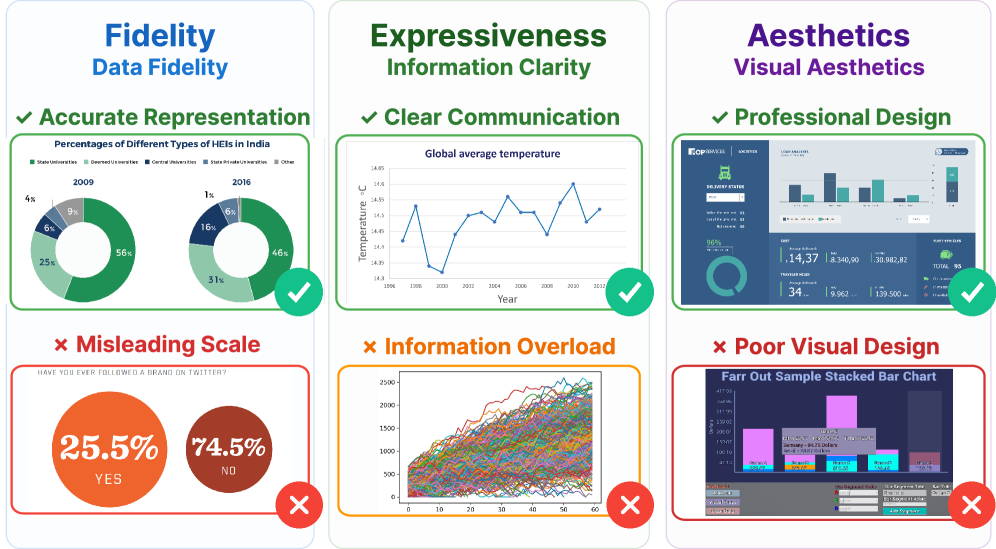
- 现有方法难以同时评估可视化数据编码准确性、信息表达和视觉美学,缺乏针对可视化评估的基准。
- 提出VisJudge-Bench基准,包含3090个专家标注的真实可视化样本,涵盖多种图表类型和场景。
- 提出VisJudge模型,专门用于可视化美学和质量评估,显著提升了与人类判断的一致性,降低了误差。
📝 摘要(中文)
可视化是一种领域特定但应用广泛的图像形式,它能有效地将复杂数据集转化为直观的见解。可视化的价值取决于数据是否被忠实地表示、清晰地传达以及美观地设计。然而,评估可视化质量具有挑战性:与自然图像不同,它需要同时判断数据编码的准确性、信息表达的有效性和视觉美学。尽管多模态大语言模型(MLLM)在自然图像的美学评估中表现出良好的性能,但目前还没有系统的基准来衡量它们在评估可视化方面的能力。为了解决这个问题,我们提出了VisJudge-Bench,这是第一个用于评估MLLM在可视化美学和质量评估方面性能的综合基准。它包含来自真实场景的3090个专家标注样本,涵盖32种图表类型的单个可视化、多个可视化和仪表板。对该基准的系统测试表明,即使是最先进的MLLM(如GPT-5)在判断方面与人类专家相比仍然存在显著差距,平均绝对误差(MAE)为0.553,与人类评分的相关性仅为0.428。为了解决这个问题,我们提出了VisJudge,一个专门为可视化美学和质量评估设计的模型。实验结果表明,与GPT-5相比,VisJudge显著缩小了与人类判断的差距,将MAE降低到0.421(降低了23.9%),并将与人类专家的一致性提高到0.687(提高了60.5%)。该基准可在https://github.com/HKUSTDial/VisJudgeBench获取。
🔬 方法详解
问题定义:现有方法在评估可视化质量时,难以兼顾数据编码的准确性、信息表达的有效性和视觉美学。此外,缺乏专门针对可视化评估的基准数据集,使得多模态大语言模型(MLLM)在这一领域的性能难以有效衡量和提升。现有MLLM在可视化评估任务中与人类专家存在显著差距,表明其在理解和评估可视化方面的能力仍有不足。
核心思路:论文的核心思路是构建一个专门用于评估MLLM在可视化美学和质量评估方面能力的基准数据集VisJudge-Bench,并在此基础上提出一个针对可视化评估任务定制的模型VisJudge。VisJudge的设计目标是缩小MLLM与人类专家在可视化评估方面的差距,提高评估的准确性和一致性。
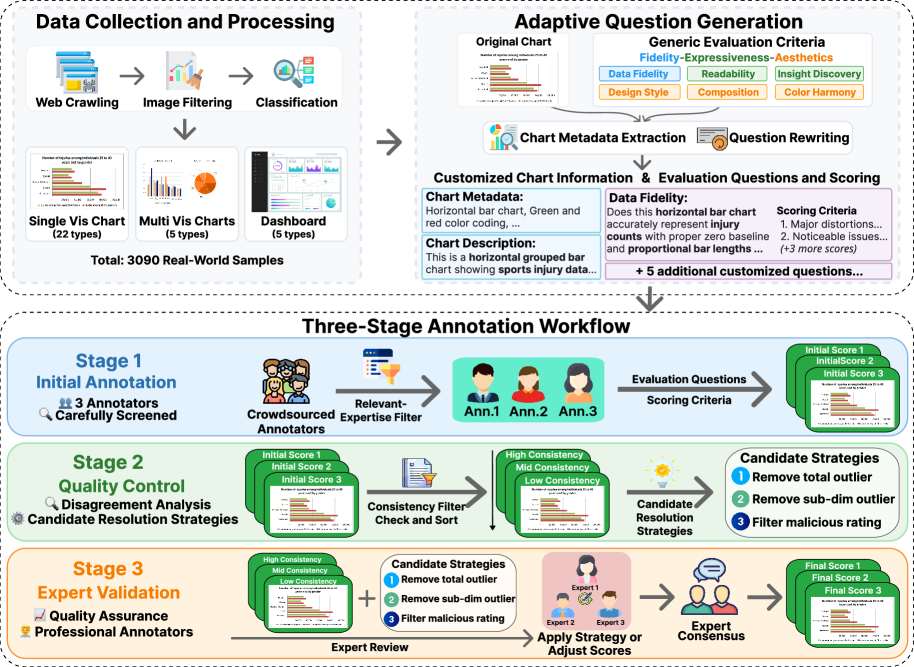
技术框架:VisJudge-Bench基准包含3090个专家标注的真实可视化样本,涵盖32种图表类型,包括单个可视化、多个可视化和仪表板。VisJudge模型(具体架构未知,论文中未详细描述)利用该基准进行训练和评估,旨在学习人类专家对可视化质量的判断标准。整体流程包括:数据收集与标注、基准数据集构建、模型设计与训练、以及性能评估与比较。
关键创新:论文的关键创新在于:1) 提出了首个针对可视化美学和质量评估的综合基准VisJudge-Bench,填补了该领域的空白;2) 设计了专门用于可视化评估的VisJudge模型,该模型在与人类判断的一致性方面取得了显著提升。
关键设计:论文中没有详细描述VisJudge模型的具体网络结构、损失函数或参数设置。但实验结果表明,该模型在VisJudge-Bench基准上取得了优于现有MLLM(如GPT-5)的性能,表明其在设计上考虑了可视化数据的特点,并有效地学习了人类专家的评估标准。具体的技术细节(如损失函数、网络结构等)未知。
🖼️ 关键图片

📊 实验亮点
VisJudge模型在VisJudge-Bench基准测试中,相较于GPT-5,平均绝对误差(MAE)降低了23.9%(从0.553降至0.421),与人类专家的一致性提高了60.5%(从0.428提升至0.687)。这些数据表明VisJudge在可视化美学和质量评估方面取得了显著的性能提升,更接近人类专家的判断。
🎯 应用场景
该研究成果可应用于自动化数据可视化质量评估、可视化设计辅助、以及提升数据分析报告的可读性和美观性。通过自动评估可视化质量,可以帮助用户快速发现和改进可视化设计中的问题,从而提高数据沟通的效率和效果。未来,该技术还可应用于智能报表生成、数据新闻等领域。
📄 摘要(原文)
Visualization, a domain-specific yet widely used form of imagery, is an effective way to turn complex datasets into intuitive insights, and its value depends on whether data are faithfully represented, clearly communicated, and aesthetically designed. However, evaluating visualization quality is challenging: unlike natural images, it requires simultaneous judgment across data encoding accuracy, information expressiveness, and visual aesthetics. Although multimodal large language models (MLLMs) have shown promising performance in aesthetic assessment of natural images, no systematic benchmark exists for measuring their capabilities in evaluating visualizations. To address this, we propose VisJudge-Bench, the first comprehensive benchmark for evaluating MLLMs' performance in assessing visualization aesthetics and quality. It contains 3,090 expert-annotated samples from real-world scenarios, covering single visualizations, multiple visualizations, and dashboards across 32 chart types. Systematic testing on this benchmark reveals that even the most advanced MLLMs (such as GPT-5) still exhibit significant gaps compared to human experts in judgment, with a Mean Absolute Error (MAE) of 0.553 and a correlation with human ratings of only 0.428. To address this issue, we propose VisJudge, a model specifically designed for visualization aesthetics and quality assessment. Experimental results demonstrate that VisJudge significantly narrows the gap with human judgment, reducing the MAE to 0.421 (a 23.9% reduction) and increasing the consistency with human experts to 0.687 (a 60.5% improvement) compared to GPT-5. The benchmark is available at https://github.com/HKUSTDial/VisJudgeBench.