Evaluating LLM Story Generation through Large-scale Network Analysis of Social Structures
作者: Hiroshi Nonaka, K. E. Perry
分类: cs.CL, cs.LG
发布日期: 2025-10-21
备注: This paper has 14 pages and 8 figures. To be presented at the NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling
💡 一句话要点
提出基于社交结构网络分析的大规模LLM故事生成评估方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM故事生成 社交网络分析 文本评估 创造力评估 角色关系网络
📋 核心要点
- 现有LLM故事生成评估依赖人工,成本高昂且难以规模化,阻碍了对模型创造力的全面评估。
- 该论文提出通过分析故事中角色间的社交关系网络,量化评估LLM生成故事的质量和特点。
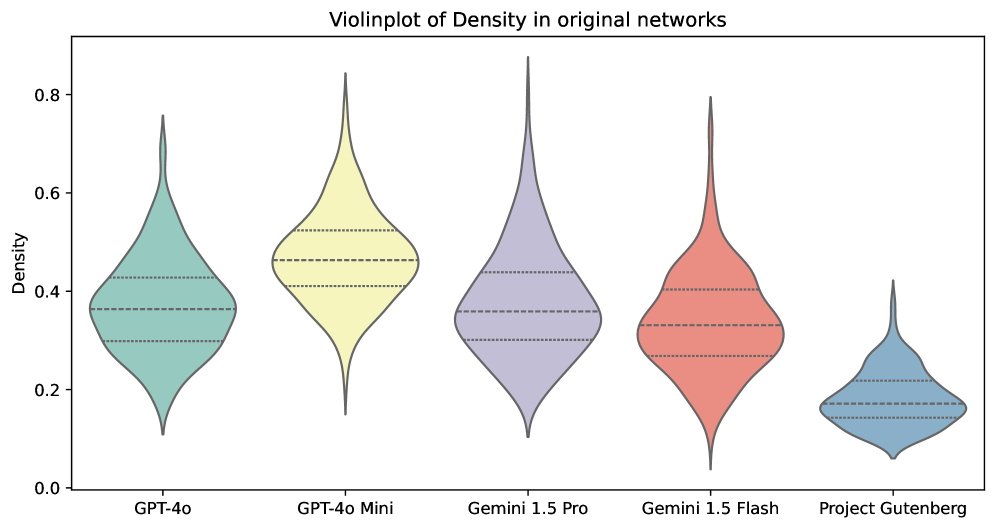
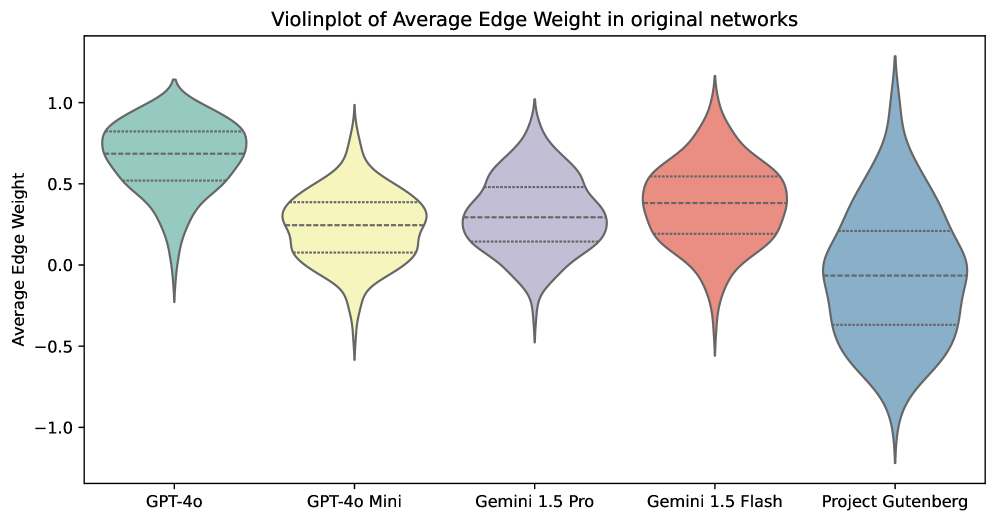
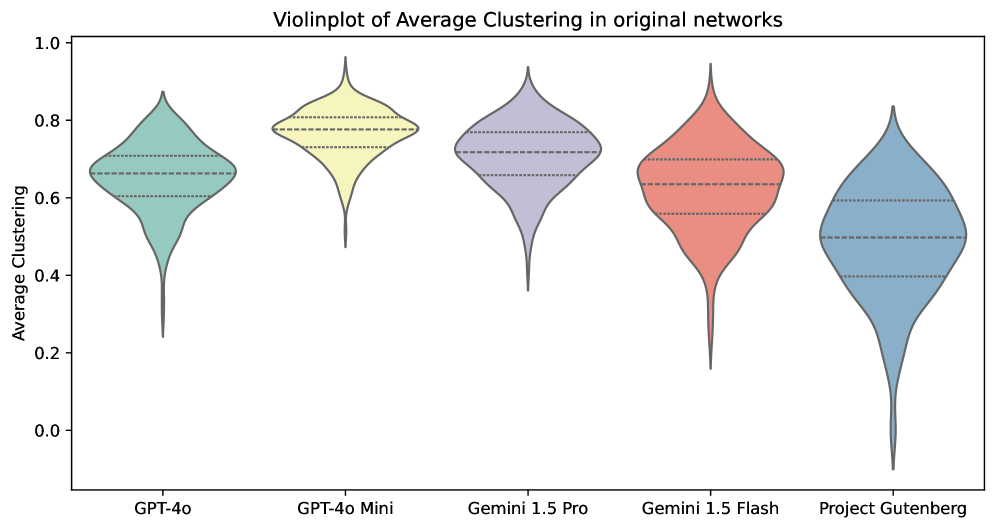
- 实验结果表明,LLM生成的故事在社交关系上存在偏差,倾向于积极和紧密的关系,验证了该方法的有效性。
📝 摘要(中文)
评估大型语言模型(LLM)在复杂任务中的创造能力通常需要难以规模化的人工评估。本文提出了一种新颖、可扩展的方法,通过分析叙事中潜在的社交结构(表示为有符号的角色网络)来评估LLM的故事生成能力。为了展示其有效性,我们使用由四个领先的LLM(GPT-4o、GPT-4o mini、Gemini 1.5 Pro和Gemini 1.5 Flash)以及人类编写的语料库生成的1200多个故事的网络进行大规模比较分析。我们的研究结果基于网络属性(如密度、聚类和有符号的边权重)表明,LLM生成的故事始终表现出对紧密、积极关系的强烈偏好,这与先前使用人工评估的研究结果一致。我们提出的方法为评估当前和未来LLM在创造性故事讲述方面的局限性和倾向提供了一个有价值的工具。
🔬 方法详解
问题定义:论文旨在解决如何大规模、客观地评估LLM生成故事的质量和创造力的问题。现有方法主要依赖人工评估,耗时耗力,且主观性强,难以对大量故事进行评估,也难以发现LLM在故事生成方面的潜在偏差和局限性。
核心思路:论文的核心思路是将故事中的角色关系抽象为有符号的社交网络,通过分析网络的结构特征(如密度、聚类系数、边权重等)来量化评估故事的质量。这种方法将主观的叙事评估转化为客观的网络分析,从而实现大规模、自动化的评估。
技术框架:该方法主要包含以下几个步骤:1) 从故事文本中提取角色及其关系(包括积极和消极关系);2) 构建有符号的角色网络,其中节点代表角色,边代表角色之间的关系,边的权重表示关系的强度和极性;3) 计算网络的结构特征,如密度、聚类系数、平均路径长度、模块化等;4) 将这些网络特征与人类编写的故事的网络特征进行比较,从而评估LLM生成故事的质量和特点。
关键创新:该方法最重要的创新点在于将社交网络分析引入到LLM故事生成的评估中。与传统的基于文本的评估方法相比,该方法能够更深入地捕捉故事中角色关系的复杂性和动态性,从而更全面地评估LLM的创造力。此外,该方法还具有可扩展性,可以用于评估大量故事。
关键设计:在构建社交网络时,需要定义角色之间关系的提取规则和权重计算方法。例如,可以使用自然语言处理技术来识别故事中描述角色关系的句子,并根据句子的情感极性和强度来确定边的权重。此外,还需要选择合适的网络结构特征来反映故事的质量。例如,高密度和高聚类系数可能表示故事中的角色关系过于紧密,缺乏冲突和变化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM生成的故事在社交网络结构上与人类编写的故事存在显著差异。具体来说,LLM生成的故事倾向于具有更高的网络密度和聚类系数,表明角色关系更加紧密和积极。这与先前使用人工评估的研究结果一致,验证了该方法的有效性。该研究对GPT-4o, GPT-4o mini, Gemini 1.5 Pro, 和 Gemini 1.5 Flash等模型进行了对比分析。
🎯 应用场景
该研究成果可应用于LLM故事生成能力的评估与改进,帮助开发者了解模型的优势与不足,并针对性地进行优化。此外,该方法还可扩展到其他类型的文本生成任务,如剧本创作、新闻报道等,为评估文本生成质量提供了一种新的思路。该方法还有助于理解人类故事创作的模式,为AI创作提供借鉴。
📄 摘要(原文)
Evaluating the creative capabilities of large language models (LLMs) in complex tasks often requires human assessments that are difficult to scale. We introduce a novel, scalable methodology for evaluating LLM story generation by analyzing underlying social structures in narratives as signed character networks. To demonstrate its effectiveness, we conduct a large-scale comparative analysis using networks from over 1,200 stories, generated by four leading LLMs (GPT-4o, GPT-4o mini, Gemini 1.5 Pro, and Gemini 1.5 Flash) and a human-written corpus. Our findings, based on network properties like density, clustering, and signed edge weights, show that LLM-generated stories consistently exhibit a strong bias toward tightly-knit, positive relationships, which aligns with findings from prior research using human assessment. Our proposed approach provides a valuable tool for evaluating limitations and tendencies in the creative storytelling of current and future LLMs.