From Slides to Chatbots: Enhancing Large Language Models with University Course Materials
作者: Tu Anh Dinh, Philipp Nicolas Schumacher, Jan Niehues
分类: cs.CL
发布日期: 2025-10-25
💡 一句话要点
提出多模态检索增强生成方法以提升大学课程LLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 教育技术 多模态学习 检索增强生成 持续预训练 智能辅导系统 课程材料
📋 核心要点
- 现有的LLMs在大学计算机科学课程中回答问题的准确性不足,尤其是在处理多样化的课程材料时面临挑战。
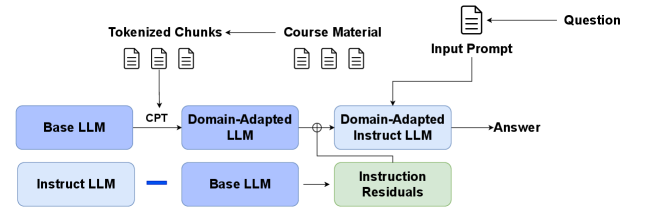
- 本文提出通过整合讲座幻灯片和转录文本,采用检索增强生成(RAG)和持续预训练(CPT)两种策略来提升LLM性能。
- 实验结果表明,RAG在处理小规模课程材料时更为高效,且多模态RAG方法在使用图像形式的幻灯片时显著提升了模型的表现。
📝 摘要(中文)
大型语言模型(LLMs)近年来发展迅速,已被应用于教育领域以支持学生学习。然而,现有研究表明,LLMs在大学计算机科学课程中回答问题的准确性仍然不足。本文探讨了如何通过整合大学课程材料来提升LLM在此场景中的表现。我们比较了两种策略:检索增强生成(RAG)和持续预训练(CPT),并在讲座幻灯片中进一步探索了多模态RAG方法。实验结果显示,考虑到大学课程材料的相对小规模,RAG在效率和效果上均优于CPT。此外,在多模态设置中将幻灯片作为图像纳入显著提升了性能。这些发现为开发更有效的AI助手提供了实用策略,旨在更好地支持学习和教学。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在大学课程材料中回答问题的准确性不足的问题。现有方法在处理多样化的课程材料(如幻灯片和转录文本)时,常常无法有效提取关键信息,导致回答质量不高。
核心思路:论文提出通过整合大学课程材料,采用检索增强生成(RAG)和持续预训练(CPT)两种策略,以提升LLM的性能。特别是在处理讲座幻灯片时,采用多模态RAG方法,将图像内容纳入生成过程,以更好地利用视觉信息。
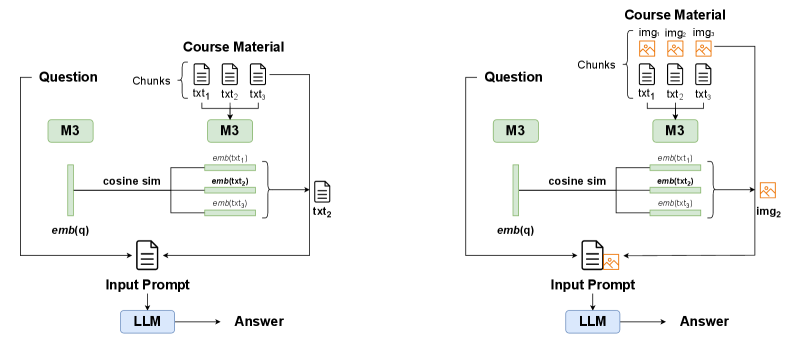
技术框架:整体架构包括两个主要模块:信息检索模块和生成模块。信息检索模块负责从课程材料中提取相关内容,而生成模块则基于检索到的信息生成回答。多模态RAG方法在此基础上进一步引入图像数据,增强生成模型的输入。
关键创新:最重要的技术创新在于将多模态信息(图像和文本)结合到RAG框架中,显著提升了模型在处理复杂课程材料时的表现。这一方法与传统的文本-only检索方法有本质区别,能够更全面地利用课程材料中的信息。
关键设计:在参数设置上,模型采用了适应性学习率和多层次的损失函数,以平衡文本和图像信息的贡献。此外,网络结构上引入了卷积神经网络(CNN)来处理图像数据,并与文本生成网络相结合,形成一个端到端的多模态生成框架。
🖼️ 关键图片

📊 实验亮点
实验结果显示,RAG方法在处理大学课程材料时比CPT更为高效,且在多模态设置中使用图像形式的幻灯片时,模型性能显著提升,具体提升幅度未知。这些结果为开发更智能的教育AI助手提供了重要依据。
🎯 应用场景
该研究的潜在应用领域包括教育技术、在线学习平台和智能辅导系统。通过提升大型语言模型在大学课程材料中的表现,可以为学生提供更准确的学习支持,帮助他们更好地理解复杂概念。此外,这一方法也可以推广到其他学科和教育场景,促进个性化学习和教学效果的提升。
📄 摘要(原文)
Large Language Models (LLMs) have advanced rapidly in recent years. One application of LLMs is to support student learning in educational settings. However, prior work has shown that LLMs still struggle to answer questions accurately within university-level computer science courses. In this work, we investigate how incorporating university course materials can enhance LLM performance in this setting. A key challenge lies in leveraging diverse course materials such as lecture slides and transcripts, which differ substantially from typical textual corpora: slides also contain visual elements like images and formulas, while transcripts contain spoken, less structured language. We compare two strategies, Retrieval-Augmented Generation (RAG) and Continual Pre-Training (CPT), to extend LLMs with course-specific knowledge. For lecture slides, we further explore a multi-modal RAG approach, where we present the retrieved content to the generator in image form. Our experiments reveal that, given the relatively small size of university course materials, RAG is more effective and efficient than CPT. Moreover, incorporating slides as images in the multi-modal setting significantly improves performance over text-only retrieval. These findings highlight practical strategies for developing AI assistants that better support learning and teaching, and we hope they inspire similar efforts in other educational contexts.