FAIR-RAG: Faithful Adaptive Iterative Refinement for Retrieval-Augmented Generation
作者: Mohammad Aghajani Asl, Majid Asgari-Bidhendi, Behrooz Minaei-Bidgoli
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-10-25
备注: 30 pages, 5 figures, 5 tables. Keywords: Retrieval-Augmented Generation (RAG), Large Language Models (LLMs), Agentic AI, Multi-hop Question Answering, Faithfulness
💡 一句话要点
提出FAIR-RAG,通过可信自适应迭代优化检索增强生成,提升复杂问答任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多跳问答 证据评估 信息缺口识别 自适应查询优化
📋 核心要点
- 现有RAG方法在处理复杂多跳查询时,缺乏系统性识别和填补证据缺口的机制,导致信息不完整或引入噪声。
- FAIR-RAG通过结构化证据评估(SEA)模块驱动的迭代优化循环,显式识别信息缺口并生成针对性子查询。
- 实验表明,FAIR-RAG在HotpotQA等多跳QA基准上显著优于现有方法,F1分数提升8.3个点,达到SOTA。
📝 摘要(中文)
检索增强生成(RAG)缓解了大语言模型(LLM)中的幻觉和知识过时问题,但现有框架在处理需要综合来自不同来源信息的复杂多跳查询时常常失效。目前先进的RAG方法,采用迭代或自适应策略,缺乏稳健的机制来系统地识别和填补证据缺口,常常传播噪声或无法收集全面的上下文。我们引入FAIR-RAG,一种新型的agentic框架,将标准RAG流程转变为动态的、证据驱动的推理过程。其核心是由我们称之为结构化证据评估(SEA)的模块所控制的迭代优化循环。SEA作为一个分析门控机制:它将初始查询分解为所需发现的清单,并审计聚合的证据,以识别已确认的事实,以及关键的、明确的信息缺口。这些缺口为自适应查询优化代理提供精确的信号,该代理生成新的、有针对性的子查询来检索缺失的信息。这个循环重复进行,直到证据被验证为充分,确保为最终的、严格可信的生成提供全面的上下文。我们在具有挑战性的多跳QA基准上进行了实验,包括HotpotQA、2WikiMultiHopQA和MusiQue。在一个统一的实验设置中,FAIR-RAG显著优于强大的基线。在HotpotQA上,它实现了0.453的F1分数——比最强的迭代基线绝对提高了8.3个点——为这类方法在这些基准上建立了新的state-of-the-art。我们的工作表明,具有显式缺口分析的结构化、证据驱动的优化过程对于在复杂、知识密集型任务中解锁高级RAG系统中可靠和准确的推理至关重要。
🔬 方法详解
问题定义:论文旨在解决现有RAG系统在处理复杂多跳问答时,由于缺乏有效的证据评估和信息缺口识别机制,导致检索到的信息不完整、不准确,最终影响生成结果的质量和可信度的问题。现有方法要么无法充分利用多源信息,要么容易引入噪声,难以保证生成结果的可靠性。
核心思路:FAIR-RAG的核心思路是将RAG流程转化为一个动态的、证据驱动的推理过程。通过迭代地评估已检索到的证据,显式地识别信息缺口,并利用这些缺口生成更具针对性的查询,从而逐步完善证据链,最终生成更准确、更可信的答案。这种方法模拟了人类在解决复杂问题时的信息收集和推理过程。
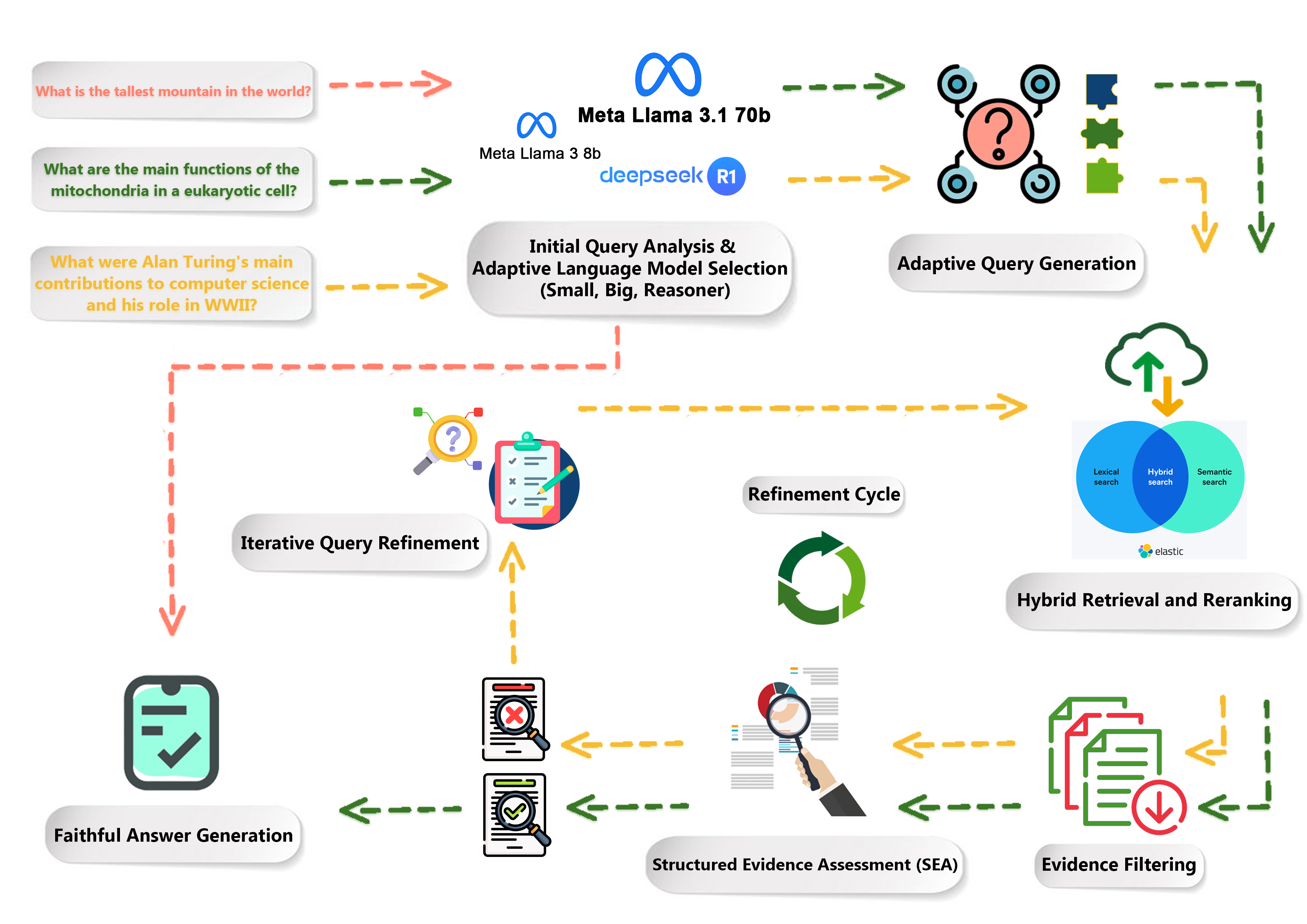
技术框架:FAIR-RAG的主要框架包含以下几个关键模块:1) 初始查询:接收用户提出的复杂问题。2) 结构化证据评估(SEA):将初始查询分解为一系列需要确认的事实清单,并评估已检索到的证据,识别已确认的事实和未确认的信息缺口。3) 自适应查询优化:根据SEA识别的信息缺口,生成新的、有针对性的子查询,以检索缺失的信息。4) 检索模块:使用生成的子查询从知识库中检索相关文档。5) 迭代循环:SEA、自适应查询优化和检索模块构成一个迭代循环,直到证据被验证为充分。6) 生成模块:基于最终的、全面的证据,生成答案。
关键创新:FAIR-RAG最重要的创新在于其结构化证据评估(SEA)模块,该模块能够显式地识别信息缺口,并利用这些缺口指导查询优化。与现有方法相比,FAIR-RAG不是盲目地进行迭代检索,而是有针对性地补充缺失的信息,从而提高了检索效率和生成结果的质量。
关键设计:SEA模块的设计是关键。具体实现细节未知,但可以推测其可能涉及自然语言推理、知识图谱等技术,用于判断已检索到的证据是否足以回答问题,以及识别需要补充的信息类型。自适应查询优化模块可能使用强化学习或生成模型来生成更有效的子查询。论文中未明确提及损失函数和网络结构等细节,这些可能是未来研究的方向。
🖼️ 关键图片

📊 实验亮点
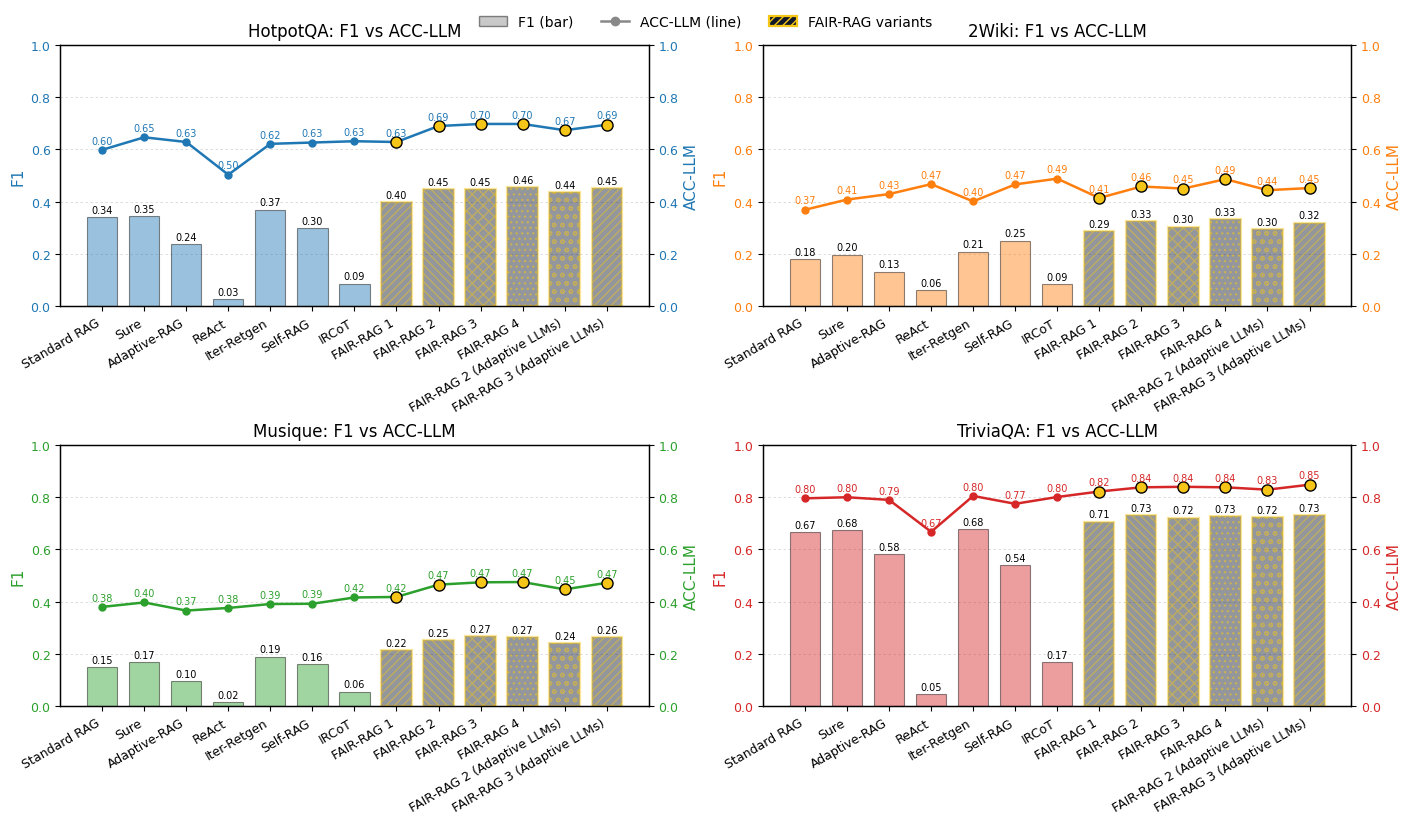
FAIR-RAG在HotpotQA、2WikiMultiHopQA和MusiQue等多个多跳QA基准上取得了显著的性能提升。在HotpotQA上,FAIR-RAG的F1分数达到了0.453,比最强的迭代基线提高了8.3个百分点,刷新了该类方法在该基准上的SOTA。实验结果表明,FAIR-RAG能够更有效地处理复杂的多跳查询,并生成更准确、更可信的答案。
🎯 应用场景
FAIR-RAG可应用于需要高度可信度和准确性的知识密集型任务,例如医疗诊断、法律咨询、金融分析等领域。通过提供更可靠的证据和更准确的答案,FAIR-RAG可以帮助专业人士做出更明智的决策,并提高工作效率。未来,该技术有望应用于智能客服、教育辅导等领域,为用户提供更优质的服务。
📄 摘要(原文)
While Retrieval-Augmented Generation (RAG) mitigates hallucination and knowledge staleness in Large Language Models (LLMs), existing frameworks often falter on complex, multi-hop queries that require synthesizing information from disparate sources. Current advanced RAG methods, employing iterative or adaptive strategies, lack a robust mechanism to systematically identify and fill evidence gaps, often propagating noise or failing to gather a comprehensive context. We introduce FAIR-RAG, a novel agentic framework that transforms the standard RAG pipeline into a dynamic, evidence-driven reasoning process. At its core is an Iterative Refinement Cycle governed by a module we term Structured Evidence Assessment (SEA). The SEA acts as an analytical gating mechanism: it deconstructs the initial query into a checklist of required findings and audits the aggregated evidence to identify confirmed facts and, critically, explicit informational gaps. These gaps provide a precise signal to an Adaptive Query Refinement agent, which generates new, targeted sub-queries to retrieve missing information. This cycle repeats until the evidence is verified as sufficient, ensuring a comprehensive context for a final, strictly faithful generation. We conducted experiments on challenging multi-hop QA benchmarks, including HotpotQA, 2WikiMultiHopQA, and MusiQue. In a unified experimental setup, FAIR-RAG significantly outperforms strong baselines. On HotpotQA, it achieves an F1-score of 0.453 -- an absolute improvement of 8.3 points over the strongest iterative baseline -- establishing a new state-of-the-art for this class of methods on these benchmarks. Our work demonstrates that a structured, evidence-driven refinement process with explicit gap analysis is crucial for unlocking reliable and accurate reasoning in advanced RAG systems for complex, knowledge-intensive tasks.