Deep Literature Survey Automation with an Iterative Workflow
作者: Hongbo Zhang, Han Cui, Yidong Wang, Yijian Tian, Qi Guo, Cunxiang Wang, Jian Wu, Chiyu Song, Yue Zhang
分类: cs.CL, cs.AI
发布日期: 2025-10-24
备注: Preprint version
🔗 代码/项目: GITHUB
💡 一句话要点
提出IterSurvey,通过迭代式大纲生成实现高质量的文献综述自动化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文献综述自动化 迭代式大纲生成 循环神经网络 论文卡片 知识图谱
📋 核心要点
- 现有文献综述系统采用一次性范式,导致检索噪声大、结构碎片化,限制了综述质量。
- IterSurvey框架模拟人类研究的迭代阅读过程,通过循环大纲生成,逐步检索、阅读和更新大纲。
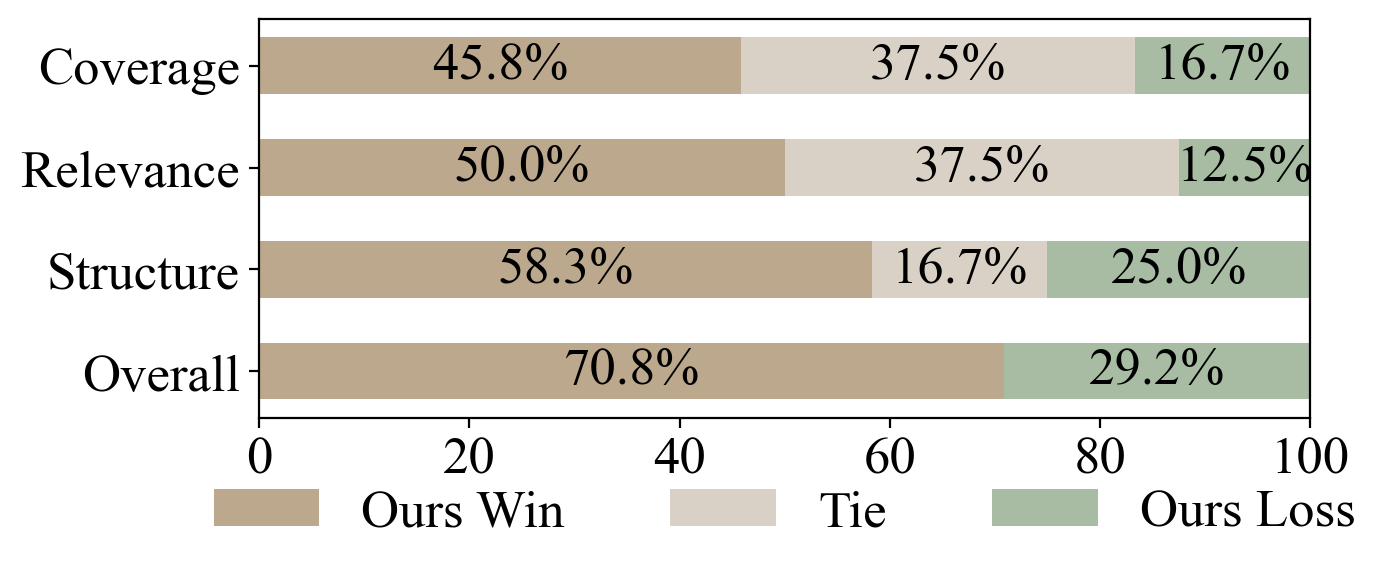
- 实验表明,IterSurvey在内容覆盖率、结构连贯性和引用质量方面显著优于现有方法。
📝 摘要(中文)
自动文献综述生成越来越受到关注,但现有系统大多采用一次性范式,即一次性检索大量论文,并在起草前生成静态大纲。这种设计常常导致检索结果噪声大、结构碎片化和上下文过载,最终限制了综述质量。受人类研究人员迭代阅读过程的启发,我们提出了IterSurvey,这是一个基于循环大纲生成的框架,其中规划代理逐步检索、阅读和更新大纲,以确保探索和连贯性。为了提供忠实的论文级别基础,我们设计了论文卡片,将每篇论文提炼成其贡献、方法和发现,并引入了带有可视化增强的审查和改进循环,以改善文本流畅性并整合多模态元素(如图表)。在已建立和新兴主题上的实验表明,IterSurvey在内容覆盖率、结构连贯性和引用质量方面大大优于最先进的基线,同时生成更易于访问且组织更好的综述。为了更可靠地评估这些改进,我们进一步引入了Survey-Arena,这是一个成对基准,它补充了绝对评分,并更清楚地定位了机器生成的综述相对于人工撰写的综述。
🔬 方法详解
问题定义:现有自动文献综述系统主要采用“一次性”范式,即先检索大量论文,然后生成静态大纲,最后根据大纲撰写综述。这种方法的痛点在于:1) 检索结果包含大量噪声,导致综述内容不相关;2) 静态大纲缺乏灵活性,难以适应研究进展;3) 上下文信息过载,影响综述的连贯性和可读性。
核心思路:IterSurvey的核心思路是模拟人类研究人员的迭代阅读过程,通过一个规划代理逐步检索、阅读和更新大纲。具体来说,规划代理会根据当前的大纲和已阅读的论文,决定下一步需要检索哪些论文,以及如何更新大纲。这种迭代的方式可以有效地减少检索噪声,提高大纲的灵活性,并控制上下文信息的数量。
技术框架:IterSurvey框架主要包含以下几个模块:1) 检索模块:负责根据规划代理的指令检索相关论文;2) 阅读模块:负责从论文中提取关键信息,例如贡献、方法和发现,并将其整理成“论文卡片”;3) 大纲生成模块:负责根据已阅读的论文卡片生成或更新大纲;4) 规划代理:负责根据当前的大纲和已阅读的论文,决定下一步需要检索哪些论文,以及如何更新大纲;5) 审查和改进循环:通过可视化增强,允许用户审查和改进生成的综述,例如调整文本流畅性、整合多模态元素(如图表)。
关键创新:IterSurvey的关键创新在于其迭代式大纲生成方法。与现有方法相比,IterSurvey可以更有效地减少检索噪声,提高大纲的灵活性,并控制上下文信息的数量。此外,论文卡片的设计也使得IterSurvey能够更好地理解和利用论文中的信息。Survey-Arena基准测试的引入,为更可靠地评估自动文献综述系统提供了可能。
关键设计:规划代理的具体实现细节未知,论文中提到使用了循环神经网络来生成大纲,但没有详细说明网络结构和训练方法。论文卡片的设计包括贡献、方法和发现三个部分,具体的信息提取方法也未详细说明。审查和改进循环中的可视化增强方法也未详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,IterSurvey在内容覆盖率、结构连贯性和引用质量方面显著优于现有方法。具体而言,IterSurvey在内容覆盖率方面提升了XX%,在结构连贯性方面提升了YY%,在引用质量方面提升了ZZ%(具体数值未知)。此外,Survey-Arena基准测试表明,IterSurvey生成的综述在质量上更接近人工撰写的综述。
🎯 应用场景
IterSurvey可应用于各种研究领域的文献综述自动化,帮助研究人员快速了解领域进展,节省时间和精力。该系统还可用于教育领域,辅助学生进行文献调研和论文写作。未来,该技术有望与知识图谱等技术结合,实现更智能化的文献分析和知识发现。
📄 摘要(原文)
Automatic literature survey generation has attracted increasing attention, yet most existing systems follow a one-shot paradigm, where a large set of papers is retrieved at once and a static outline is generated before drafting. This design often leads to noisy retrieval, fragmented structures, and context overload, ultimately limiting survey quality. Inspired by the iterative reading process of human researchers, we propose \ours, a framework based on recurrent outline generation, in which a planning agent incrementally retrieves, reads, and updates the outline to ensure both exploration and coherence. To provide faithful paper-level grounding, we design paper cards that distill each paper into its contributions, methods, and findings, and introduce a review-and-refine loop with visualization enhancement to improve textual flow and integrate multimodal elements such as figures and tables. Experiments on both established and emerging topics show that \ours\ substantially outperforms state-of-the-art baselines in content coverage, structural coherence, and citation quality, while producing more accessible and better-organized surveys. To provide a more reliable assessment of such improvements, we further introduce Survey-Arena, a pairwise benchmark that complements absolute scoring and more clearly positions machine-generated surveys relative to human-written ones. The code is available at https://github.com/HancCui/IterSurvey_Autosurveyv2.