A Graph Signal Processing Framework for Hallucination Detection in Large Language Models
作者: Valentin Noël
分类: cs.CL, cs.LG, eess.SP, stat.ML
发布日期: 2025-10-21
备注: Preprint under review (2025). 11 pages, 7 figures. Code and scripts: to be released
💡 一句话要点
提出基于图信号处理的框架,用于检测大型语言模型中的幻觉现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 图信号处理 Transformer 谱分析
📋 核心要点
- 大型语言模型容易产生幻觉,现有方法难以有效区分事实推理和幻觉。
- 将Transformer层建模为动态图,利用图信号处理分析token嵌入的谱特征,诊断幻觉。
- 实验表明,不同类型的幻觉具有不同的谱特征,基于谱特征的检测器准确率优于传统方法。
📝 摘要(中文)
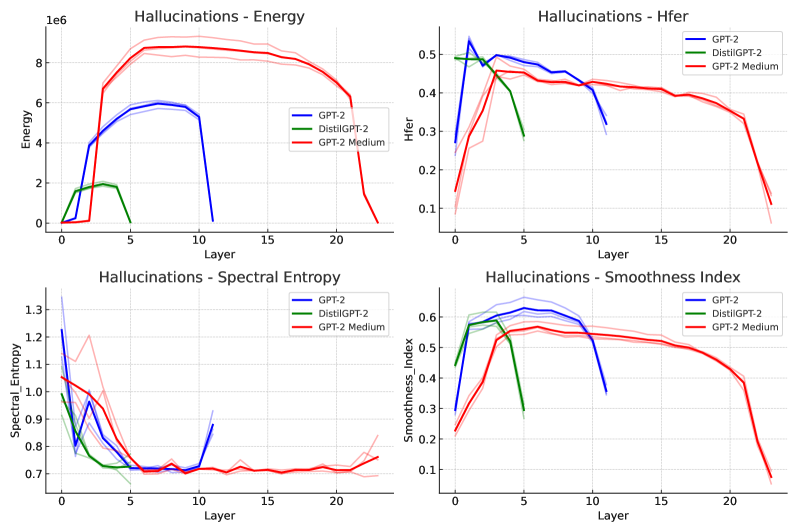
大型语言模型取得了显著成果,但区分事实推理和幻觉仍然具有挑战性。本文提出了一种谱分析框架,将Transformer层建模为由注意力机制诱导的动态图,并将token嵌入作为这些图上的信号。通过图信号处理,定义了包括Dirichlet能量、谱熵和高频能量比等诊断指标,并建立了与计算稳定性的理论联系。在GPT架构上的实验表明,存在通用的谱模式:事实陈述表现出一致的“能量山”行为,具有低频收敛性,而不同类型的幻觉则显示出不同的特征。逻辑矛盾会通过较大的效应量(g>1.0)来破坏谱的稳定性,语义错误保持稳定但显示出连接漂移,而替换幻觉则显示出中间扰动。一个使用谱特征的简单检测器实现了88.75%的准确率,而基于困惑度的基线方法为75%,证明了实际效用。这些发现表明,谱几何可能捕获推理模式和错误行为,从而为大型语言模型中的幻觉检测提供一个框架。
🔬 方法详解
问题定义:大型语言模型在生成文本时,经常出现与事实不符或逻辑矛盾的“幻觉”现象。现有的幻觉检测方法,如基于困惑度的方法,难以准确捕捉到这些细微的错误,缺乏对模型内部推理过程的理解。因此,如何有效地检测和区分不同类型的幻觉是亟待解决的问题。
核心思路:本文的核心思路是将Transformer层中的注意力机制视为一种动态图结构,其中token嵌入是图上的信号。通过分析这些图信号的谱特征,可以揭示模型内部的推理模式和错误行为。不同的幻觉类型可能会导致不同的谱特征,从而可以用于幻觉检测。
技术框架:该框架主要包含以下几个步骤:1) 将Transformer层建模为由注意力机制诱导的动态图。2) 将token嵌入作为图上的信号。3) 利用图信号处理技术,计算Dirichlet能量、谱熵和高频能量比等谱特征。4) 分析不同类型陈述(事实、逻辑矛盾、语义错误、替换幻觉)的谱特征差异。5) 基于谱特征构建幻觉检测器。
关键创新:该方法最重要的创新点在于将图信号处理技术引入到大型语言模型的幻觉检测中。通过将Transformer层建模为动态图,可以利用图信号处理的工具来分析模型内部的推理过程,从而更有效地检测和区分不同类型的幻觉。这与传统的基于困惑度的方法相比,具有更强的解释性和更高的准确率。
关键设计:在图构建方面,使用注意力权重作为边的权重。在信号处理方面,使用了Dirichlet能量来衡量信号的平滑度,谱熵来衡量信号的复杂度,高频能量比来衡量信号的高频成分。这些指标的选择基于对计算稳定性的理论联系。检测器使用简单的线性分类器,输入是谱特征,输出是幻觉类型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够有效区分不同类型的幻觉。基于谱特征的幻觉检测器实现了88.75%的准确率,显著优于基于困惑度的基线方法(75%)。逻辑矛盾会导致谱的显著不稳定(g>1.0),语义错误则表现出连接漂移,证明了谱特征与幻觉类型之间的关联性。
🎯 应用场景
该研究成果可应用于提高大型语言模型的可靠性和安全性。通过检测和纠正幻觉,可以提升模型在信息检索、问答系统、文本生成等领域的应用效果。此外,该方法还可以用于分析模型的推理过程,帮助研究人员更好地理解和改进大型语言模型。
📄 摘要(原文)
Large language models achieve impressive results but distinguishing factual reasoning from hallucinations remains challenging. We propose a spectral analysis framework that models transformer layers as dynamic graphs induced by attention, with token embeddings as signals on these graphs. Through graph signal processing, we define diagnostics including Dirichlet energy, spectral entropy, and high-frequency energy ratios, with theoretical connections to computational stability. Experiments across GPT architectures suggest universal spectral patterns: factual statements exhibit consistent "energy mountain" behavior with low-frequency convergence, while different hallucination types show distinct signatures. Logical contradictions destabilize spectra with large effect sizes ($g>1.0$), semantic errors remain stable but show connectivity drift, and substitution hallucinations display intermediate perturbations. A simple detector using spectral signatures achieves 88.75% accuracy versus 75% for perplexity-based baselines, demonstrating practical utility. These findings indicate that spectral geometry may capture reasoning patterns and error behaviors, potentially offering a framework for hallucination detection in large language models.