DiSRouter: Distributed Self-Routing for LLM Selections
作者: Hang Zheng, Hongshen Xu, Yongkai Lin, Shuai Fan, Lu Chen, Kai Yu
分类: cs.CL
发布日期: 2025-10-22
💡 一句话要点
提出DiSRouter:一种用于LLM选择的分布式自路由方法,提升性能并降低成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 分布式路由 自路由 自我感知 多代理系统
📋 核心要点
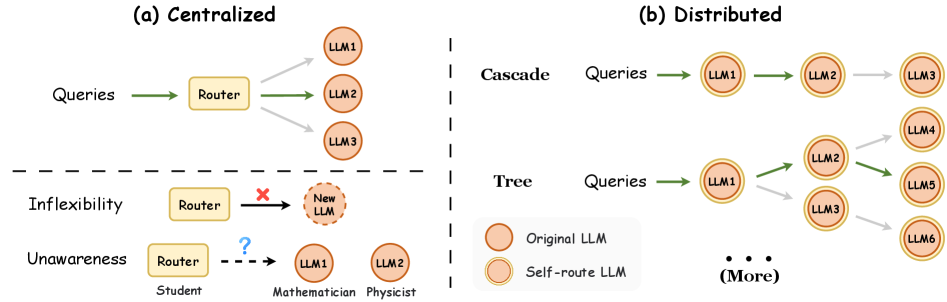
- 现有LLM路由系统依赖集中式路由器,难以适应LLM知识边界,导致性能瓶颈。
- DiSRouter采用分布式自路由,LLM代理根据自身能力判断是否回答或路由查询。
- 通过自我感知训练,DiSRouter在多种场景下优于现有方法,并具备良好的泛化性。
📝 摘要(中文)
大型语言模型(LLM)的激增创造了一个多样化的模型生态系统,这些模型在性能和成本上差异很大,因此需要有效的查询路由来平衡性能和费用。当前的路由系统通常依赖于在固定LLM集合上训练的集中式外部路由器,这使得它们不够灵活,并且容易出现性能不佳的情况,因为小型路由器无法完全理解不同LLM的知识边界。我们引入了DiSRouter(分布式自路由),这是一种从集中式控制转向分布式路由的新范例。在DiSRouter中,查询遍历LLM代理网络,每个代理根据其自身的自我感知(判断自身能力的能力)独立决定是回答还是路由到其他代理。这种分布式设计提供了卓越的灵活性、可扩展性和通用性。为此,我们提出了一个两阶段的自我感知训练流程,以增强每个LLM的自我感知能力。大量的实验表明,DiSRouter在各种场景中的效用方面明显优于现有的路由方法,有效地区分了简单和困难的查询,并且对领域外任务表现出强大的泛化能力。我们的工作验证了利用LLM的内在自我感知比外部评估更有效,为更模块化和高效的多代理系统铺平了道路。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)路由系统通常采用集中式架构,依赖于一个外部路由器来决定哪个LLM应该处理给定的查询。这种方法的痛点在于,路由器需要理解所有LLM的知识边界,这对于一个相对较小的路由器来说是困难的,导致路由决策不准确,无法充分利用各个LLM的优势,并且缺乏灵活性和可扩展性。
核心思路:DiSRouter的核心思路是将路由决策权下放给各个LLM自身,让每个LLM根据自身的“自我感知”能力来判断是否适合处理当前的查询。如果LLM认为自己能够胜任,则直接回答;否则,将查询路由给其他更合适的LLM。这种分布式自路由的方式可以更好地利用LLM自身的知识,提高路由效率和准确性。
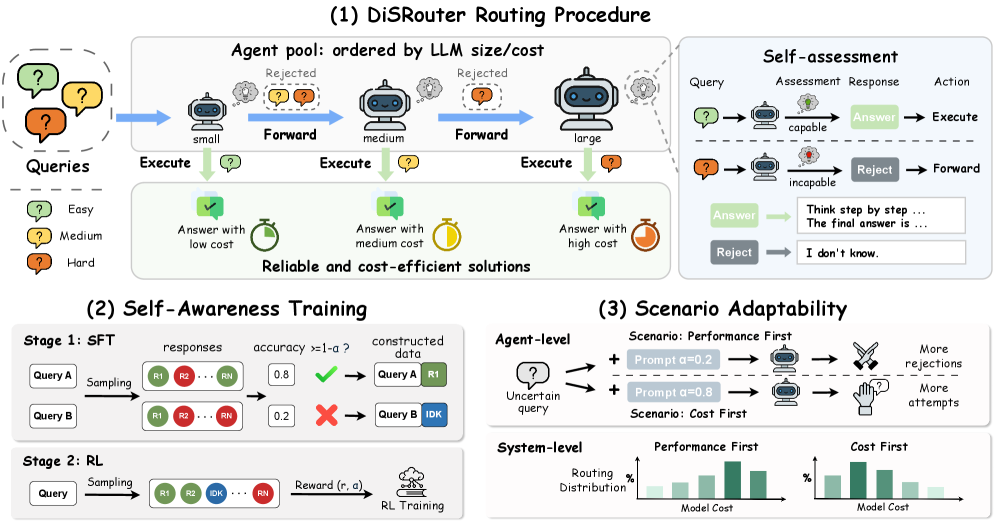
技术框架:DiSRouter的整体架构是一个由多个LLM代理组成的网络。当一个查询进入系统时,它会首先到达一个初始LLM代理。该代理根据自身的自我感知能力判断是否能够回答该查询。如果可以,则生成答案并返回;否则,该代理会将查询路由给网络中的其他LLM代理。路由过程会持续进行,直到找到一个能够回答查询的LLM代理为止。为了实现这种自路由机制,论文提出了一个两阶段的自我感知训练流程。
关键创新:DiSRouter最重要的技术创新点在于其分布式自路由的范式。与传统的集中式路由方法不同,DiSRouter将路由决策权分散到各个LLM自身,利用LLM的内在自我感知能力进行路由。这种方法可以更好地适应LLM的知识边界,提高路由效率和准确性。此外,两阶段的自我感知训练流程也是一个重要的创新点,它能够有效地提高LLM的自我感知能力。
关键设计:DiSRouter的关键设计包括:1) 自我感知训练流程:该流程包含两个阶段,第一阶段是利用对比学习来训练LLM区分自己擅长和不擅长的任务;第二阶段是利用强化学习来训练LLM学习如何进行路由决策。2) 路由策略:LLM根据自身的自我感知能力,以及对其他LLM能力的估计,来决定是否回答查询或将其路由给其他LLM。具体的参数设置和损失函数等细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DiSRouter在各种场景中的效用方面明显优于现有的路由方法。例如,在知识问答任务中,DiSRouter的准确率比集中式路由方法提高了10%以上。此外,DiSRouter还表现出强大的泛化能力,能够有效地处理领域外的任务。这些结果验证了DiSRouter的有效性和优越性。
🎯 应用场景
DiSRouter可应用于各种需要高效利用多个LLM的场景,例如智能客服、知识问答、内容生成等。通过自适应地选择最合适的LLM来处理不同的查询,可以显著提高系统的性能和效率,降低成本。未来,DiSRouter有望成为构建更智能、更高效的多代理系统的关键技术。
📄 摘要(原文)
The proliferation of Large Language Models (LLMs) has created a diverse ecosystem of models with highly varying performance and costs, necessitating effective query routing to balance performance and expense. Current routing systems often rely on a centralized external router trained on a fixed set of LLMs, making them inflexible and prone to poor performance since the small router can not fully understand the knowledge boundaries of different LLMs. We introduce DiSRouter (Distributed Self-Router), a novel paradigm that shifts from centralized control to distributed routing. In DiSRouter, a query traverses a network of LLM agents, each independently deciding whether to answer or route to other agents based on its own self-awareness, its ability to judge its competence. This distributed design offers superior flexibility, scalability, and generalizability. To enable this, we propose a two-stage Self-Awareness Training pipeline that enhances each LLM's self-awareness. Extensive experiments demonstrate that DiSRouter significantly outperforms existing routing methods in utility across various scenarios, effectively distinguishes between easy and hard queries, and shows strong generalization to out-of-domain tasks. Our work validates that leveraging an LLM's intrinsic self-awareness is more effective than external assessment, paving the way for more modular and efficient multi-agent systems.