Learning from the Best, Differently: A Diversity-Driven Rethinking on Data Selection
作者: Hongyi He, Xiao Liu, Zhenghao Lin, Mingni Tang, Yi Cheng, Jintao Wang, Wenjie Li, Peng Cheng, Yeyun Gong
分类: cs.CL, cs.AI
发布日期: 2025-10-21
💡 一句话要点
提出ODiS算法,通过正交解耦数据质量评估维度,提升LLM预训练数据选择的多样性与质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练数据选择 数据多样性 正交化 主成分分析 Roberta 知识质量 语言质量
📋 核心要点
- 现有基于单一或多维评分的数据选择方法,在选择LLM预训练数据时,忽略了数据多样性,导致下游任务性能下降。
- 论文提出ODiS算法,通过PCA将多维数据质量评估指标正交化,在每个正交维度上选择高质量数据,保证数据多样性。
- 实验表明,使用ODiS选择的数据训练的LLM,在下游任务上显著优于其他基线方法,验证了正交多样性数据选择的有效性。
📝 摘要(中文)
高质量的预训练数据对于大型语言模型至关重要,其中质量体现在事实可靠性和语义价值,而多样性确保了广泛的覆盖范围和分布异质性。现有方法通常依赖于单一或多维的基于分数的选择。然而,直接选择得分最高的数据往往会降低性能,需要从更广泛的范围内进行采样才能恢复结果。数据集得分与下游基准测试结果之间的上述非单调性揭示了一个根本偏差:基于分数的方法会折叠相关维度,导致得分最高的数据看起来质量很高,同时系统地忽略了多样性。我们认为,确保多样性需要将相关指标分解为正交的特征维度,从中可以直接选择得分最高的数据。因此,我们提出了正交多样性感知选择(ODiS)算法,该算法在数据选择过程中同时保留了质量和多样性。首先,ODiS从多个维度评估数据,包括语言质量、知识质量和理解难度。然后通过主成分分析(PCA)对多维分数进行去相关,从而产生正交的评估维度。对于每个维度,训练一个基于Roberta的评分器,将数据回归到PCA投影的分数上,从而实现对大型语料库的可扩展推理。最后,ODiS通过选择每个正交维度内得分最高的数据来构建训练数据集,从而确保质量和多样性。实验结果表明,ODiS选择的数据的维度间重叠小于2%,证实了维度之间的正交性。更重要的是,使用ODiS选择的数据训练的模型在下游基准测试中明显优于其他基线,突出了正交的、多样性感知的数据选择对于LLM的必要性。
🔬 方法详解
问题定义:现有的大型语言模型预训练数据选择方法,通常基于单一或多维的分数进行选择,例如困惑度、信息量等。这些方法倾向于选择高分数据,但忽略了数据之间的相关性,导致选择的数据集缺乏多样性,最终影响了下游任务的性能。现有方法的痛点在于无法在保证数据质量的同时,兼顾数据的多样性。
核心思路:论文的核心思路是将数据质量评估的多个维度进行解耦,使其相互正交,从而避免选择高度相关的数据。通过正交化,每个维度代表了数据质量的一个独立方面,然后在每个维度上选择高质量的数据,从而保证整体数据集的多样性。这样设计的目的是为了解决现有方法中存在的“高分数据同质化”问题,确保模型能够学习到更广泛的知识和模式。
技术框架:ODiS算法的技术框架主要包含以下几个阶段: 1. 多维数据评估:从多个维度评估数据,例如语言质量、知识质量和理解难度。 2. 正交化处理:使用主成分分析(PCA)对多维分数进行去相关,得到正交的评估维度。 3. 维度评分器训练:针对每个正交维度,训练一个基于Roberta的评分器,用于预测数据在该维度上的得分。 4. 数据选择:在每个正交维度上,选择得分最高的数据,构建最终的训练数据集。
关键创新:ODiS算法最重要的技术创新点在于将数据质量评估的多个维度进行正交解耦。与现有方法直接基于原始分数进行选择不同,ODiS通过PCA将相关维度转化为不相关的正交维度,从而避免了选择高度相似的数据,保证了数据集的多样性。这种正交化的思想是ODiS算法的核心,也是其能够提升下游任务性能的关键。
关键设计: 1. 多维评估指标选择:论文选择了语言质量、知识质量和理解难度作为评估维度,这些维度覆盖了数据质量的多个重要方面。 2. PCA参数设置:PCA用于将多维分数投影到正交维度上,需要选择合适的维度数量,以平衡计算复杂度和信息损失。 3. Roberta评分器训练:使用Roberta模型作为评分器,需要选择合适的训练数据和损失函数,以保证评分器的准确性和泛化能力。 4. 数据选择策略:在每个正交维度上选择得分最高的数据时,需要考虑数据集的大小限制,以及不同维度之间的数据比例。
🖼️ 关键图片


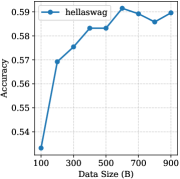
📊 实验亮点
实验结果表明,ODiS选择的数据集维度间重叠小于2%,验证了正交化的有效性。使用ODiS选择的数据训练的LLM,在多个下游基准测试中显著优于其他基线方法,例如在知识问答、文本摘要等任务上取得了明显的性能提升。具体提升幅度根据不同任务和数据集有所不同,但总体趋势表明ODiS能够有效提升LLM的性能。
🎯 应用场景
ODiS算法可应用于各种大型语言模型的预训练数据选择,尤其适用于需要高质量和多样性数据的场景,例如知识密集型任务、多语言模型训练等。该方法能够提升模型的泛化能力和鲁棒性,降低模型对特定类型数据的过拟合风险,具有广泛的应用前景。
📄 摘要(原文)
High-quality pre-training data is crutial for large language models, where quality captures factual reliability and semantic value, and diversity ensures broad coverage and distributional heterogeneity. Existing approaches typically rely on single or multiple-dimensional score-based selection. However, directly selecting top-scored data often degrades performance, and sampling from a broader range is required to recover results. The above non-monotonicity between dataset scores and downstream benchmark results reveals a fundamental bias: score-based methods collapse correlated dimensions, causing top-scored data to appear high-quality while systematically overlooking diversity. We argue that ensuring diversity requires decomposing correlated metrics into orthogonal feature dimensions, from which the top-scored data can be directly selected. Therefore, we proposed the Orthogonal Diversity-Aware Selection (ODiS) algorithm, which preserves both quality and diversity during data selection. First, ODiS evaluates data from multiple dimensions, covering language quality, knowledge quality, and comprehension difficulty. The multi-dimensional scores are then decorrelated via Principal Component Analysis (PCA), yielding orthogonal evaluation dimensions. For each dimension, a Roberta-based scorer is trained to regress the data onto PCA-projected scores, enabling scalable inference on large corpora. Finally, ODiS constructs the training dataset by selecting top-scored data within each orthogonal dimension, thereby ensuring both quality and diversity. Empirical results show that ODiS-selected data exhibit less than 2\% inter-dimension overlap, confirming orthogonality between dimensions. More importantly, models trained with ODiS-selected data significantly outperform other baselines on downstream benchmarks, highlighting the necessity of orthogonal, diversity-aware data selection for LLMs.