Confidence is Not Competence
作者: Debdeep Sanyal, Manya Pandey, Dhruv Kumar, Saurabh Deshpande, Murari Mandal
分类: cs.CL, cs.AI
发布日期: 2025-10-24
备注: 20 Pages, 6 Figures, 8 Tables
💡 一句话要点
揭示大语言模型置信度与能力脱钩机制:几何复杂度差异解释
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 置信度校准 几何分析 因果干预 可解释性 双系统架构
📋 核心要点
- 大型语言模型(LLMs)的置信度与其解决问题的能力不匹配,这是一个亟待解决的问题。
- 论文通过分析LLM内部状态的几何结构,揭示了评估阶段和执行阶段几何复杂度的差异是导致置信度与能力脱钩的关键原因。
- 研究发现,对评估阶段的线性干预无法有效控制执行阶段的动态,表明需要针对执行过程进行干预。
📝 摘要(中文)
大型语言模型(LLMs)常常表现出一种令人困惑的现象:它们所声称的置信度与其解决问题的实际能力之间存在脱节。本文通过分析预生成评估和解决方案执行这两个阶段的内部状态几何结构,对这种脱钩现象提供了一种机制性的解释。一个简单的线性探针可以解码模型内部的“可解性信念”,揭示出一个良好排序的信念轴,该轴可以推广到不同的模型家族以及数学、代码、规划和逻辑任务。然而,几何结构却存在差异——尽管信念是线性可解码的,但评估流形的线性有效维度(通过主成分测量)很高,而随后的推理轨迹则在维度低得多的流形上演化。这种从思考到行动的几何复杂性急剧下降,从机制上解释了置信度与能力之间的差距。对沿信念轴引导表征的因果干预不会改变最终的解决方案,这表明复杂评估空间中的线性推动并不能控制执行的约束动态。因此,我们揭示了一种双系统架构——一个几何上复杂的评估器为几何上简单的执行器提供信息。这些结果挑战了可解码信念是可操作杠杆的假设,而是主张针对执行的程序动态进行干预,而不是针对高级评估几何结构。
🔬 方法详解
问题定义:大型语言模型在解决问题时,经常出现置信度很高但实际能力不足的情况,即“置信度与能力脱钩”。现有的方法难以解释这种现象背后的机制,无法有效提升LLM的可靠性。
核心思路:论文的核心思路是通过分析LLM内部状态的几何结构,区分“评估”和“执行”两个阶段,并研究这两个阶段的几何复杂度差异。作者认为,评估阶段的复杂性远高于执行阶段,导致模型对问题的“信念”与实际执行效果脱节。
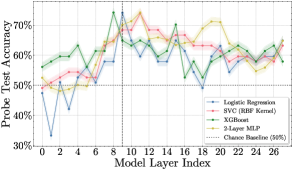
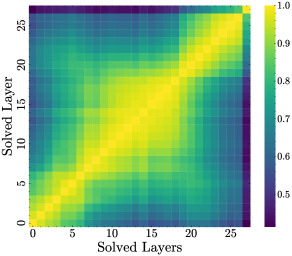
技术框架:论文的技术框架主要包含以下几个步骤: 1. 数据收集:收集LLM在解决不同类型任务(数学、代码、规划、逻辑)时的内部状态数据。 2. 信念解码:使用线性探针解码LLM内部的“可解性信念”,构建“信念轴”。 3. 几何分析:分析评估阶段和执行阶段的内部状态流形的几何结构,计算线性有效维度。 4. 因果干预:对评估阶段的内部状态进行因果干预,观察对最终解决方案的影响。
关键创新:论文最重要的技术创新在于揭示了LLM内部存在一个双系统架构:一个几何上复杂的评估器和一个几何上简单的执行器。评估器负责评估问题的可解性,而执行器负责实际解决问题。这两个系统的几何复杂度差异是导致置信度与能力脱钩的关键原因。与现有方法不同,该研究从几何角度分析了LLM的内部机制,为理解和解决置信度问题提供了新的视角。
关键设计: * 线性探针:使用简单的线性模型来解码LLM的内部状态,避免引入复杂的非线性变换。 * 线性有效维度:使用主成分分析(PCA)来计算内部状态流形的线性有效维度,衡量其复杂度。 * 因果干预:通过沿信念轴引导内部状态,来模拟对模型信念的干预,并观察其对最终解决方案的影响。
🖼️ 关键图片

📊 实验亮点
研究发现,LLM在评估阶段的线性有效维度远高于执行阶段,表明评估过程更加复杂。对评估阶段的线性干预无法有效改变最终解决方案,进一步证实了置信度与能力之间的脱钩。该研究结果在不同模型家族和多种任务上都具有泛化性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可靠性和可信度,例如在医疗诊断、金融风险评估等高风险领域,降低LLM出错带来的潜在风险。通过理解LLM的内部机制,可以设计更有效的干预策略,提高其解决问题的能力,并使其置信度与实际能力更加匹配。
📄 摘要(原文)
Large language models (LLMs) often exhibit a puzzling disconnect between their asserted confidence and actual problem-solving competence. We offer a mechanistic account of this decoupling by analyzing the geometry of internal states across two phases - pre-generative assessment and solution execution. A simple linear probe decodes the internal "solvability belief" of a model, revealing a well-ordered belief axis that generalizes across model families and across math, code, planning, and logic tasks. Yet, the geometries diverge - although belief is linearly decodable, the assessment manifold has high linear effective dimensionality as measured from the principal components, while the subsequent reasoning trace evolves on a much lower-dimensional manifold. This sharp reduction in geometric complexity from thought to action mechanistically explains the confidence-competence gap. Causal interventions that steer representations along the belief axis leave final solutions unchanged, indicating that linear nudges in the complex assessment space do not control the constrained dynamics of execution. We thus uncover a two-system architecture - a geometrically complex assessor feeding a geometrically simple executor. These results challenge the assumption that decodable beliefs are actionable levers, instead arguing for interventions that target the procedural dynamics of execution rather than the high-level geometry of assessment.