Optimal Detection for Language Watermarks with Pseudorandom Collision
作者: T. Tony Cai, Xiang Li, Qi Long, Weijie J. Su, Garrett G. Wen
分类: math.ST, cs.CL, cs.CR, cs.LG, stat.ML
发布日期: 2025-10-24
💡 一句话要点
针对语言水印检测中伪随机碰撞问题,提出最优检测框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言水印 伪随机碰撞 最优检测 最小单元 假设检验 大型语言模型 文本溯源
📋 核心要点
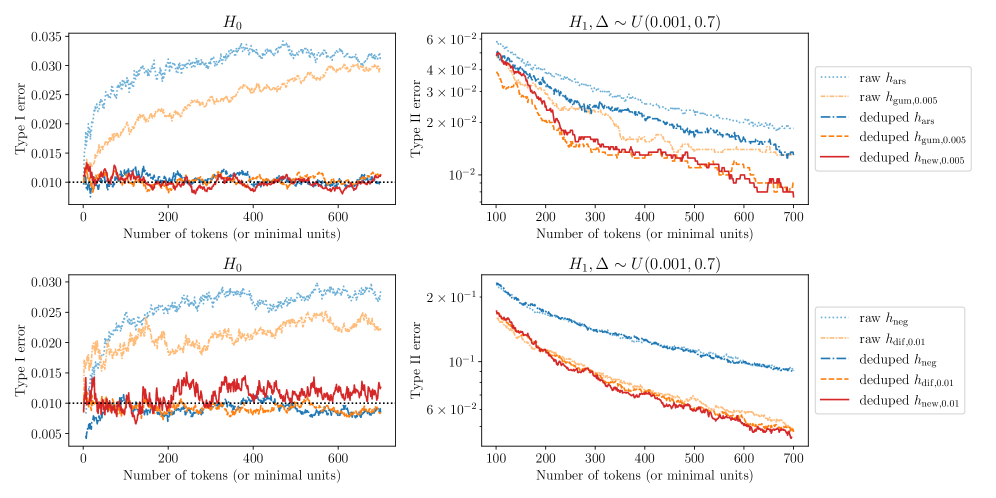
- 现有语言水印检测方法假设完美的伪随机性,但实际文本重复导致碰撞,影响检测的准确性。
- 论文提出基于最小单元的统计框架,通过分层划分捕获文本结构依赖,优化水印检测。
- 理论分析和实验结果表明,该框架能有效提高检测能力,并严格控制I类错误。
📝 摘要(中文)
文本水印在确保大型语言模型(LLM)输出的可追溯性和问责制以及减轻滥用方面起着关键作用。虽然现有方法很有前景,但大多数都假设完美的伪随机性。实际上,生成文本中的重复会导致碰撞,从而产生结构性依赖,损害I类错误控制并使标准分析失效。我们引入了一个统计框架,通过分层双层划分来捕获这种结构。其核心是最小单元的概念——可被视为跨单元独立,同时允许单元内依赖的最小组。利用最小单元,我们定义了一个非渐近效率度量,并将水印检测视为一个极小极大假设检验问题。应用于Gumbel-max和逆变换水印,我们的框架产生了闭式最优规则。它解释了为什么丢弃重复统计量通常会提高性能,并表明除非退化,否则必须解决单元内依赖性。理论和实验都证实了在严格的I类错误控制下检测能力的提高。这些结果为不完善的伪随机性下的水印检测提供了第一个原则性基础,为可靠地追踪模型输出提供了理论见解和实践指导。
🔬 方法详解
问题定义:现有语言水印检测方法在实际应用中面临伪随机性不完善的问题。由于生成文本中存在重复,导致水印嵌入和检测过程中出现碰撞,破坏了统计独立性假设,使得传统的基于完美伪随机性的分析方法失效,无法有效控制I类错误(误报率)。
核心思路:论文的核心思路是通过引入“最小单元”的概念,将文本划分为若干个可以近似视为独立的单元,并在单元内部允许一定的依赖关系。这样,就可以在考虑文本结构性依赖的同时,利用统计方法进行水印检测,从而提高检测的准确性和可靠性。
技术框架:该框架采用分层双层划分结构。第一层将文本划分为多个最小单元,每个单元内部允许一定的依赖关系。第二层则在每个最小单元内部进行更细粒度的划分,以便更好地建模单元内部的依赖结构。基于这种划分,论文定义了一个非渐近效率度量,并将水印检测问题转化为一个极小极大假设检验问题。
关键创新:该论文最重要的技术创新在于提出了基于“最小单元”的统计框架,能够有效地处理由于文本重复导致的伪随机碰撞问题。与现有方法相比,该框架能够更准确地建模文本的结构性依赖,从而提高水印检测的准确性和可靠性。此外,该框架还提供了闭式最优检测规则,便于实际应用。
关键设计:论文针对Gumbel-max和逆变换水印,推导出了闭式最优检测规则。这些规则考虑了最小单元内部的依赖关系,并根据具体的依赖结构进行了优化。此外,论文还探讨了丢弃重复统计量对检测性能的影响,并给出了相应的理论解释。关键参数包括最小单元的划分方式、单元内部依赖结构的建模方法以及假设检验的阈值设定。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架在Gumbel-max和逆变换水印检测中均取得了显著的性能提升。与现有方法相比,该框架能够更有效地控制I类错误,并在保证较低误报率的同时,提高检测的灵敏度。实验还验证了丢弃重复统计量能够提高检测性能的结论,并证实了考虑单元内依赖性的必要性。
🎯 应用场景
该研究成果可应用于各种需要对大型语言模型生成内容进行溯源和版权保护的场景,例如新闻生成、内容创作、代码生成等。通过有效的水印检测,可以追踪恶意使用LLM生成的内容,并对违规行为进行问责,从而促进LLM技术的健康发展。
📄 摘要(原文)
Text watermarking plays a crucial role in ensuring the traceability and accountability of large language model (LLM) outputs and mitigating misuse. While promising, most existing methods assume perfect pseudorandomness. In practice, repetition in generated text induces collisions that create structured dependence, compromising Type I error control and invalidating standard analyses. We introduce a statistical framework that captures this structure through a hierarchical two-layer partition. At its core is the concept of minimal units -- the smallest groups treatable as independent across units while permitting dependence within. Using minimal units, we define a non-asymptotic efficiency measure and cast watermark detection as a minimax hypothesis testing problem. Applied to Gumbel-max and inverse-transform watermarks, our framework produces closed-form optimal rules. It explains why discarding repeated statistics often improves performance and shows that within-unit dependence must be addressed unless degenerate. Both theory and experiments confirm improved detection power with rigorous Type I error control. These results provide the first principled foundation for watermark detection under imperfect pseudorandomness, offering both theoretical insight and practical guidance for reliable tracing of model outputs.