Model-Aware Tokenizer Transfer
作者: Mykola Haltiuk, Aleksander Smywiński-Pohl
分类: cs.CL
发布日期: 2025-10-24
💡 一句话要点
提出模型感知的分词器迁移方法MATT,提升低资源语言LLM性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分词器迁移 大型语言模型 注意力机制 低资源语言 知识迁移
📋 核心要点
- 现有分词器迁移方法依赖语义启发式,忽略了模型高层动态,导致迁移效果受限。
- MATT通过注意力影响建模(AIM)目标,将源模型的token间通信模式迁移到目标模型。
- 实验表明,MATT在多种语言环境下,能快速恢复原始模型性能,优于现有基线方法。
📝 摘要(中文)
大型语言模型(LLM)被训练以支持越来越多的语言,但其预定义的分词器仍然是将模型适配到低资源或不同脚本语言的瓶颈。现有的分词器迁移方法通常依赖于语义启发式方法来初始化新的嵌入,忽略了更高层的模型动态,从而限制了迁移质量。我们提出了一种模型感知的分词器迁移方法(MATT),该方法将模型内部信息纳入分词器迁移过程。MATT引入了一种注意力影响建模(AIM)目标,将源模型中的token间通信模式提炼到具有新分词器的目标模型中,在标准语言建模之前提供有效的预热。与仅关注嵌入相似性的方法不同,MATT利用注意力行为来指导嵌入初始化和适配。在各种语言环境下的实验表明,MATT在几个GPU小时内恢复了原始模型的大部分性能,优于启发式基线。这些结果表明,结合模型层面的信号为多语言LLM中鲁棒的分词器迁移提供了一条实用而有效的途径。
🔬 方法详解
问题定义:现有的分词器迁移方法主要依赖于语义启发式方法,例如使用预训练的词向量或词典来初始化新分词器的嵌入。这些方法忽略了大型语言模型(LLM)中更高层的模型动态,即token之间的复杂交互模式,导致迁移后的模型性能不佳,尤其是在低资源或不同脚本的语言上。因此,如何有效地将源模型中的知识迁移到具有新分词器的目标模型,同时考虑模型内部的token交互,是一个关键问题。
核心思路:MATT的核心思路是通过模仿源模型中token之间的注意力交互模式,来指导目标模型中新分词器的嵌入初始化和适配。具体来说,MATT利用注意力机制捕捉源模型中token之间的依赖关系,并将其作为一种“软约束”来训练目标模型。这种方法不仅考虑了token的语义信息,还考虑了它们在模型中的上下文关系,从而更好地保留了源模型的知识。
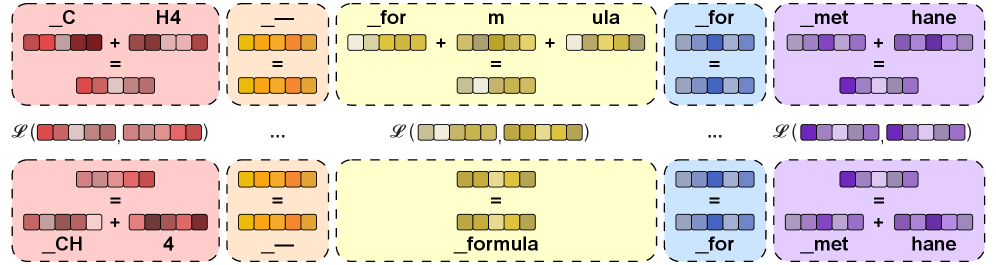
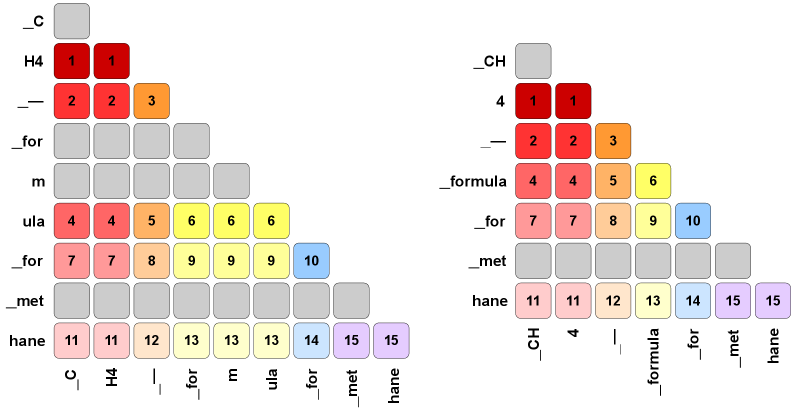
技术框架:MATT主要包含两个阶段:1) 注意力影响建模(AIM):首先,使用源模型对一批文本进行推理,记录每个token之间的注意力权重。然后,使用这些注意力权重作为目标,训练目标模型,使其在相同输入下产生相似的注意力分布。这个阶段的目标是让目标模型学习源模型的token交互模式。2) 语言建模微调:在AIM预训练之后,使用标准的语言建模目标对目标模型进行微调,使其适应新的分词器和目标语言。
关键创新:MATT的关键创新在于引入了注意力影响建模(AIM)目标,将源模型中的token间通信模式提炼到目标模型中。与传统的基于嵌入相似性的方法不同,MATT直接利用注意力行为来指导嵌入初始化和适配,从而更好地保留了源模型的知识。此外,MATT是一种模型感知的迁移方法,它考虑了模型内部的token交互,而不仅仅是token的语义信息。
关键设计:AIM阶段的关键设计在于如何定义注意力影响建模的损失函数。论文中使用KL散度来衡量源模型和目标模型之间的注意力分布差异。具体来说,对于每个token,计算源模型和目标模型之间的注意力权重分布,然后计算这两个分布之间的KL散度,作为该token的损失。整个AIM阶段的损失是所有token损失的平均值。此外,论文还探索了不同的注意力层和注意力头的选择,发现使用中间层的注意力头效果最好。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MATT在多种语言环境下均优于启发式基线方法。例如,在将模型迁移到一种低资源语言时,MATT能够在几个GPU小时内恢复原始模型的大部分性能,显著优于传统的基于嵌入相似性的方法。具体而言,MATT在困惑度(perplexity)指标上取得了显著的降低,表明其能够更好地适应新的分词器和目标语言。
🎯 应用场景
MATT可应用于多语言LLM的快速适配,尤其是在低资源语言或使用不同书写系统的语言上。该方法能有效提升模型在这些语言上的性能,降低训练成本,加速LLM在更广泛语言环境中的部署。此外,MATT的思路也可用于其他模型的知识迁移,例如将一个领域的模型知识迁移到另一个领域。
📄 摘要(原文)
Large Language Models (LLMs) are trained to support an increasing number of languages, yet their predefined tokenizers remain a bottleneck for adapting models to lower-resource or distinct-script languages. Existing tokenizer transfer methods typically rely on semantic heuristics to initialize new embeddings, ignoring higher-layer model dynamics and limiting transfer quality. We propose Model-Aware Tokenizer Transfer (MATT), a method that incorporates model internals into the tokenizer transfer process. MATT introduces an Attention Influence Modeling (AIM) objective that distills inter-token communication patterns from a source model into a target model with a new tokenizer, providing an efficient warm-up before standard language modeling. Unlike approaches that focus solely on embedding similarity, MATT leverages attention behavior to guide embedding initialization and adaptation. Experiments across diverse linguistic settings show that MATT recovers a large fraction of the original model's performance within a few GPU hours, outperforming heuristic baselines. These results demonstrate that incorporating model-level signals offers a practical and effective path toward robust tokenizer transfer in multilingual LLMs.