Wisdom and Delusion of LLM Ensembles for Code Generation and Repair
作者: Fernando Vallecillos-Ruiz, Max Hort, Leon Moonen
分类: cs.SE, cs.CL, cs.LG
发布日期: 2025-10-24 (更新: 2025-10-30)
备注: Added Acknowledgments section and hyphenated last names
💡 一句话要点
提出基于多样性的LLM集成方法,显著提升代码生成与修复性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 程序修复 大型语言模型 模型集成 多样性 软件工程 代码质量
📋 核心要点
- 现有方法依赖单一LLM进行代码任务,忽略了不同模型间的互补优势,导致资源浪费和性能瓶颈。
- 提出基于多样性的LLM集成方法,通过选择不同模型生成的互补代码,提升整体性能。
- 实验表明,该方法理论上可将性能提升83%,实际应用中基于多样性的策略可实现95%的潜力。
📝 摘要(中文)
当前软件工程领域过度依赖单一大型语言模型(LLM)进行代码生成和修复,忽略了不同模型之间互补优势的潜力。本文旨在探究代码LLM之间的互补性,并寻找最大化集成模型潜力的策略,为从业者提供超越单模型系统的清晰路径。研究对比了来自五个系列的十个独立LLM以及它们的三个集成模型在代码生成和程序修复三个基准测试上的表现。评估了模型之间的互补性以及最佳单模型与集成模型之间的性能差距。进一步评估了各种选择启发式方法,以从集成模型的候选池中识别正确的解决方案。结果表明,集成模型的理论上限比最佳单模型高83%。基于共识的解决方案选择策略会陷入“流行陷阱”,放大常见但错误的输出。相比之下,基于多样性的策略实现了高达95%的理论潜力,即使在小型双模型集成中也有效,从而以经济高效的方式通过利用多个LLM来提高性能。
🔬 方法详解
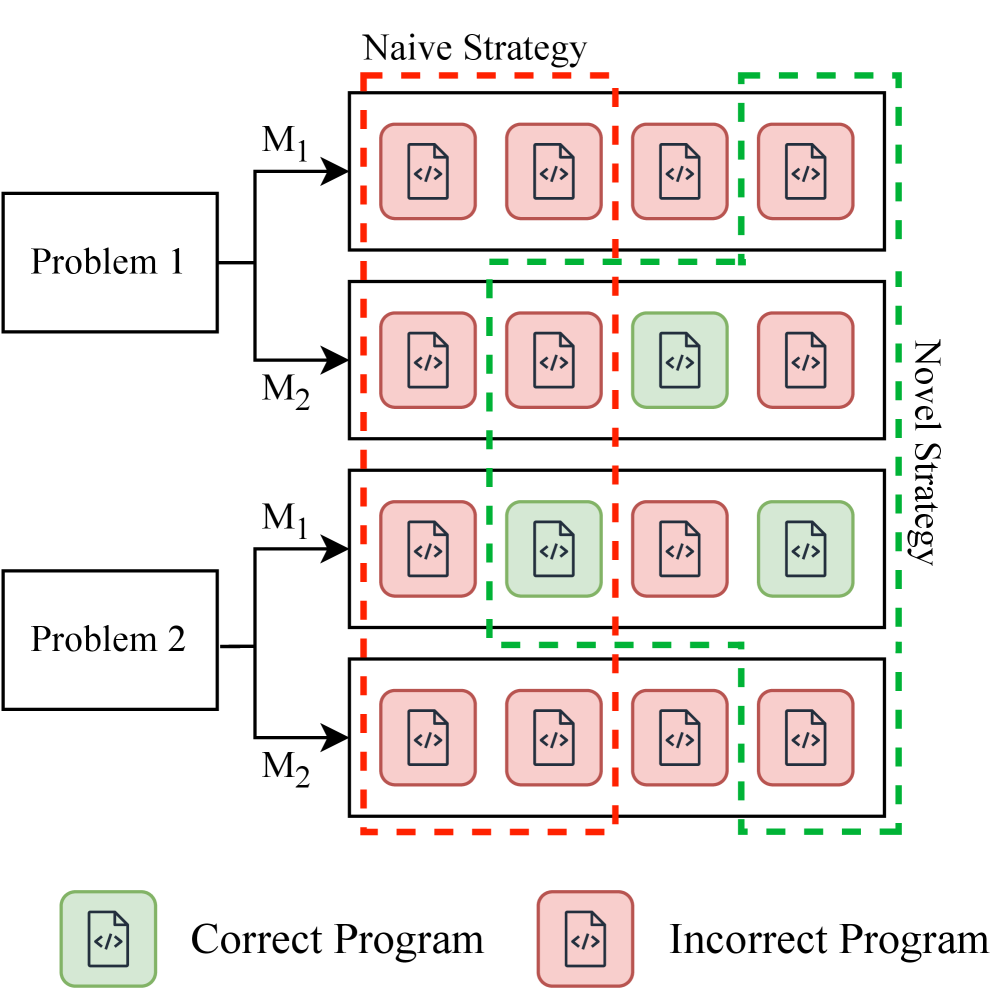
问题定义:现有代码生成和修复任务主要依赖于单一大型语言模型,这种方法忽略了不同LLM在特定代码任务上的优势互补。现有方法容易陷入“流行陷阱”,即选择多个模型都生成的常见答案,但这些答案可能并非正确答案。因此,如何有效利用多个LLM的优势,避免“流行陷阱”,提升代码生成和修复的准确率是一个关键问题。
核心思路:本文的核心思路是利用LLM生成结果的多样性。不同的LLM在训练数据、模型结构等方面存在差异,因此它们生成的代码也具有不同的特点。通过选择那些彼此之间差异较大,但又具有潜在正确性的代码,可以有效地避免“流行陷阱”,并提高整体性能。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个不同的LLM;2) 使用这些LLM生成代码或修复代码;3) 使用不同的选择策略从生成的代码中选择最终的输出。其中,选择策略是关键,包括基于共识的策略(选择多个模型都生成的代码)和基于多样性的策略(选择彼此之间差异较大的代码)。
关键创新:该研究的关键创新在于提出了基于多样性的LLM集成方法。与传统的基于共识的方法不同,该方法更加注重利用不同LLM之间的差异性,从而避免了“流行陷阱”。这种方法能够更有效地利用多个LLM的优势,提高代码生成和修复的准确率。
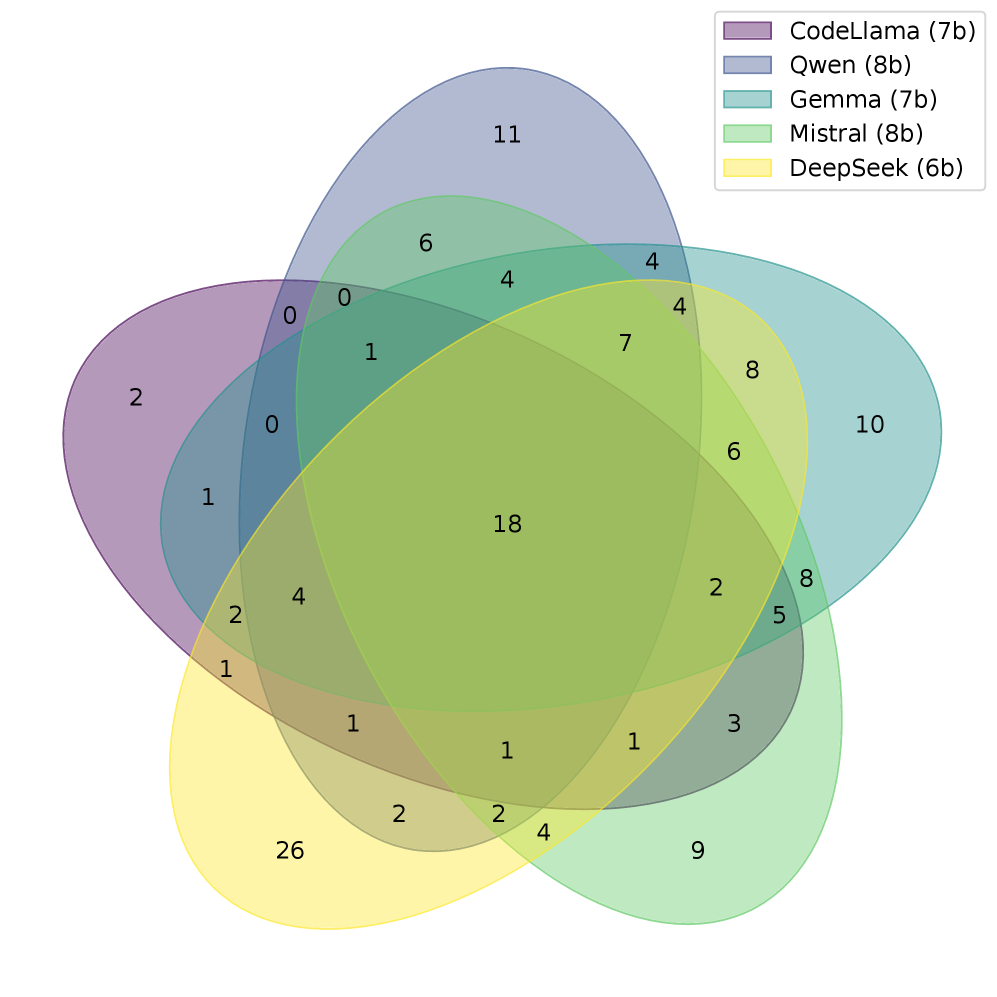
关键设计:在实验中,研究人员使用了来自五个系列的十个独立LLM,并在三个软件工程基准测试上进行了评估。他们比较了不同的选择策略,包括基于共识的策略和基于多样性的策略。为了衡量多样性,可以使用例如编辑距离等指标来衡量不同代码之间的差异。此外,还可以使用一些启发式方法来评估代码的潜在正确性,例如代码的语法正确性、是否通过了单元测试等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,集成模型的理论性能上限比最佳单模型高83%。基于共识的策略容易陷入“流行陷阱”,而基于多样性的策略能够实现高达95%的理论潜力。即使在小型双模型集成中,基于多样性的策略也能有效提升性能,提供了一种经济高效的性能提升方案。
🎯 应用场景
该研究成果可应用于自动化代码生成、程序修复、代码补全等软件工程领域。通过集成多个LLM,可以显著提高代码质量和开发效率,降低软件开发成本。未来,该方法有望应用于更复杂的软件工程任务,例如软件测试、代码审查等。
📄 摘要(原文)
Today's pursuit of a single Large Language Model (LMM) for all software engineering tasks is resource-intensive and overlooks the potential benefits of complementarity, where different models contribute unique strengths. However, the degree to which coding LLMs complement each other and the best strategy for maximizing an ensemble's potential are unclear, leaving practitioners without a clear path to move beyond single-model systems. To address this gap, we empirically compare ten individual LLMs from five families, and three ensembles of these LLMs across three software engineering benchmarks covering code generation and program repair. We assess the complementarity between models and the performance gap between the best individual model and the ensembles. Next, we evaluate various selection heuristics to identify correct solutions from an ensemble's candidate pool. We find that the theoretical upperbound for an ensemble's performance can be 83% above the best single model. Our results show that consensus-based strategies for selecting solutions fall into a "popularity trap," amplifying common but incorrect outputs. In contrast, a diversity-based strategy realizes up to 95% of this theoretical potential, and proves effective even in small two-model ensembles, enabling a cost-efficient way to enhance performance by leveraging multiple LLMs.