Estimating the Error of Large Language Models at Pairwise Text Comparison
作者: Tianyi Li
分类: cs.CL, cs.AI, math.PR
发布日期: 2025-10-25
备注: 14 pages, 6 figures
💡 一句话要点
提出一种无需ground truth的成对文本比较中大语言模型误差估计方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 误差估计 成对文本比较 位置偏差 Copeland计数
📋 核心要点
- 现有成对文本比较方法依赖ground truth,难以评估LLM的内在误差。
- 提出一种无需ground truth的误差估计方法,通过分析LLM在不同顺序比较中的偏好差异来推断误差。
- 实验表明,该方法能有效估计多种LLM在不同文本输入下的误差率,并发现Claude表现最佳。
📝 摘要(中文)
本文研究了大语言模型(LLM)在成对文本比较中的输出误差,关注其偏好判断的错误概率。该方法不依赖于ground truth,并支持两种场景:(i) 统一误差率,即误差率与比较顺序无关,通过对每个文本对进行两次比较(交换文本顺序)来估计;(ii) 二元位置偏差,假设两种比较顺序具有不同的误差率,通过重复比较文本来估计。Copeland计数法从成对偏好构建文本排序;该排序揭示了基于LLM的成对比较的可扩展性较差,并有助于估计LLM的误差率。我们将该方法应用于六个LLM(ChatGPT、Claude、DeepSeek、Gemini、Grok、Qwen)和五种类型的文本输入,并获得了LLM误差的一致估计。总的来说,测量的两个位置偏差项相似,接近于统一误差。考虑到误差率和对提示变化的鲁棒性,Claude 在此实验中获得了最理想的性能。我们的模型在指示LLM在此任务中的误差方面优于有偏的Bradley-Terry模型和交换性得分。
🔬 方法详解
问题定义:论文旨在解决如何评估大语言模型(LLM)在成对文本比较任务中的误差问题。现有方法通常依赖于人工标注的ground truth,这在实际应用中成本高昂且难以扩展。此外,LLM在不同顺序的文本比较中可能存在偏好偏差,导致评估结果不准确。因此,需要一种无需ground truth且能考虑位置偏差的误差估计方法。
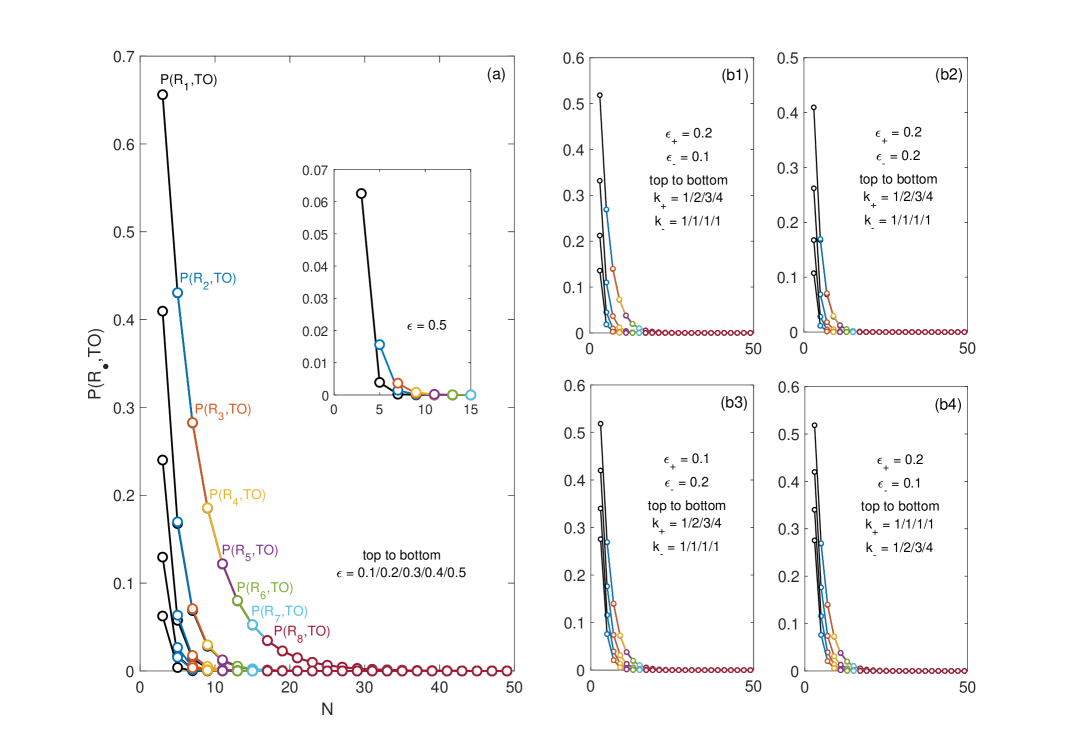
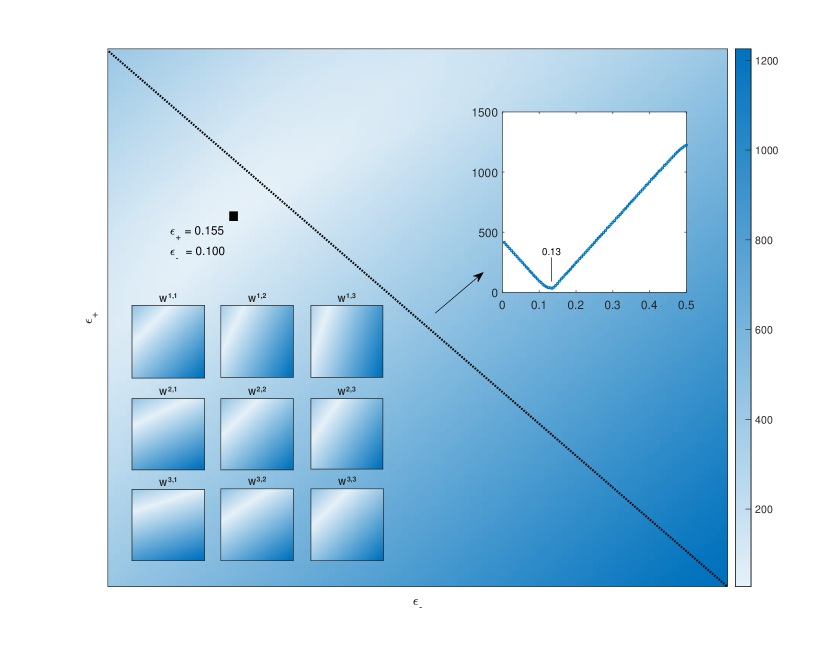
核心思路:论文的核心思路是通过分析LLM在不同顺序的成对文本比较中的偏好差异来推断其误差率。具体来说,如果LLM在交换文本顺序后给出了不同的偏好,则可能表明LLM存在误差。通过统计这种不一致性,可以估计LLM的误差率,而无需依赖ground truth。同时,论文还考虑了位置偏差,即LLM可能更倾向于选择第一个或第二个文本,并分别估计了两种顺序下的误差率。
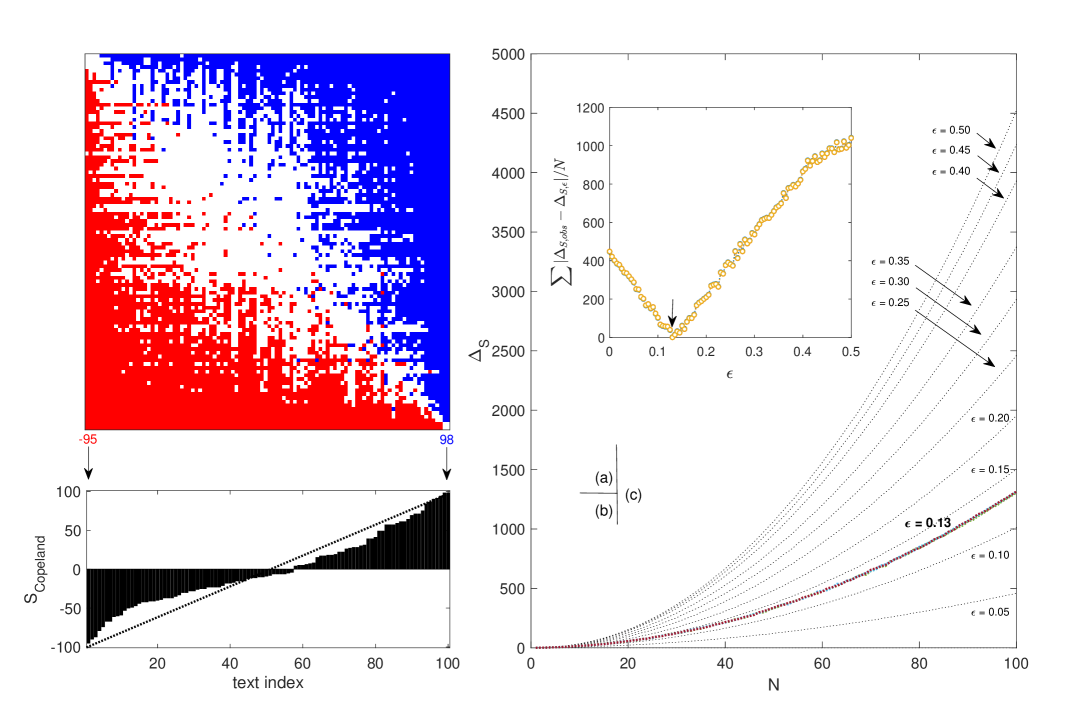
技术框架:该方法主要包含以下几个步骤:1) 选取一组文本对,并对每个文本对进行多次比较,每次比较时交换文本顺序。2) 记录LLM在每次比较中的偏好。3) 使用Copeland计数法从成对偏好构建文本排序。4) 基于LLM的排序结果,估计LLM的统一误差率或二元位置偏差误差率。5) 将估计的误差率与基线方法(如 biased Bradley-Terry 模型和 commutativity score)进行比较。
关键创新:该方法最重要的技术创新点在于提出了一种无需ground truth的LLM误差估计方法。与现有方法相比,该方法更加实用和可扩展,因为它不需要人工标注数据。此外,该方法还考虑了位置偏差,可以更准确地估计LLM的误差率。
关键设计:论文的关键设计包括:1) 使用Copeland计数法构建文本排序,该方法简单有效,且易于实现。2) 提出了两种误差估计模型:统一误差率模型和二元位置偏差模型,分别适用于不同的场景。3) 实验中选取了多种LLM和文本输入,以验证该方法的有效性和鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够一致地估计六个LLM(ChatGPT、Claude、DeepSeek、Gemini、Grok、Qwen)在五种文本输入下的误差。Claude在误差率和对提示变化的鲁棒性方面表现最佳。该方法在指示LLM误差方面优于有偏的Bradley-Terry模型和交换性得分。
🎯 应用场景
该研究成果可应用于评估和比较不同LLM在文本比较任务中的性能,帮助用户选择更可靠的LLM。此外,该方法还可以用于优化LLM的训练过程,提高其在文本比较任务中的准确性和鲁棒性。未来,该方法可以扩展到其他自然语言处理任务,如文本摘要、机器翻译等。
📄 摘要(原文)
We measure LLMs' output error at pairwise text comparison, noting the probability of error in their preferences. Our method does not rely on the ground truth and supports two scenarios: (i) uniform error rate regardless of the order of comparison, estimated with two comparisons for each text pair with either text placed first; (ii) binary positional bias assuming distinct error rates for the two orders of comparison, estimated with repeated comparisons between the texts. The Copeland counting constructs a ranking over the compared texts from pairwise preferences; the ranking reveals the poor scalability of LLM-based pairwise comparison and helps yield the estimates for LLMs' error rates. We apply the method to six LLMs (ChatGPT, Claude, DeepSeek, Gemini, Grok, Qwen) with five types of text input and obtain consistent estimates of LLMs' error. In general, the measured two positional bias terms are similar, close to the uniform error. Considering both the error rates and the robustness to the variation of prompts, Claude obtained the most desirable performance in this experiment. Our model outperforms the biased Bradley-Terry model and the commutativity score in indicating LLMs' error at this task.