DETECT: Determining Ease and Textual Clarity of German Text Simplifications
作者: Maria Korobeynikova, Alessia Battisti, Lukas Fischer, Yingqiang Gao
分类: cs.CL
发布日期: 2025-10-25
💡 一句话要点
提出DETECT:一种用于评估德语文本简化质量的指标,无需人工标注。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 德语文本简化 自动评估指标 大型语言模型 合成数据生成 意义保留 流畅性 简洁性 自然语言处理
📋 核心要点
- 现有德语文本简化评估依赖通用指标,无法充分衡量简洁性、意义保留和流畅性。
- DETECT通过LLM生成合成数据,无需人工标注,并使用LLM细化评分标准,适配德语环境。
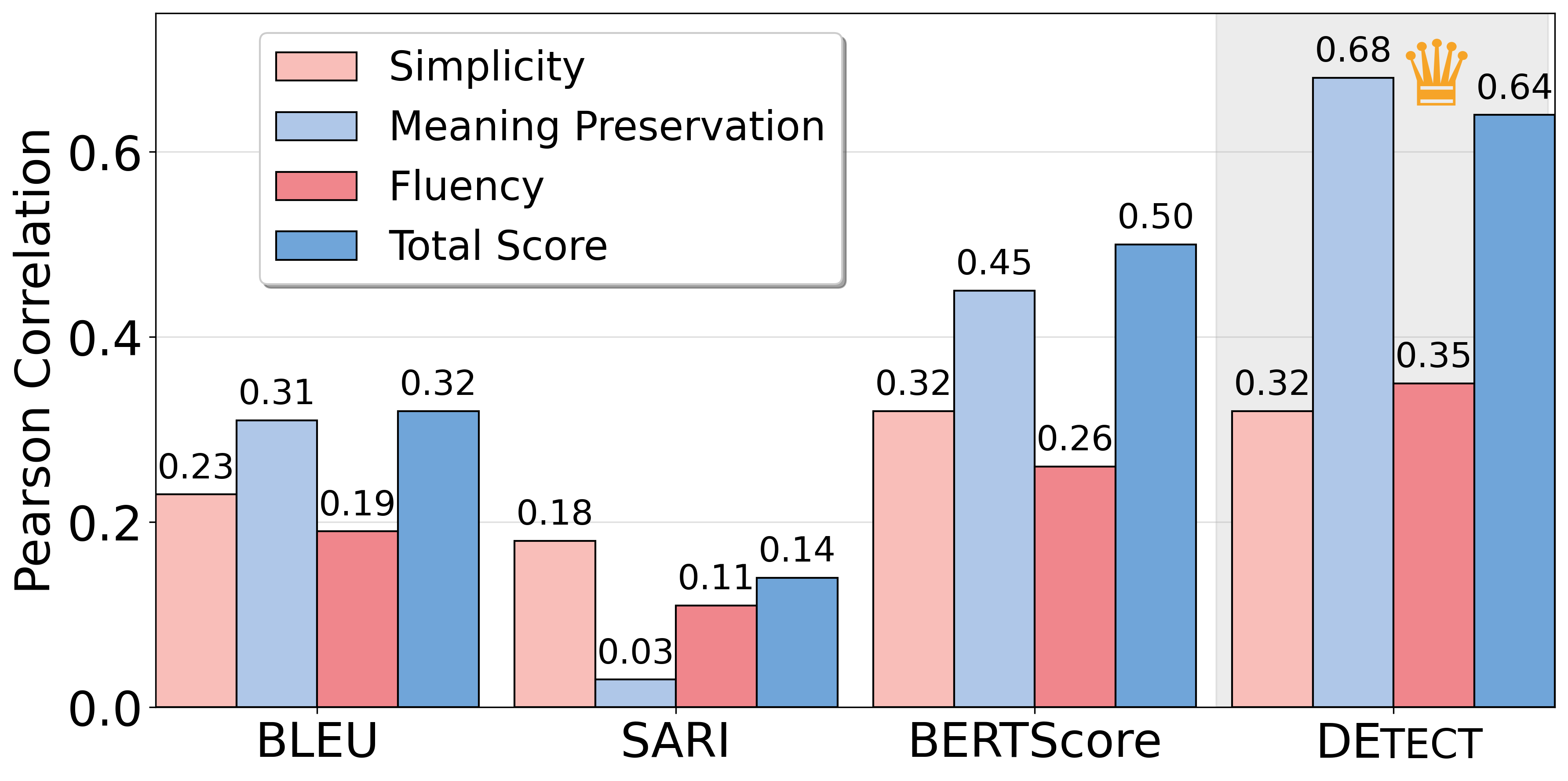
- 实验表明,DETECT与人工评估的相关性显著高于现有指标,尤其在意义保留和流畅性方面。
📝 摘要(中文)
当前对德语自动文本简化(ATS)的评估依赖于SARI、BLEU和BERTScore等通用指标,这些指标不足以捕捉简化质量在简洁性、意义保留和流畅性方面的表现。虽然像LENS这样的专用指标已经为英语开发出来,但由于缺乏人工标注的语料库,德语的相应工作滞后。为了弥合这一差距,我们引入了DETECT,这是第一个德语专用指标,它全面评估ATS质量的三个维度:简洁性、意义保留和流畅性,并且完全基于合成的大型语言模型(LLM)响应进行训练。我们的方法将LENS框架适配到德语,并通过以下方式扩展它:(i)一个通过LLM生成合成质量分数的管道,无需人工标注即可创建数据集,以及(ii)一个基于LLM的细化步骤,用于使评分标准与简化要求对齐。据我们所知,我们还构建了最大的德语人工评估数据集,用于直接验证我们的指标。实验结果表明,DETECT与人工判断的相关性明显高于广泛使用的ATS指标,尤其是在意义保留和流畅性方面有显著提高。除了ATS,我们的发现突出了LLM在自动评估中的潜力和局限性,并为通用语言可访问性任务提供了可转移的指导。
🔬 方法详解
问题定义:论文旨在解决德语自动文本简化(ATS)评估缺乏有效指标的问题。现有通用指标(如SARI、BLEU、BERTScore)无法准确反映简化文本的简洁性、意义保留和流畅性。缺乏人工标注数据阻碍了德语专用评估指标的发展。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成合成数据,并训练一个德语专用的评估指标DETECT。通过LLM自动生成质量评分,避免了耗时的人工标注。同时,使用LLM对评分标准进行细化,使其更符合文本简化的要求。
技术框架:DETECT的整体框架包括以下几个主要阶段:1) 使用LLM生成合成的文本简化数据及其质量评分;2) 基于合成数据训练DETECT模型;3) 使用LLM对DETECT模型的评分标准进行细化;4) 使用人工标注的德语文本简化数据集验证DETECT的性能。
关键创新:DETECT的关键创新在于:1) 提出了一种基于LLM的合成数据生成方法,无需人工标注即可构建大规模的德语文本简化评估数据集;2) 提出了一种基于LLM的评分标准细化方法,使评估指标更符合文本简化的要求;3) 构建了首个德语专用的文本简化评估指标,填补了该领域的空白。
关键设计:DETECT的具体实现细节包括:1) 使用预训练的德语LLM生成文本简化数据;2) 使用不同的prompt引导LLM生成不同质量的简化文本;3) 使用LLM对简化文本的简洁性、意义保留和流畅性进行评分;4) 使用回归模型训练DETECT,使其能够预测简化文本的质量评分;5) 使用人工标注数据对DETECT进行微调和验证。
🖼️ 关键图片


📊 实验亮点
DETECT在德语文本简化评估任务中取得了显著的性能提升。实验结果表明,DETECT与人工评估的相关性明显高于SARI、BLEU和BERTScore等通用指标,尤其是在意义保留和流畅性方面有显著提高。DETECT在人工评估数据集上的表现证明了其有效性和可靠性。
🎯 应用场景
DETECT可应用于德语自动文本简化系统的开发和评估,帮助研究人员和开发者快速评估不同简化算法的性能,并选择最佳的简化策略。该方法也可推广到其他低资源语言的文本简化评估任务中,促进语言可访问性的研究和应用。此外,基于LLM的合成数据生成和评分标准细化方法,为其他自然语言处理任务的自动评估提供了新的思路。
📄 摘要(原文)
Current evaluation of German automatic text simplification (ATS) relies on general-purpose metrics such as SARI, BLEU, and BERTScore, which insufficiently capture simplification quality in terms of simplicity, meaning preservation, and fluency. While specialized metrics like LENS have been developed for English, corresponding efforts for German have lagged behind due to the absence of human-annotated corpora. To close this gap, we introduce DETECT, the first German-specific metric that holistically evaluates ATS quality across all three dimensions of simplicity, meaning preservation, and fluency, and is trained entirely on synthetic large language model (LLM) responses. Our approach adapts the LENS framework to German and extends it with (i) a pipeline for generating synthetic quality scores via LLMs, enabling dataset creation without human annotation, and (ii) an LLM-based refinement step for aligning grading criteria with simplification requirements. To the best of our knowledge, we also construct the largest German human evaluation dataset for text simplification to validate our metric directly. Experimental results show that DETECT achieves substantially higher correlations with human judgments than widely used ATS metrics, with particularly strong gains in meaning preservation and fluency. Beyond ATS, our findings highlight both the potential and the limitations of LLMs for automatic evaluation and provide transferable guidelines for general language accessibility tasks.