SteerX: Disentangled Steering for LLM Personalization
作者: Xiaoyan Zhao, Ming Yan, Yilun Qiu, Haoting Ni, Yang Zhang, Fuli Feng, Hong Cheng, Tat-Seng Chua
分类: cs.CL
发布日期: 2025-10-25
💡 一句话要点
SteerX:用于LLM个性化的解耦引导方法,提升用户偏好对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化 激活引导 因果推断 解耦学习
📋 核心要点
- 现有激活引导方法依赖所有历史数据计算引导向量,忽略了部分内容与用户偏好无关,导致个性化效果不佳。
- SteerX通过解耦偏好驱动和偏好无关的组件,并利用token级别的因果效应来识别关键偏好信息,从而提升引导向量的质量。
- 实验表明,SteerX在真实数据集上显著提升了现有引导方法的性能,为LLM个性化提供了一种有效途径。
📝 摘要(中文)
大型语言模型(LLM)近年来取得了显著成功,广泛应用于包括智能助手在内的各种场景。构建此类助手的关键因素之一是个性化LLM,因为用户偏好和需求差异很大。激活引导是一种经济有效的方法,它直接利用LLM激活空间中代表用户偏好的方向来调整其行为,从而使模型的输出与个体用户对齐。然而,现有方法依赖于所有历史数据来计算引导向量,忽略了并非所有内容都反映真实用户偏好,这削弱了个性化信号。为了解决这个问题,我们提出了SteerX,一种解耦引导方法,它将偏好驱动的组件与偏好无关的组件隔离。基于因果推断理论,SteerX估计token级别的因果效应,以识别偏好驱动的token,将这些离散信号转换为连贯的描述,然后利用它们来引导个性化的LLM生成。通过专注于真正偏好驱动的信息,SteerX产生更准确的激活引导向量,并增强个性化。在真实世界数据集上对两种代表性的引导骨干方法进行的实验表明,SteerX始终提高引导向量质量,为更有效的LLM个性化提供了一种实用的解决方案。
🔬 方法详解
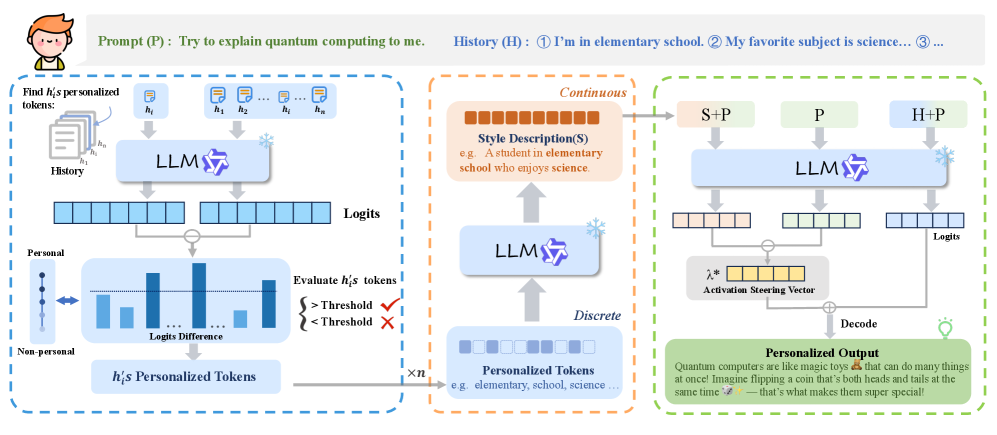
问题定义:现有激活引导方法在进行LLM个性化时,直接利用所有历史数据计算引导向量,没有区分用户偏好相关和无关的信息。这导致引导向量包含噪声,无法准确反映用户的真实偏好,从而影响LLM的个性化效果。现有方法缺乏对用户偏好细粒度的理解和建模,无法有效提取和利用关键的偏好信号。
核心思路:SteerX的核心思路是将LLM的激活空间解耦为偏好驱动和偏好无关两个部分。通过识别和提取偏好驱动的激活,可以更准确地构建引导向量,从而更好地控制LLM的生成行为,使其更符合用户的个性化需求。这种解耦的思想能够有效过滤噪声,突出关键的偏好信息。
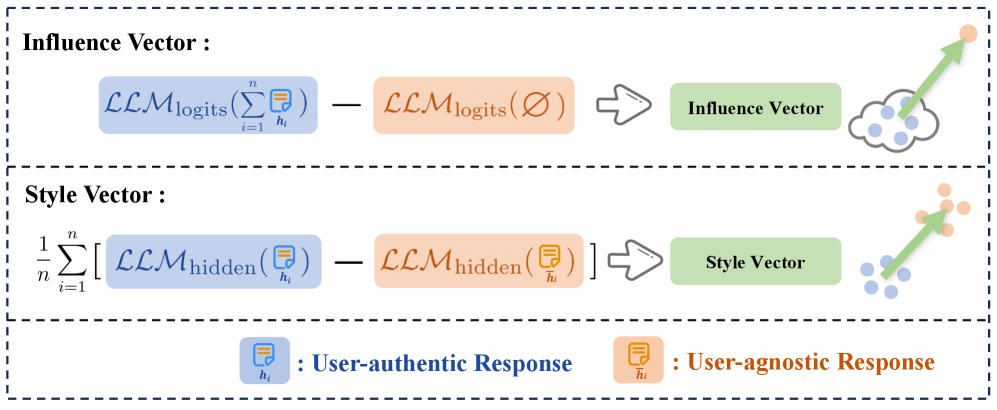
技术框架:SteerX的技术框架主要包含以下几个阶段:1) 因果效应估计:利用因果推断理论,估计每个token对用户偏好的因果效应,从而识别偏好驱动的token。2) 偏好信号转换:将离散的token级别偏好信号转换为连贯的描述,例如通过注意力机制或嵌入表示。3) 激活引导:利用提取的偏好信息,构建激活引导向量,并将其应用于LLM的激活空间,从而控制LLM的生成行为。
关键创新:SteerX的关键创新在于其解耦引导的思想和token级别的因果效应估计方法。与现有方法直接使用所有历史数据不同,SteerX能够识别和提取关键的偏好信息,从而更准确地构建引导向量。这种方法能够有效过滤噪声,突出关键的偏好信号,从而提升LLM的个性化效果。
关键设计:SteerX的关键设计包括:1) 使用因果推断模型(如DoWhy)来估计token级别的因果效应。2) 设计合适的损失函数来训练因果效应估计模型,例如使用对比学习或交叉熵损失。3) 使用注意力机制或嵌入表示来将离散的token级别偏好信号转换为连贯的描述。4) 设计合适的引导策略,例如线性组合或非线性变换,将激活引导向量应用于LLM的激活空间。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SteerX在两个真实世界数据集上,对两种代表性的引导骨干方法均取得了显著提升。具体来说,SteerX能够提高引导向量的质量,从而使LLM生成更符合用户偏好的内容。量化指标显示,SteerX在个性化任务上的性能优于现有方法,证明了其有效性。
🎯 应用场景
SteerX可应用于各种需要LLM个性化的场景,例如智能助手、个性化推荐、内容生成等。通过更准确地捕捉用户偏好,SteerX可以使LLM生成更符合用户需求的内容,提升用户体验。未来,SteerX可以进一步扩展到多模态场景,例如结合图像、音频等信息,实现更全面的个性化。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable success in recent years, enabling a wide range of applications, including intelligent assistants that support users' daily life and work. A critical factor in building such assistants is personalizing LLMs, as user preferences and needs vary widely. Activation steering, which directly leverages directions representing user preference in the LLM activation space to adjust its behavior, offers a cost-effective way to align the model's outputs with individual users. However, existing methods rely on all historical data to compute the steering vector, ignoring that not all content reflects true user preferences, which undermines the personalization signal. To address this, we propose SteerX, a disentangled steering method that isolates preference-driven components from preference-agnostic components. Grounded in causal inference theory, SteerX estimates token-level causal effects to identify preference-driven tokens, transforms these discrete signals into a coherent description, and then leverages them to steer personalized LLM generation. By focusing on the truly preference-driven information, SteerX produces more accurate activation steering vectors and enhances personalization. Experiments on two representative steering backbone methods across real-world datasets demonstrate that SteerX consistently enhances steering vector quality, offering a practical solution for more effective LLM personalization.