When Can We Trust LLMs in Mental Health? Large-Scale Benchmarks for Reliable LLM Evaluation
作者: Abeer Badawi, Elahe Rahimi, Md Tahmid Rahman Laskar, Sheri Grach, Lindsay Bertrand, Lames Danok, Jimmy Huang, Frank Rudzicz, Elham Dolatabadi
分类: cs.CL, cs.CY, cs.HC
发布日期: 2025-10-21
🔗 代码/项目: GITHUB
💡 一句话要点
提出MentalBench和MentalAlign,用于可靠评估LLM在心理健康领域的应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理健康 基准测试 可靠性评估 情感认知一致性
📋 核心要点
- 现有心理健康领域LLM评估benchmark规模有限,依赖合成数据,缺乏对LLM评判器可靠性的评估。
- 论文提出MentalBench和MentalAlign,通过大规模真实对话数据和LLM评判器与人类专家的对比,构建可靠的评估框架。
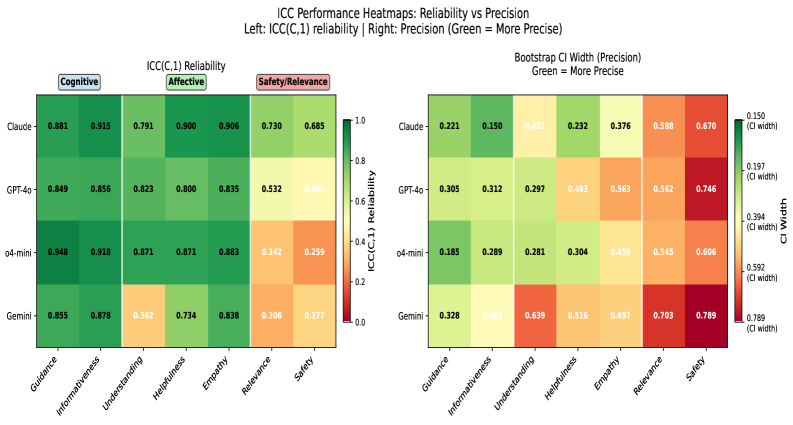
- 实验表明,LLM评判器在认知属性上可靠性高,但在情感属性上精度降低,安全性和相关性方面存在一定不可靠性。
📝 摘要(中文)
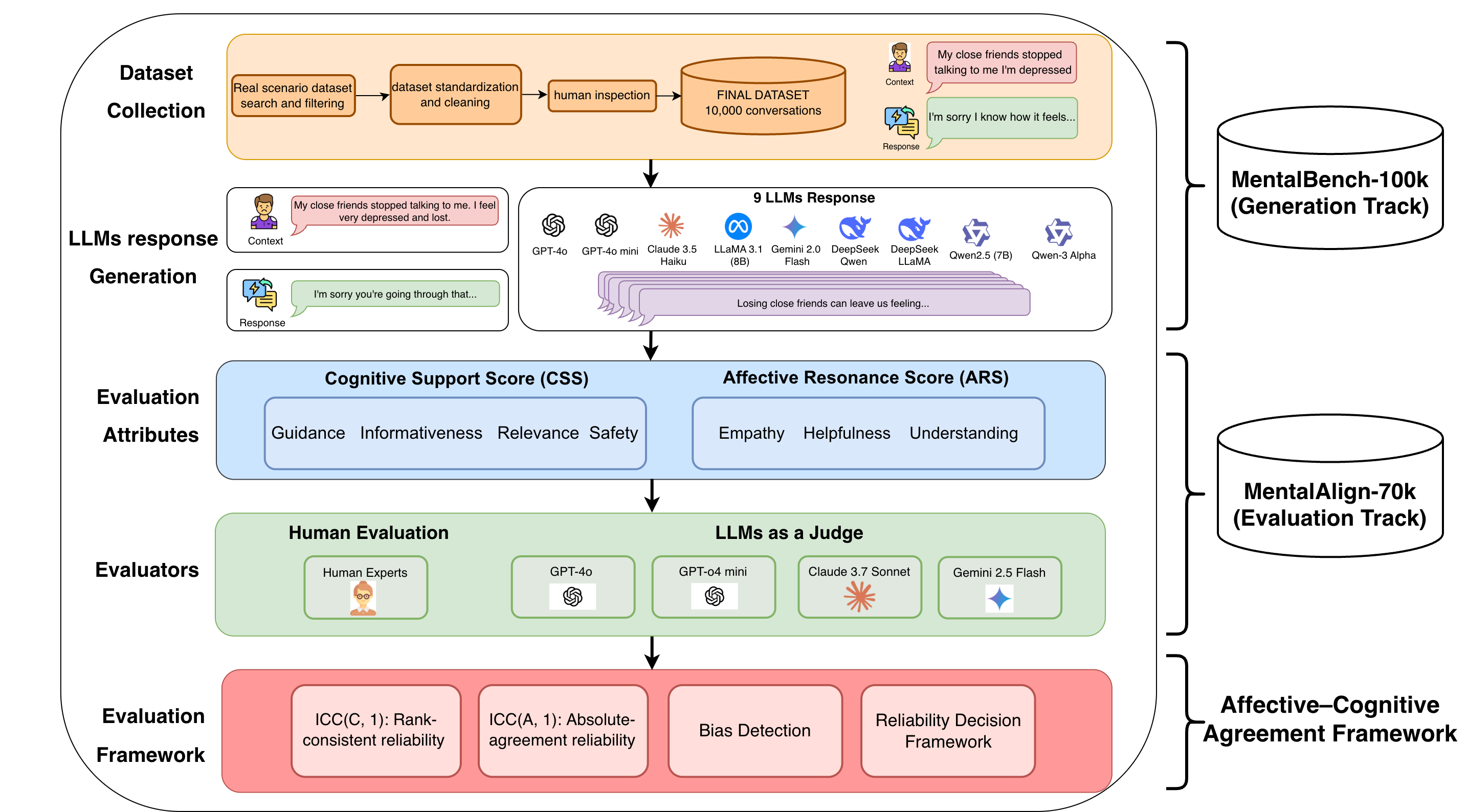
由于治疗性对话在情感和认知上的复杂性,评估大型语言模型(LLM)在心理健康支持方面的应用极具挑战性。现有的基准测试在规模和可靠性方面存在局限性,通常依赖于合成数据或社交媒体数据,并且缺乏评估自动评判器何时可信的框架。为了解决大规模对话数据集和评判器可靠性评估的需求,我们引入了两个基准测试,为生成和评估提供了一个框架。MentalBench-100k整合了来自三个真实场景数据集的10,000个单轮对话,每个对话都配有九个LLM生成的回复,从而产生了100,000个回复对。MentalAlign-70k通过比较四个高性能LLM评判器与人类专家在七个属性上的70,000个评分,重新构建了评估框架,这些属性被分为认知支持评分(CSS)和情感共鸣评分(ARS)。然后,我们采用情感认知一致性框架,这是一种使用组内相关系数(ICC)和置信区间的统计方法,来量化LLM评判器和人类专家之间的一致性、稳定性和偏差。我们的分析表明,LLM评判器存在系统性高估,在指导和信息性等认知属性方面具有很高的可靠性,在共情方面精度降低,在安全性和相关性方面存在一定程度的不可靠性。我们的贡献为可靠的大规模LLM心理健康评估奠定了新的方法论和经验基础。我们在https://github.com/abeerbadawi/MentalBench/发布了基准测试和代码。
🔬 方法详解
问题定义:现有心理健康领域的大型语言模型(LLM)评估方法存在局限性,主要体现在数据集规模小、数据质量不高(依赖合成或社交媒体数据),以及缺乏对LLM作为评判者时其可靠性的系统评估。这使得我们难以信任LLM在心理健康支持方面的能力,也无法准确衡量不同LLM在该领域的表现。现有方法的痛点在于无法提供一个大规模、高质量、可信赖的评估框架,从而阻碍了LLM在心理健康领域的应用。
核心思路:论文的核心思路是构建两个大规模的基准测试数据集(MentalBench和MentalAlign),并采用统计方法(情感认知一致性框架)来量化LLM评判器与人类专家在心理健康相关属性上的评分一致性。通过这种方式,可以评估LLM作为评判者的可靠性,并为LLM在心理健康领域的评估提供更可靠的依据。这样设计的目的是为了解决现有评估方法的局限性,提供一个更全面、更可靠的评估框架。
技术框架:整体框架包含两个主要部分:数据集构建和评判器评估。数据集构建包括MentalBench-100k和MentalAlign-70k。MentalBench-100k包含10,000个单轮对话,每个对话配有9个LLM生成的回复,共计100,000个回复对。MentalAlign-70k包含70,000个评分,由4个高性能LLM评判器和人类专家对7个属性进行评分。评判器评估使用情感认知一致性框架,该框架使用组内相关系数(ICC)和置信区间来量化LLM评判器和人类专家之间的一致性、稳定性和偏差。
关键创新:最重要的技术创新点在于提出了情感认知一致性框架,并将其应用于评估LLM评判器在心理健康领域的可靠性。该框架能够量化LLM评判器与人类专家在不同属性上的评分一致性,从而揭示LLM评判器在哪些方面是可靠的,哪些方面是不可靠的。与现有方法相比,该框架提供了一种更系统、更客观的评估方法,可以帮助研究人员更好地理解LLM在心理健康领域的局限性。
关键设计:MentalAlign-70k数据集的关键设计在于选择了七个与心理健康相关的属性进行评估,包括认知支持评分(CSS)和情感共鸣评分(ARS)。这些属性涵盖了LLM在心理健康支持方面的关键能力,例如指导、信息性、共情、安全性和相关性。情感认知一致性框架的关键设计在于使用组内相关系数(ICC)来量化LLM评判器和人类专家之间的一致性。ICC是一种常用的统计指标,可以衡量不同评判者之间的评分一致性,并提供置信区间来评估结果的可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM评判器在认知属性(如指导和信息性)上具有较高的可靠性,但在情感属性(如共情)上精度较低。此外,LLM评判器在安全性和相关性方面存在一定程度的不可靠性。这些发现为LLM在心理健康领域的应用提供了重要的指导,表明需要谨慎使用LLM进行情感支持,并加强对安全性和相关性的评估。
🎯 应用场景
该研究成果可应用于开发更可靠的心理健康辅助工具,例如智能心理咨询机器人、情感支持聊天机器人等。通过评估LLM在心理健康领域的可靠性,可以帮助开发者选择更合适的LLM模型,并设计更有效的干预策略。此外,该研究还可以为心理健康领域的伦理规范提供参考,确保LLM的应用不会对用户造成伤害。
📄 摘要(原文)
Evaluating Large Language Models (LLMs) for mental health support is challenging due to the emotionally and cognitively complex nature of therapeutic dialogue. Existing benchmarks are limited in scale, reliability, often relying on synthetic or social media data, and lack frameworks to assess when automated judges can be trusted. To address the need for large-scale dialogue datasets and judge reliability assessment, we introduce two benchmarks that provide a framework for generation and evaluation. MentalBench-100k consolidates 10,000 one-turn conversations from three real scenarios datasets, each paired with nine LLM-generated responses, yielding 100,000 response pairs. MentalAlign-70k}reframes evaluation by comparing four high-performing LLM judges with human experts across 70,000 ratings on seven attributes, grouped into Cognitive Support Score (CSS) and Affective Resonance Score (ARS). We then employ the Affective Cognitive Agreement Framework, a statistical methodology using intraclass correlation coefficients (ICC) with confidence intervals to quantify agreement, consistency, and bias between LLM judges and human experts. Our analysis reveals systematic inflation by LLM judges, strong reliability for cognitive attributes such as guidance and informativeness, reduced precision for empathy, and some unreliability in safety and relevance. Our contributions establish new methodological and empirical foundations for reliable, large-scale evaluation of LLMs in mental health. We release the benchmarks and codes at: https://github.com/abeerbadawi/MentalBench/