Misinformation Detection using Large Language Models with Explainability
作者: Jainee Patel, Chintan Bhatt, Himani Trivedi, Thanh Thi Nguyen
分类: cs.CL, cs.AI
发布日期: 2025-10-21
备注: Accepted for publication in the Proceedings of the 8th International Conference on Algorithms, Computing and Artificial Intelligence (ACAI 2025)
💡 一句话要点
提出一种可解释的轻量级PLM框架,用于高效且可信地检测虚假信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 虚假信息检测 预训练语言模型 可解释性AI LIME SHAP DistilBERT RoBERTa
📋 核心要点
- 在线平台虚假信息传播迅速,损害信任并阻碍明智决策,现有方法缺乏效率和可解释性。
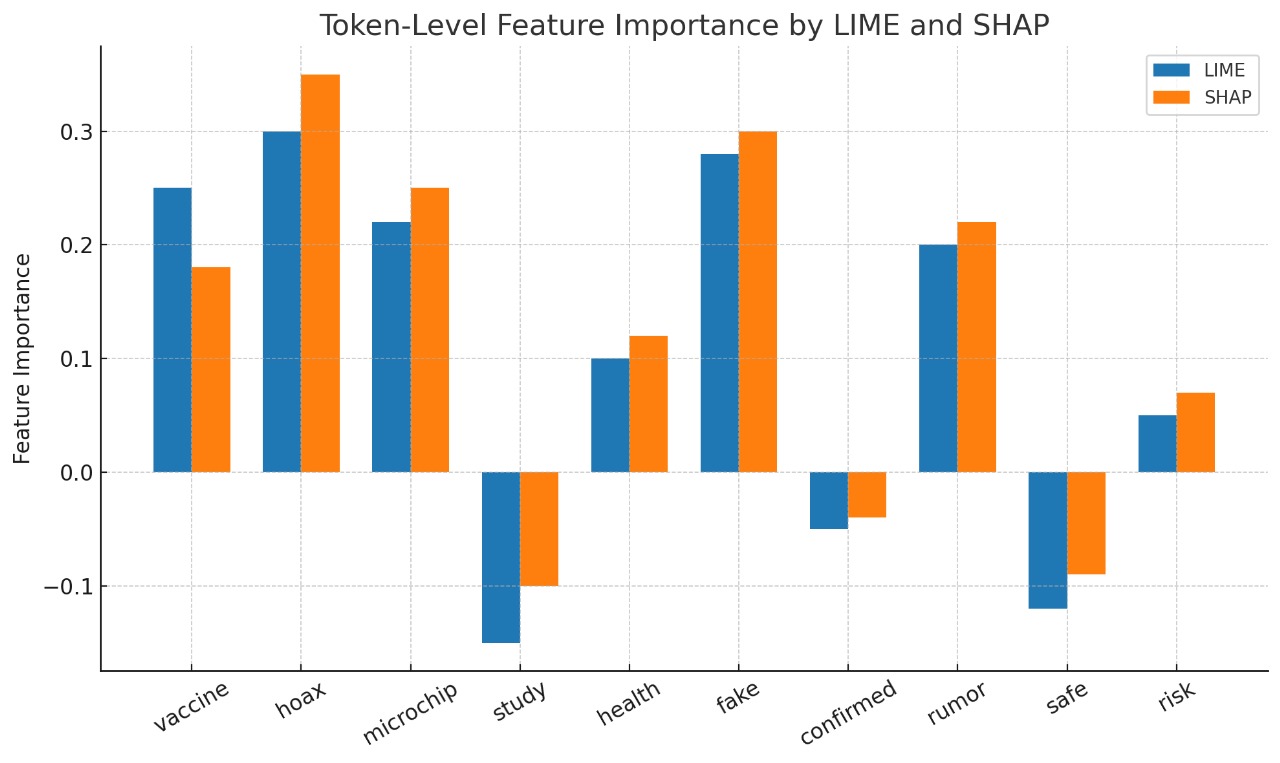
- 采用两阶段微调策略优化RoBERTa和DistilBERT,并结合LIME和SHAP提供token级别和全局特征级别的解释。
- 实验表明,轻量级模型DistilBERT在计算资源消耗更少的情况下,性能与RoBERTa相当,同时保证了可解释性。
📝 摘要(中文)
本文提出了一种可解释且计算高效的流水线,利用基于Transformer的预训练语言模型(PLM)来检测虚假信息。我们采用两步策略优化RoBERTa和DistilBERT:首先,冻结骨干网络,仅训练分类头;然后,逐步解冻骨干网络层,同时应用逐层学习率衰减。在两个真实世界的基准数据集COVID Fake News和FakeNewsNet GossipCop上,我们使用统一的预处理协议和分层分割来测试所提出的方法。为了确保透明性,我们集成了token级别的局部可解释模型无关解释(LIME)来呈现token级别的理由,以及全局特征归因级别的SHapley加性解释(SHAP)。实验表明,DistilBERT在需要显著更少计算资源的情况下,实现了与RoBERTa相当的准确率。这项工作做出了两个关键贡献:(1)定量地表明,轻量级PLM可以在保持任务性能的同时显著降低计算成本;(2)提出了一个可解释的流水线,该流水线检索忠实的局部和全局理由,而不会影响性能。结果表明,PLM与有原则的微调和可解释性相结合,可以成为可扩展、可信的虚假信息检测的有效框架。
🔬 方法详解
问题定义:论文旨在解决在线平台中虚假信息快速传播的问题。现有方法通常计算成本高昂,并且缺乏透明性和可解释性,难以让用户信任其判断结果。因此,需要一种既高效又能提供可信解释的虚假信息检测方法。
核心思路:论文的核心思路是利用轻量级的预训练语言模型(PLM),并通过精细的微调策略和可解释性方法,在保证性能的同时降低计算成本并提高模型的可信度。通过两阶段微调,先快速训练分类头,再逐步解冻骨干网络,可以有效地利用PLM的知识,并避免灾难性遗忘。结合LIME和SHAP,可以提供token级别和全局特征级别的解释,增强模型的可解释性。
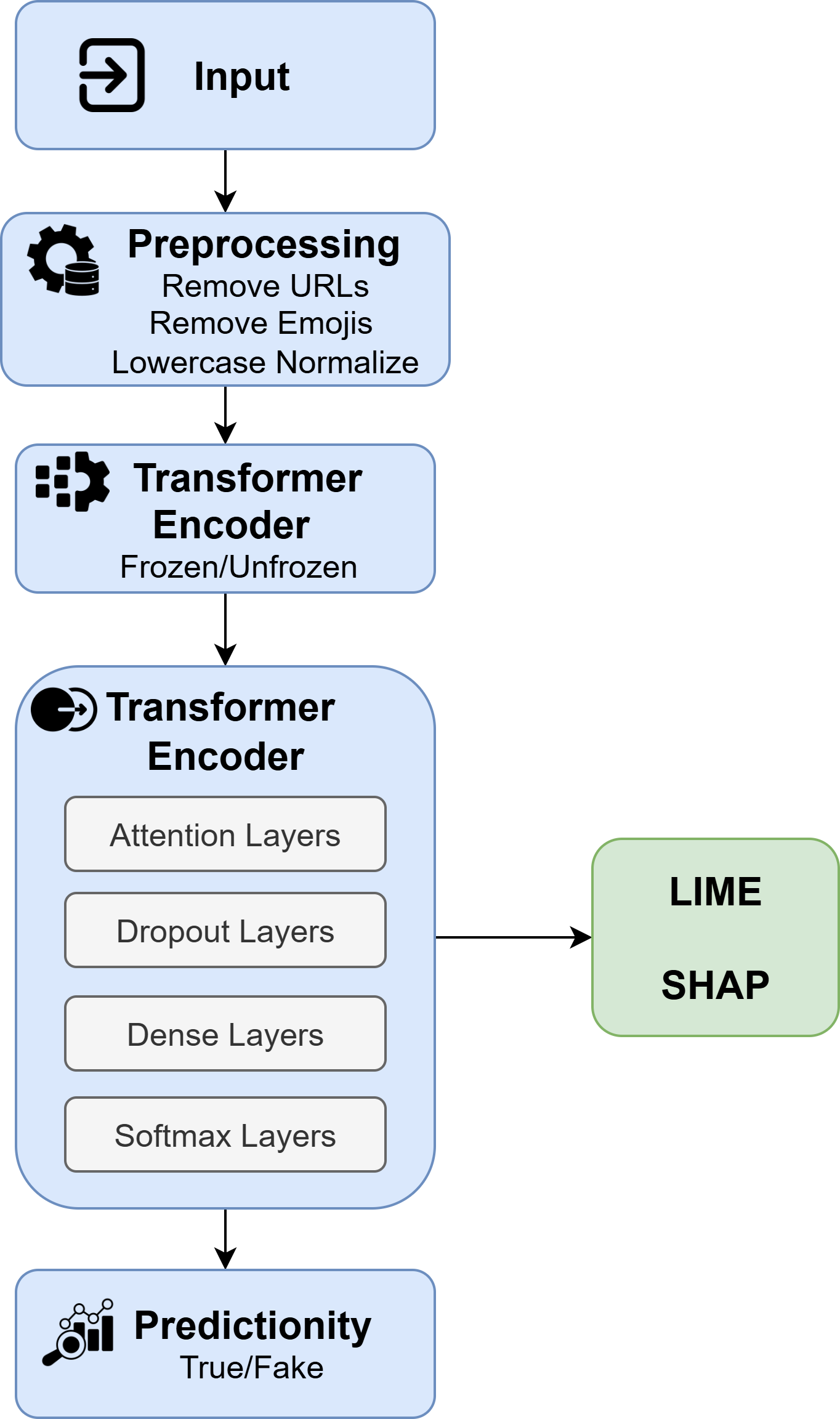
技术框架:整体框架包括以下几个主要阶段:1) 数据预处理:对文本数据进行清洗和标准化。2) 模型选择:选择RoBERTa和DistilBERT作为基础PLM。3) 两阶段微调:首先冻结骨干网络,训练分类头;然后逐步解冻骨干网络,并应用逐层学习率衰减。4) 可解释性分析:使用LIME和SHAP分别进行局部和全局的可解释性分析。5) 性能评估:在基准数据集上评估模型的准确率和计算效率。
关键创新:论文的关键创新在于:1) 提出了一种两阶段微调策略,可以有效地优化PLM,并在保证性能的同时降低计算成本。2) 集成了LIME和SHAP,提供token级别和全局特征级别的解释,增强了模型的可解释性和可信度。3) 证明了轻量级PLM(如DistilBERT)在虚假信息检测任务中可以达到与大型PLM(如RoBERTa)相当的性能,同时显著降低计算成本。
关键设计:两阶段微调策略中,逐层解冻骨干网络时,应用逐层学习率衰减,即越靠近输出层的学习率越高,越靠近输入层的学习率越低。LIME用于解释单个样本的预测结果,SHAP用于分析全局特征的重要性。具体参数设置(如学习率、batch size、epoch数等)在论文中有详细描述,但此处未提供具体数值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DistilBERT在COVID Fake News和FakeNewsNet GossipCop数据集上取得了与RoBERTa相当的准确率,同时显著降低了计算成本。LIME和SHAP的集成提供了token级别和全局特征级别的解释,增强了模型的可解释性。这些结果验证了轻量级PLM结合可解释性方法在虚假信息检测任务中的有效性。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻网站等,自动检测和标记虚假信息,帮助用户识别和过滤不实内容,从而提高信息的可信度和透明度。此外,该方法的可解释性使其能够为用户提供判断依据,增强用户对AI系统的信任,并促进负责任的AI应用。
📄 摘要(原文)
The rapid spread of misinformation on online platforms undermines trust among individuals and hinders informed decision making. This paper shows an explainable and computationally efficient pipeline to detect misinformation using transformer-based pretrained language models (PLMs). We optimize both RoBERTa and DistilBERT using a two-step strategy: first, we freeze the backbone and train only the classification head; then, we progressively unfreeze the backbone layers while applying layer-wise learning rate decay. On two real-world benchmark datasets, COVID Fake News and FakeNewsNet GossipCop, we test the proposed approach with a unified protocol of preprocessing and stratified splits. To ensure transparency, we integrate the Local Interpretable Model-Agnostic Explanations (LIME) at the token level to present token-level rationales and SHapley Additive exPlanations (SHAP) at the global feature attribution level. It demonstrates that DistilBERT achieves accuracy comparable to RoBERTa while requiring significantly less computational resources. This work makes two key contributions: (1) it quantitatively shows that a lightweight PLM can maintain task performance while substantially reducing computational cost, and (2) it presents an explainable pipeline that retrieves faithful local and global justifications without compromising performance. The results suggest that PLMs combined with principled fine-tuning and interpretability can be an effective framework for scalable, trustworthy misinformation detection.