Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
作者: Kuicai Dong, Shurui Huang, Fangda Ye, Wei Han, Zhi Zhang, Dexun Li, Wenjun Li, Qu Yang, Gang Wang, Yichao Wang, Chen Zhang, Yong Liu
分类: cs.IR, cs.CL
发布日期: 2025-10-24
备注: preprint
💡 一句话要点
提出Doc-Researcher,用于多模态文档解析和深度研究的统一系统。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态文档解析 深度研究 多智能体系统 信息检索 视觉语义 M4DocBench 跨模态推理
📋 核心要点
- 现有深度研究系统主要处理文本网络数据,忽略了多模态文档中的知识,缺乏对视觉语义的解析和跨模态检索能力。
- Doc-Researcher通过深度多模态解析、系统检索架构和迭代多智能体工作流,实现了对多模态文档的深度研究。
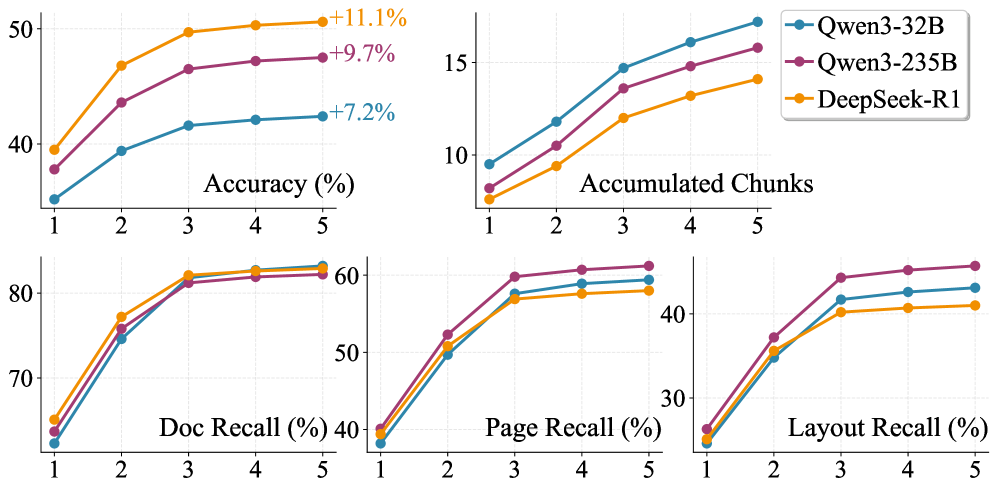
- 在M4DocBench基准测试中,Doc-Researcher的准确率达到50.6%,比现有方法提升3.4倍,验证了其有效性。
📝 摘要(中文)
深度研究系统通过迭代推理和证据收集,彻底改变了大语言模型解决复杂问题的方式。然而,现有系统主要局限于文本网络数据,忽略了多模态文档中蕴含的丰富知识。处理这些文档需要复杂的解析来保留视觉语义(如图表、表格、图和公式),智能分块以保持结构连贯性,以及跨模态的自适应检索,而这些能力是现有系统所缺乏的。为此,我们提出了Doc-Researcher,一个统一的系统,通过三个集成组件弥合了这一差距:(i)深度多模态解析,保留布局结构和视觉语义,同时创建从块到文档级别的多粒度表示;(ii)系统检索架构,支持纯文本、纯视觉和混合范式,并具有动态粒度选择;(iii)迭代多智能体工作流,分解复杂查询,逐步积累证据,并综合跨文档和模态的全面答案。为了进行严格的评估,我们推出了M4DocBench,这是第一个用于多模态、多跳、多文档和多轮深度研究的基准。M4DocBench包含158个专家注释的问题,以及跨304个文档的完整证据链,测试了现有基准无法评估的能力。实验表明,Doc-Researcher实现了50.6%的准确率,比最先进的基线提高了3.4倍,验证了有效的文档研究不仅需要更好的检索,还需要从根本上进行深度解析,以保持多模态完整性并支持迭代研究。我们的工作为在多模态文档集合上进行深度研究建立了一个新的范例。
🔬 方法详解
问题定义:现有深度研究系统主要依赖于文本数据,无法有效处理包含图表、公式等视觉信息的复杂多模态文档。这些系统缺乏对文档结构和视觉语义的理解,导致无法准确检索和推理相关信息,限制了其在科学研究、金融分析等领域的应用。现有方法的痛点在于无法有效整合文本和视觉信息,进行跨模态的推理和知识发现。
核心思路:Doc-Researcher的核心思路是构建一个统一的多模态文档解析和深度研究系统,通过深度解析保留文档的视觉语义和结构信息,并利用多智能体工作流进行迭代推理和证据收集。该系统旨在弥合文本和视觉信息之间的鸿沟,实现对多模态文档的全面理解和利用。这样设计的目的是为了充分利用文档中蕴含的各种信息,提高深度研究的准确性和效率。
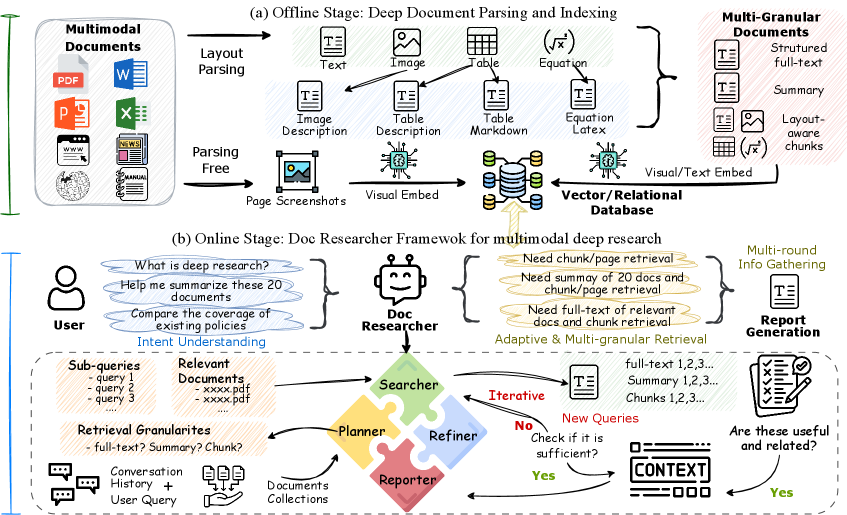
技术框架:Doc-Researcher包含三个主要组件:(1) 深度多模态解析模块,负责解析文档的布局结构和视觉语义,生成多粒度的文档表示;(2) 系统检索架构,支持文本、视觉和混合检索范式,并能动态选择合适的粒度;(3) 迭代多智能体工作流,将复杂查询分解为子任务,逐步积累证据,并综合生成答案。整个流程从多模态文档的解析开始,然后通过检索模块找到相关信息,最后利用多智能体工作流进行推理和答案生成。
关键创新:Doc-Researcher的关键创新在于其统一的多模态文档处理框架,能够同时处理文本和视觉信息,并保留文档的结构和语义信息。与现有方法相比,Doc-Researcher不仅关注文本内容,还充分利用了文档中的图表、公式等视觉信息,从而提高了检索和推理的准确性。此外,该系统还引入了迭代多智能体工作流,能够将复杂查询分解为多个子任务,并逐步积累证据,从而提高了处理复杂问题的能力。
关键设计:在深度多模态解析模块中,采用了基于Transformer的模型来学习文档的布局结构和视觉语义表示。在系统检索架构中,使用了对比学习的方法来训练文本和视觉信息的嵌入表示,并设计了动态粒度选择机制,以适应不同的查询需求。在迭代多智能体工作流中,采用了强化学习的方法来优化智能体的策略,使其能够更有效地分解查询和积累证据。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
Doc-Researcher在M4DocBench基准测试中取得了显著成果,准确率达到50.6%,比最先进的基线提高了3.4倍。这一结果表明,Doc-Researcher在多模态文档解析和深度研究方面具有显著优势,能够有效处理复杂的多模态查询,并提供准确的答案。
🎯 应用场景
Doc-Researcher可应用于科学研究、金融分析、法律咨询等领域,帮助研究人员和专业人士快速准确地从大量多模态文档中提取关键信息,解决复杂问题。该系统能够提高信息检索和知识发现的效率,促进跨学科研究和创新,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Deep Research systems have revolutionized how LLMs solve complex questions through iterative reasoning and evidence gathering. However, current systems remain fundamentally constrained to textual web data, overlooking the vast knowledge embedded in multimodal documents Processing such documents demands sophisticated parsing to preserve visual semantics (figures, tables, charts, and equations), intelligent chunking to maintain structural coherence, and adaptive retrieval across modalities, which are capabilities absent in existing systems. In response, we present Doc-Researcher, a unified system that bridges this gap through three integrated components: (i) deep multimodal parsing that preserves layout structure and visual semantics while creating multi-granular representations from chunk to document level, (ii) systematic retrieval architecture supporting text-only, vision-only, and hybrid paradigms with dynamic granularity selection, and (iii) iterative multi-agent workflows that decompose complex queries, progressively accumulate evidence, and synthesize comprehensive answers across documents and modalities. To enable rigorous evaluation, we introduce M4DocBench, the first benchmark for Multi-modal, Multi-hop, Multi-document, and Multi-turn deep research. Featuring 158 expert-annotated questions with complete evidence chains across 304 documents, M4DocBench tests capabilities that existing benchmarks cannot assess. Experiments demonstrate that Doc-Researcher achieves 50.6% accuracy, 3.4xbetter than state-of-the-art baselines, validating that effective document research requires not just better retrieval, but fundamentally deep parsing that preserve multimodal integrity and support iterative research. Our work establishes a new paradigm for conducting deep research on multimodal document collections.