Are the LLMs Capable of Maintaining at Least the Language Genus?
作者: Sandra Mitrović, David Kletz, Ljiljana Dolamic, Fabio Rinaldi
分类: cs.CL
发布日期: 2025-10-24
💡 一句话要点
研究LLM是否能维持语言谱系关系,揭示训练数据对多语言能力的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多语言处理 语言谱系 知识一致性 训练数据 语系关系 MultiQ数据集
📋 核心要点
- 现有研究对LLM多语言能力差异的谱系语言结构影响探索不足。
- 通过分析LLM在语言切换和知识保持方面的表现,评估其对语系关系的敏感性。
- 实验表明LLM具备语系层面的感知能力,但训练数据分布不均是主要影响因素。
📝 摘要(中文)
大型语言模型(LLM)在多语言行为方面表现出显著差异,但谱系语言结构在塑造这种差异中的作用仍未得到充分探索。本文通过扩展对MultiQ数据集的先前分析,研究LLM是否对语言谱系具有敏感性。我们首先检查当提示语言的保真度未被维持时,模型是否倾向于切换到谱系相关的语言。接下来,我们研究知识一致性在语系内部是否比跨语系更好地保持。我们表明,语系层面的影响是存在的,但受到训练资源可用性的强烈制约。我们进一步观察到不同LLM系列之间存在不同的多语言策略。我们的研究结果表明,LLM编码了语系层面结构的某些方面,但训练数据的不平衡仍然是塑造其多语言性能的主要因素。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在处理多语言任务时,是否能够维持语言的谱系关系。现有方法未能充分探索语言谱系结构对LLM多语言行为的影响,并且缺乏对LLM在语系层面知识保持能力的深入分析。
核心思路:论文的核心思路是通过分析LLM在语言切换和知识保持方面的表现,来评估其对语言谱系关系的敏感性。具体来说,研究模型在未能维持提示语言的保真度时,是否倾向于切换到谱系相关的语言;以及知识一致性在语系内部是否比跨语系更好地保持。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择MultiQ数据集作为评估基准;2) 分析LLM在语言切换时的行为,即当模型未能维持提示语言的保真度时,是否倾向于切换到谱系相关的语言;3) 评估LLM在语系内部和跨语系之间的知识保持能力;4) 对比不同LLM系列的多语言策略,分析训练资源可用性对模型性能的影响。
关键创新:论文的关键创新在于首次系统性地研究了LLM对语言谱系关系的感知能力,并揭示了训练数据不平衡对LLM多语言性能的影响。此外,论文还对比了不同LLM系列的多语言策略,为理解LLM的多语言行为提供了新的视角。与现有方法相比,本研究更加关注语言的谱系结构,并从语系层面对LLM的多语言能力进行了深入分析。
关键设计:论文的关键设计包括:1) 使用MultiQ数据集进行评估,该数据集包含多种语言和知识领域,可以有效评估LLM的多语言能力;2) 设计了语言切换实验,通过分析模型在未能维持提示语言的保真度时的行为,来评估其对语言谱系关系的敏感性;3) 评估了LLM在语系内部和跨语系之间的知识保持能力,通过比较模型在不同语系之间的知识一致性,来评估其对语言谱系关系的理解。
🖼️ 关键图片


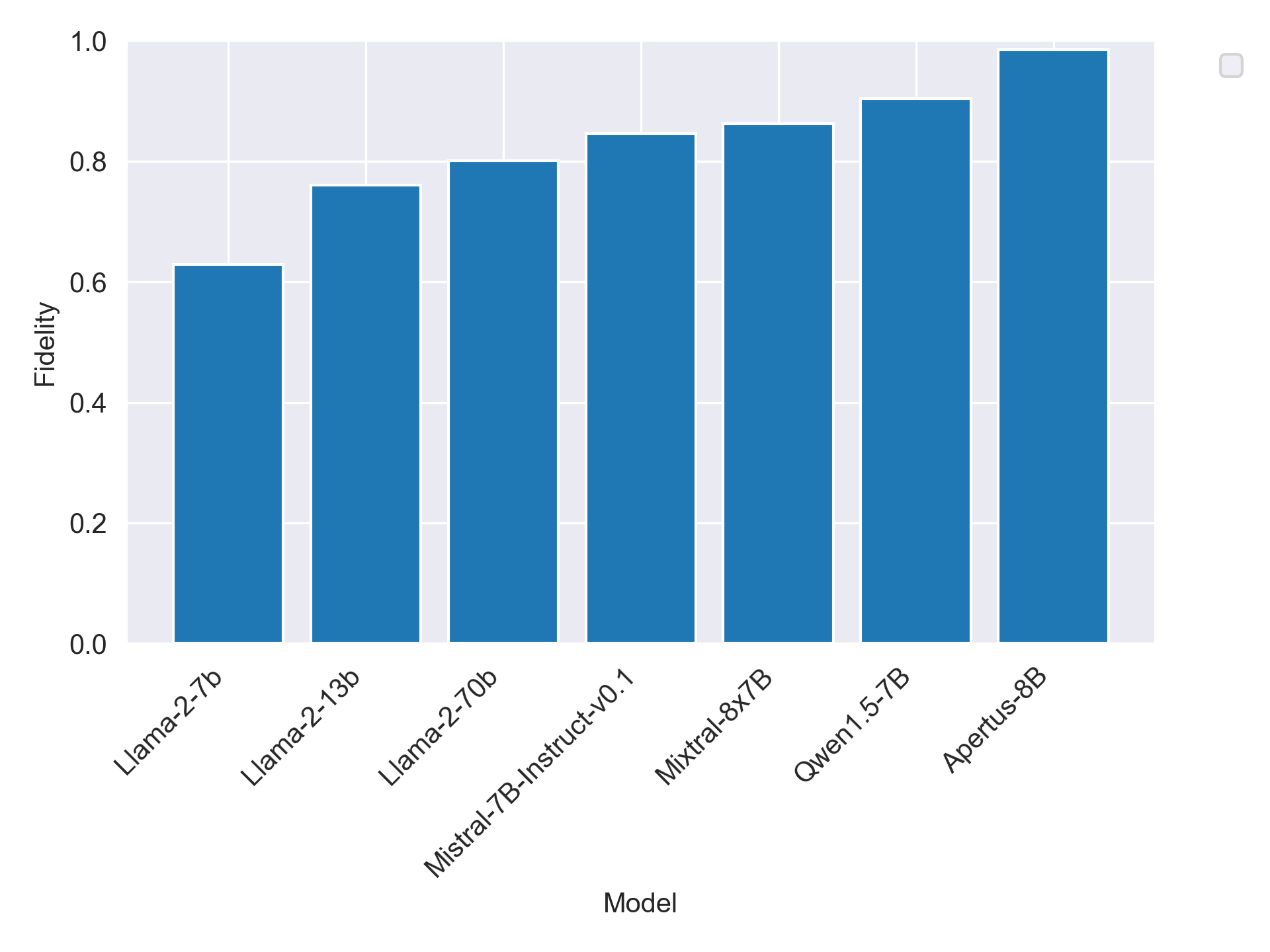
📊 实验亮点
实验结果表明,LLM在一定程度上编码了语系层面的结构信息,但训练数据的不平衡是影响其多语言性能的主要因素。研究发现,当提示语言的保真度未被维持时,模型倾向于切换到谱系相关的语言。此外,知识一致性在语系内部比跨语系更好,但这种效应受到训练资源可用性的强烈制约。
🎯 应用场景
该研究成果可应用于提升多语言LLM的性能,尤其是在低资源语言的处理上。通过更好地理解LLM对语言谱系关系的感知能力,可以指导模型训练,使其更好地泛化到不同语言。此外,该研究还有助于开发更可靠的多语言知识库和跨语言信息检索系统。
📄 摘要(原文)
Large Language Models (LLMs) display notable variation in multilingual behavior, yet the role of genealogical language structure in shaping this variation remains underexplored. In this paper, we investigate whether LLMs exhibit sensitivity to linguistic genera by extending prior analyses on the MultiQ dataset. We first check if models prefer to switch to genealogically related languages when prompt language fidelity is not maintained. Next, we investigate whether knowledge consistency is better preserved within than across genera. We show that genus-level effects are present but strongly conditioned by training resource availability. We further observe distinct multilingual strategies across LLMs families. Our findings suggest that LLMs encode aspects of genus-level structure, but training data imbalances remain the primary factor shaping their multilingual performance.