UNO-Bench: A Unified Benchmark for Exploring the Compositional Law Between Uni-modal and Omni-modal in Omni Models
作者: Chen Chen, ZeYang Hu, Fengjiao Chen, Liya Ma, Jiaxing Liu, Xiaoyu Li, Ziwen Wang, Xuezhi Cao, Xunliang Cai
分类: cs.CL, cs.AI
发布日期: 2025-10-21 (更新: 2025-10-30)
备注: v3: Switch the paper template. Work in progress. Github: https://github.com/meituan-longcat/UNO-Bench Hugging Face: https://huggingface.co/datasets/meituan-longcat/UNO-Bench
💡 一句话要点
提出UNO-Bench,用于统一评估全模态模型中单模态与多模态的组合规律。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全模态模型 多模态学习 基准测试 单模态组合 跨模态推理
📋 核心要点
- 现有全模态模型缺乏对单模态与多模态组合规律的清晰理解,阻碍了模型智能的进一步发展。
- UNO-Bench通过统一的基准测试,系统性地评估单模态和全模态能力,揭示它们之间的内在联系。
- 实验结果表明,全模态能力对弱模型存在瓶颈效应,而对强模型则表现出协同促进作用。
📝 摘要(中文)
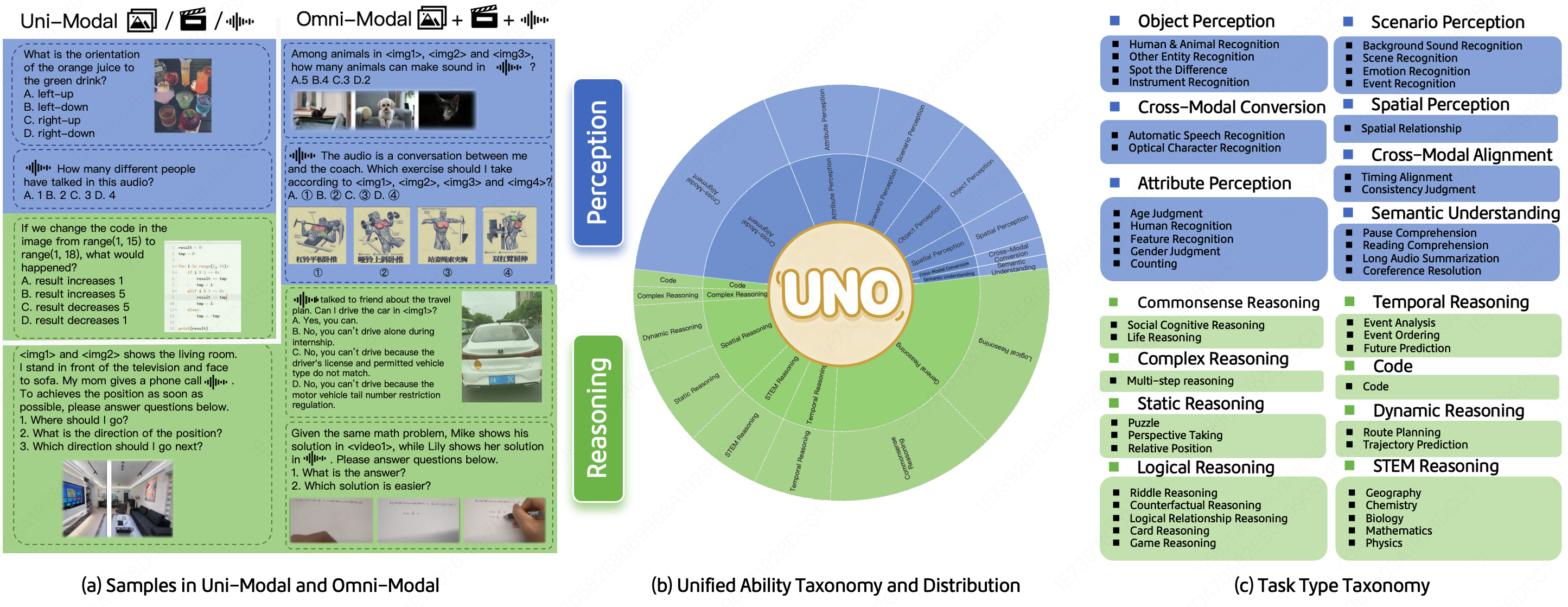
多模态大型语言模型正从单模态理解发展到统一视觉、音频和语言模态,统称为全模态模型。然而,单模态和全模态之间的相关性仍不清楚,这需要全面的评估来推动全模态模型智能的演进。本文提出了一个新颖、高质量且统一的全模态基准测试UNO-Bench。该基准旨在统一的能力分类下有效评估单模态和全模态能力,涵盖44种任务类型和5种模态组合。它包括1250个用于全模态的人工标注样本(98%的跨模态可解性)和2480个增强的单模态样本。人工生成的数据集非常适合真实场景,尤其是在中文语境中,而自动压缩的数据集提供了90%的速度提升,并在18个公共基准测试中保持了98%的一致性。除了传统的多项选择题外,还提出了一种创新的多步骤开放式问题形式来评估复杂的推理。集成了一个通用评分模型,支持6种问题类型,实现95%准确率的自动评估。实验结果表明全模态和单模态性能之间的组合规律,以及全模态能力在弱模型上表现为瓶颈效应,而在强模型上表现出协同促进作用。
🔬 方法详解
问题定义:现有全模态模型在理解和利用不同模态信息之间的关系方面存在不足。缺乏一个统一的评估框架来系统地分析单模态和多模态能力之间的相互作用,导致模型设计和优化缺乏理论指导。现有方法难以有效评估模型在复杂推理场景下的表现,并且在自动化评估方面存在准确率不足的问题。
核心思路:UNO-Bench的核心思路是构建一个高质量、统一的基准测试,涵盖多种模态组合和任务类型,从而全面评估全模态模型。通过人工标注和自动增强相结合的方式,构建既贴近真实场景又具有高效评估能力的数据集。引入多步骤开放式问题和通用评分模型,提升复杂推理评估的准确性和自动化程度。
技术框架:UNO-Bench包含以下主要组成部分:1) 统一的能力分类体系,涵盖44种任务类型和5种模态组合;2) 人工标注的全模态数据集,包含1250个样本,具有98%的跨模态可解性;3) 自动增强的单模态数据集,包含2480个样本;4) 多步骤开放式问题形式,用于评估复杂推理能力;5) 通用评分模型,支持6种问题类型,实现95%准确率的自动评估。
关键创新:UNO-Bench的关键创新在于:1) 统一的单模态和多模态评估框架,能够系统地分析它们之间的组合规律;2) 高质量的人工标注数据集,贴近真实场景,尤其是在中文语境下;3) 多步骤开放式问题形式,能够更有效地评估复杂推理能力;4) 通用评分模型,实现了高准确率的自动化评估。
关键设计:UNO-Bench在数据集构建方面,采用了人工标注和自动增强相结合的方式,以保证数据的质量和规模。在问题设计方面,引入了多步骤开放式问题,以评估模型的复杂推理能力。在评估方面,设计了一个通用评分模型,支持多种问题类型,并实现了95%的准确率。具体参数设置和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
UNO-Bench在18个公共基准测试中保持了98%的一致性,同时提供了90%的速度提升。通用评分模型实现了95%的自动化评估准确率。实验结果揭示了全模态能力对弱模型存在瓶颈效应,而对强模型则表现出协同促进作用,为全模态模型的研究提供了重要的理论指导。
🎯 应用场景
UNO-Bench可用于评估和比较不同的全模态模型,指导模型设计和优化,提升模型在跨模态理解、推理和生成等方面的能力。该基准测试在智能助手、自动驾驶、医疗诊断等领域具有广泛的应用前景,能够推动人工智能技术在真实场景中的落地。
📄 摘要(原文)
Multimodal Large Languages models have been progressing from uni-modal understanding toward unifying visual, audio and language modalities, collectively termed omni models. However, the correlation between uni-modal and omni-modal remains unclear, which requires comprehensive evaluation to drive omni model's intelligence evolution. In this work, we introduce a novel, high-quality, and UNified Omni model benchmark, UNO-Bench. This benchmark is designed to effectively evaluate both UNi-modal and Omni-modal capabilities under a unified ability taxonomy, spanning 44 task types and 5 modality combinations. It includes 1250 human curated samples for omni-modal with 98% cross-modality solvability, and 2480 enhanced uni-modal samples. The human-generated dataset is well-suited to real-world scenarios, particularly within the Chinese context, whereas the automatically compressed dataset offers a 90% increase in speed and maintains 98% consistency across 18 public benchmarks. In addition to traditional multi-choice questions, we propose an innovative multi-step open-ended question format to assess complex reasoning. A general scoring model is incorporated, supporting 6 question types for automated evaluation with 95% accuracy. Experimental result shows the Compositional Law between omni-modal and uni-modal performance and the omni-modal capability manifests as a bottleneck effect on weak models, while exhibiting synergistic promotion on strong models.