OpenGuardrails: A Configurable, Unified, and Scalable Guardrails Platform for Large Language Models
作者: Thomas Wang, Haowen Li
分类: cs.CR, cs.CL
发布日期: 2025-10-22 (更新: 2025-10-29)
💡 一句话要点
OpenGuardrails:一个可配置、统一且可扩展的大语言模型安全平台
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 内容安全 模型操纵防御 提示注入 可配置策略 模型量化 多语言支持
📋 核心要点
- 现有大语言模型安全方案缺乏灵活性,难以针对不同应用场景定制安全策略和阈值。
- OpenGuardrails提出了一种可配置的策略适应机制,允许根据每个请求定制不安全类别和敏感度阈值。
- OpenGuardrails在多语言安全基准测试中实现了最先进的性能,并提供了可部署的API服务。
📝 摘要(中文)
随着大型语言模型(LLMs)日益融入实际应用,确保其安全性、鲁棒性和隐私合规性变得至关重要。我们提出了OpenGuardrails,这是首个完全开源的平台,它统一了基于大型模型的安全检测、操纵防御和可部署的防护基础设施。OpenGuardrails可防御三大类风险:(1)内容安全违规,如生成有害或露骨的文本;(2)模型操纵攻击,包括提示注入、越狱和代码解释器滥用;(3)涉及敏感或私人信息的数据泄露。与之前的模块化或基于规则的框架不同,OpenGuardrails引入了三个核心创新:(1)可配置的策略适应机制,允许对每个请求自定义不安全类别和敏感度阈值;(2)统一的基于LLM的防护架构,在单个模型中执行内容安全和操纵检测;(3)量化、可扩展的模型设计,通过GPTQ将14B稠密基础模型压缩到3.3B,同时保持超过98%的基准精度。该系统支持119种语言,在多语言安全基准测试中实现了最先进的性能,并且可以部署为企业使用的安全网关或基于API的服务。所有模型、数据集和部署脚本均以Apache 2.0许可证发布。
🔬 方法详解
问题定义:现有的大语言模型安全方案通常是模块化的或基于规则的,缺乏灵活性,难以适应不同的应用场景和安全需求。此外,现有的方案往往需要多个模型或模块来处理不同的安全风险,例如内容安全和模型操纵,导致效率低下和部署复杂。
核心思路:OpenGuardrails的核心思路是构建一个统一的、可配置的、可扩展的平台,能够在一个模型中同时处理内容安全和模型操纵等多种安全风险。通过可配置的策略适应机制,可以根据每个请求定制不安全类别和敏感度阈值,从而实现更灵活的安全控制。
技术框架:OpenGuardrails的整体架构包括三个主要部分:(1) 可配置的策略适应模块,用于定义和定制安全策略;(2) 统一的LLM-based防护架构,使用单个模型执行内容安全和操纵检测;(3) 量化、可扩展的模型设计,通过模型压缩技术提高模型的效率和可部署性。该系统可以部署为安全网关或基于API的服务。
关键创新:OpenGuardrails的关键创新在于其统一的LLM-based防护架构和可配置的策略适应机制。传统的安全方案通常需要多个模型或模块来处理不同的安全风险,而OpenGuardrails通过单个模型实现了多种安全风险的检测和防御。可配置的策略适应机制允许根据每个请求定制安全策略,从而实现更灵活的安全控制。
关键设计:OpenGuardrails使用一个14B的稠密基础模型,并通过GPTQ量化技术将其压缩到3.3B,从而在保持精度的同时提高了模型的效率和可部署性。该系统支持119种语言,并提供了丰富的API接口,方便用户进行集成和定制。
🖼️ 关键图片

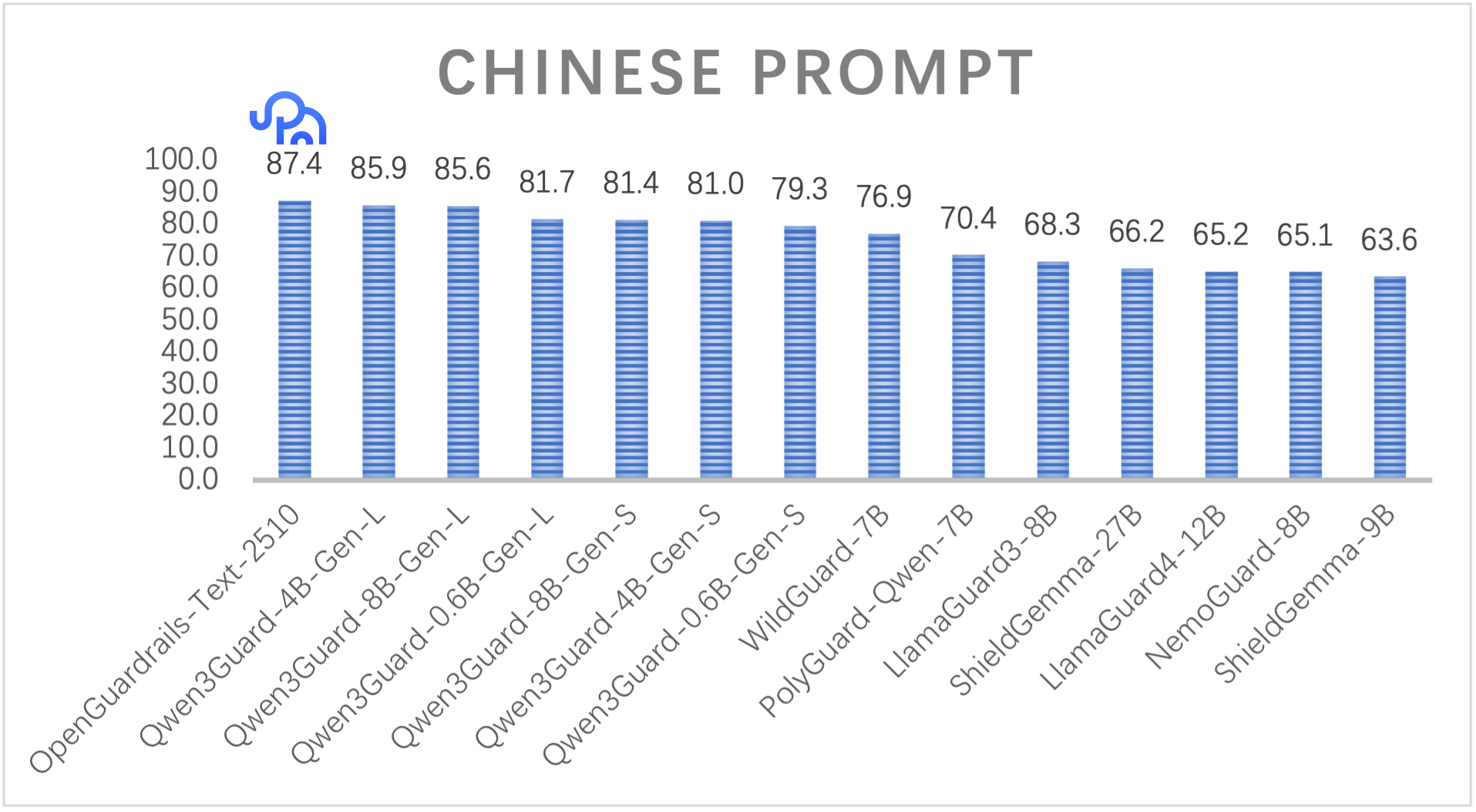

📊 实验亮点
OpenGuardrails在多语言安全基准测试中实现了最先进的性能,证明了其在处理不同语言的安全风险方面的有效性。通过GPTQ量化技术,OpenGuardrails将14B稠密基础模型压缩到3.3B,同时保持超过98%的基准精度,显著提高了模型的效率和可部署性。该系统支持119种语言,并提供了可部署的API服务,方便用户进行集成和定制。
🎯 应用场景
OpenGuardrails可广泛应用于各种需要确保大语言模型安全性的场景,例如聊天机器人、内容生成平台、代码生成工具等。它可以帮助企业防止有害内容的生成、模型操纵攻击和数据泄露,从而提高用户体验和保护用户隐私。未来,OpenGuardrails可以进一步扩展到支持更多的安全风险和应用场景,例如对抗性攻击防御和隐私保护。
📄 摘要(原文)
As large language models (LLMs) are increasingly integrated into real-world applications, ensuring their safety, robustness, and privacy compliance has become critical. We present OpenGuardrails, the first fully open-source platform that unifies large-model-based safety detection, manipulation defense, and deployable guardrail infrastructure. OpenGuardrails protects against three major classes of risks: (1) content-safety violations such as harmful or explicit text generation, (2) model-manipulation attacks including prompt injection, jailbreaks, and code-interpreter abuse, and (3) data leakage involving sensitive or private information. Unlike prior modular or rule-based frameworks, OpenGuardrails introduces three core innovations: (1) a Configurable Policy Adaptation mechanism that allows per-request customization of unsafe categories and sensitivity thresholds; (2) a Unified LLM-based Guard Architecture that performs both content-safety and manipulation detection within a single model; and (3) a Quantized, Scalable Model Design that compresses a 14B dense base model to 3.3B via GPTQ while preserving over 98 of benchmark accuracy. The system supports 119 languages, achieves state-of-the-art performance across multilingual safety benchmarks, and can be deployed as a secure gateway or API-based service for enterprise use. All models, datasets, and deployment scripts are released under the Apache 2.0 license.