"You Are Rejected!": An Empirical Study of Large Language Models Taking Hiring Evaluations
作者: Dingjie Fu, Dianxing Shi
分类: cs.CL
发布日期: 2025-10-22 (更新: 2025-10-23)
备注: Technical Report, 14 pages, 8 figures
💡 一句话要点
研究表明:大型语言模型在标准招聘评估中表现不佳
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 招聘评估 软件工程师 能力评估 自然语言处理
📋 核心要点
- 科技公司需要高效筛选工程师,现有招聘流程依赖标准化评估,但效率仍有提升空间。
- 本研究探索大型语言模型(LLM)在模拟招聘评估中的表现,旨在评估其是否能胜任工程师角色。
- 实验结果表明,当前LLM在标准招聘评估中表现不佳,与公司参考答案存在显著差异,未能通过评估。
📝 摘要(中文)
随着互联网的普及和人工智能的快速发展,领先的科技公司每年都面临着对大量软件和算法工程师的迫切需求。为了高效地从数千名申请者中识别出具有高潜力的候选人,这些公司建立了一个多阶段的选拔流程,其中至关重要的是一个标准化的招聘评估,旨在评估特定于工作的能力。受到大型语言模型(LLM)在编码和推理任务中表现出的强大能力的推动,本文研究了一个关键问题:LLM能否成功通过这些招聘评估?为此,我们对一种广泛使用的专业评估问卷进行了全面检查。我们使用最先进的LLM生成答案,并评估它们的性能。与之前对LLM作为理想工程师的任何期望相反,我们的分析揭示了模型生成的答案与公司参考解决方案之间存在显着不一致。我们的经验结果得出了一个惊人的结论:所有评估的LLM都未能通过招聘评估。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在模拟真实招聘场景下的表现。现有招聘流程中,标准化评估是重要环节,但LLM能否胜任工程师角色仍是未知数。现有方法缺乏对LLM在实际招聘评估中能力的系统性评估。
核心思路:论文的核心思路是利用现有的、广泛使用的专业评估问卷,让LLM生成答案,然后将LLM的答案与公司提供的标准答案进行对比分析,以此来评估LLM是否能够通过招聘评估。这种方法模拟了真实的招聘流程,能够更准确地反映LLM的实际能力。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择合适的专业评估问卷;2) 使用多个最先进的LLM生成答案;3) 建立评估标准,将LLM生成的答案与公司提供的标准答案进行对比;4) 分析对比结果,得出LLM是否能够通过招聘评估的结论。
关键创新:该研究的关键创新在于首次系统性地评估了LLM在模拟真实招聘场景下的表现。以往的研究主要集中在LLM在编码和推理任务中的能力,而忽略了其在实际应用中的表现。该研究填补了这一空白,为评估LLM的实际应用能力提供了一种新的方法。
关键设计:研究的关键设计包括:选择具有代表性的专业评估问卷,确保评估的有效性;使用多个最先进的LLM,以避免单一模型的偏差;建立客观的评估标准,确保评估的公正性;对对比结果进行深入分析,以揭示LLM的优势和不足。
🖼️ 关键图片

📊 实验亮点
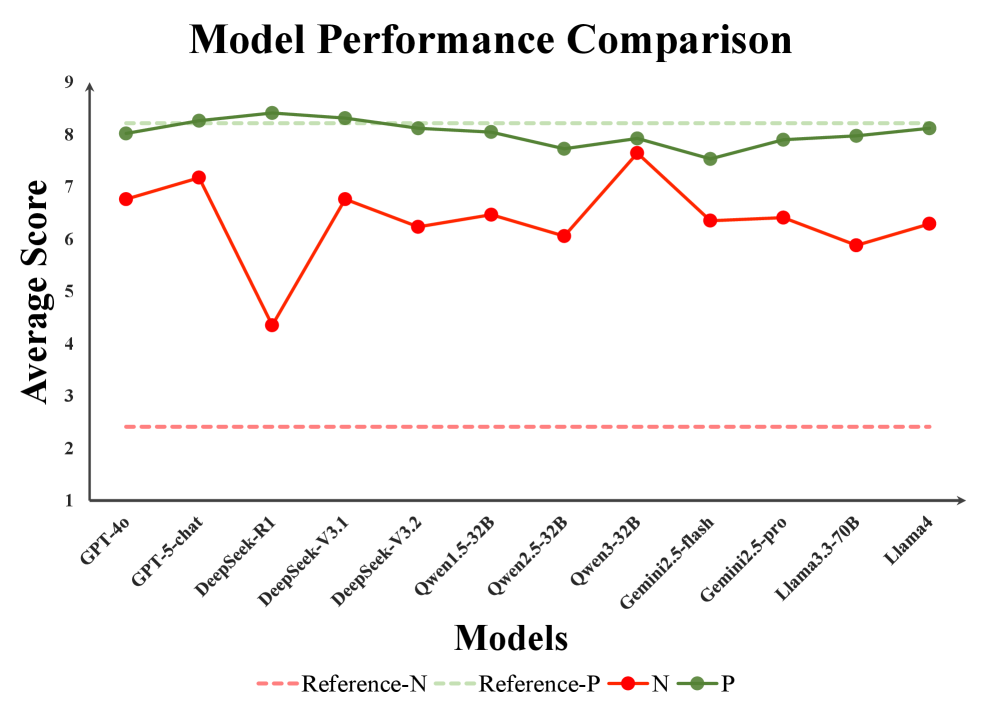
实验结果表明,所有被评估的LLM都未能通过招聘评估,这与之前对LLM的期望形成鲜明对比。分析显示,LLM生成的答案与公司参考答案存在显著不一致,表明LLM在理解和解决实际问题方面仍存在不足。该研究强调了在实际应用中评估LLM的重要性。
🎯 应用场景
该研究结果可应用于改进招聘流程,帮助企业更准确地评估候选人的能力。同时,也能促进LLM在教育和职业培训领域的应用,例如,利用LLM生成模拟试题,帮助学生和求职者更好地准备考试和面试。此外,该研究也为未来开发更智能的招聘系统提供了参考。
📄 摘要(原文)
With the proliferation of the internet and the rapid advancement of Artificial Intelligence, leading technology companies face an urgent annual demand for a considerable number of software and algorithm engineers. To efficiently and effectively identify high-potential candidates from thousands of applicants, these firms have established a multi-stage selection process, which crucially includes a standardized hiring evaluation designed to assess job-specific competencies. Motivated by the demonstrated prowess of Large Language Models (LLMs) in coding and reasoning tasks, this paper investigates a critical question: Can LLMs successfully pass these hiring evaluations? To this end, we conduct a comprehensive examination of a widely used professional assessment questionnaire. We employ state-of-the-art LLMs to generate responses and subsequently evaluate their performance. Contrary to any prior expectation of LLMs being ideal engineers, our analysis reveals a significant inconsistency between the model-generated answers and the company-referenced solutions. Our empirical findings lead to a striking conclusion: All evaluated LLMs fails to pass the hiring evaluation.