Improving Topic Modeling of Social Media Short Texts with Rephrasing: A Case Study of COVID-19 Related Tweets
作者: Wangjiaxuan Xin, Shuhua Yin, Shi Chen, Yaorong Ge
分类: cs.CL, cs.AI
发布日期: 2025-10-21
💡 一句话要点
提出TM-Rephrase框架,利用LLM重述社交媒体文本,提升主题建模效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主题建模 社交媒体分析 短文本处理 大型语言模型 文本重述
📋 核心要点
- 社交媒体短文本的简洁、非正式和噪声特性,导致传统主题建模方法效果不佳,难以产生连贯的主题。
- TM-Rephrase框架利用大型语言模型将社交媒体文本重述为更正式的语言,从而提高主题建模的性能。
- 实验结果表明,TM-Rephrase框架在主题一致性、唯一性和多样性方面均有提升,并减少了主题冗余。
📝 摘要(中文)
社交媒体平台(如Twitter)为分析公众讨论提供了丰富的数据,尤其是在COVID-19等危机期间。然而,社交媒体短文本的简洁性、非正式性和噪声通常会阻碍传统主题建模的有效性,产生不连贯或冗余的主题,难以解释。为了解决这些挑战,我们开发了TM-Rephrase,一个模型无关的框架,利用大型语言模型(LLM)将原始推文重述为更标准化和正式的语言,然后再进行主题建模。使用包含25027条与COVID-19相关的Twitter帖子数据集,我们研究了两种重述策略(通用重述和口语转正式重述)对多种主题建模方法的影响。结果表明,TM-Rephrase提高了衡量主题建模性能的三个指标(即主题一致性、主题唯一性和主题多样性),同时减少了大多数主题建模算法的主题冗余,其中口语转正式策略产生了最大的性能提升,特别是对于潜在狄利克雷分配(LDA)算法。这项研究为增强公共卫生相关社交媒体分析中的主题建模提供了一种模型无关的方法,对更好地理解健康危机以及其他重要领域中的公众讨论具有广泛的意义。
🔬 方法详解
问题定义:论文旨在解决社交媒体短文本主题建模中,由于文本的简洁、非正式和噪声特性,导致传统主题建模方法效果不佳的问题。现有方法难以提取出连贯、有意义的主题,且容易产生冗余主题,影响分析结果的准确性和可解释性。
核心思路:论文的核心思路是利用大型语言模型(LLM)的文本生成能力,将原始的社交媒体短文本重述为更规范、更正式的表达形式。通过这种方式,可以减少文本中的噪声和歧义,提高文本的质量,从而改善主题建模的效果。
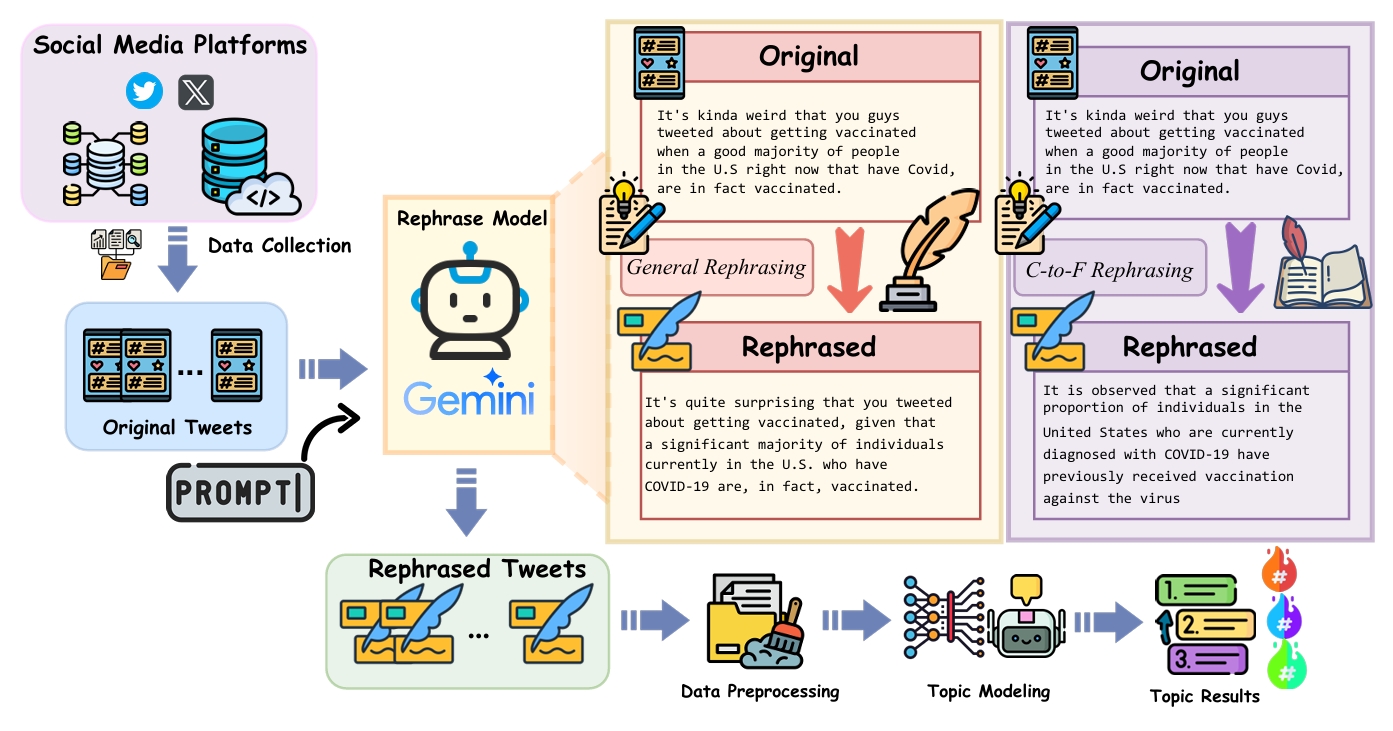
技术框架:TM-Rephrase框架主要包含两个阶段:1) 文本重述阶段:利用LLM将原始推文进行重述,生成更正式的文本。论文研究了两种重述策略:通用重述和口语转正式重述。2) 主题建模阶段:将重述后的文本输入到传统的主题建模算法(如LDA)中,提取主题。整个框架是模型无关的,可以与多种主题建模算法结合使用。
关键创新:该论文的关键创新在于提出了一个模型无关的框架,利用LLM来预处理社交媒体短文本,从而提高主题建模的性能。与直接使用原始文本进行主题建模的方法相比,TM-Rephrase能够有效地减少文本噪声,提高文本质量,从而改善主题建模的效果。
关键设计:论文中使用了两种重述策略:通用重述和口语转正式重述。通用重述旨在将文本转换为更标准的书面语,而口语转正式重述则更侧重于将口语化的表达方式转换为正式的表达方式。具体使用的LLM模型和参数设置在论文中未详细说明,属于未知信息。主题建模阶段使用了LDA等传统算法,具体参数设置也未详细说明,属于未知信息。
🖼️ 关键图片
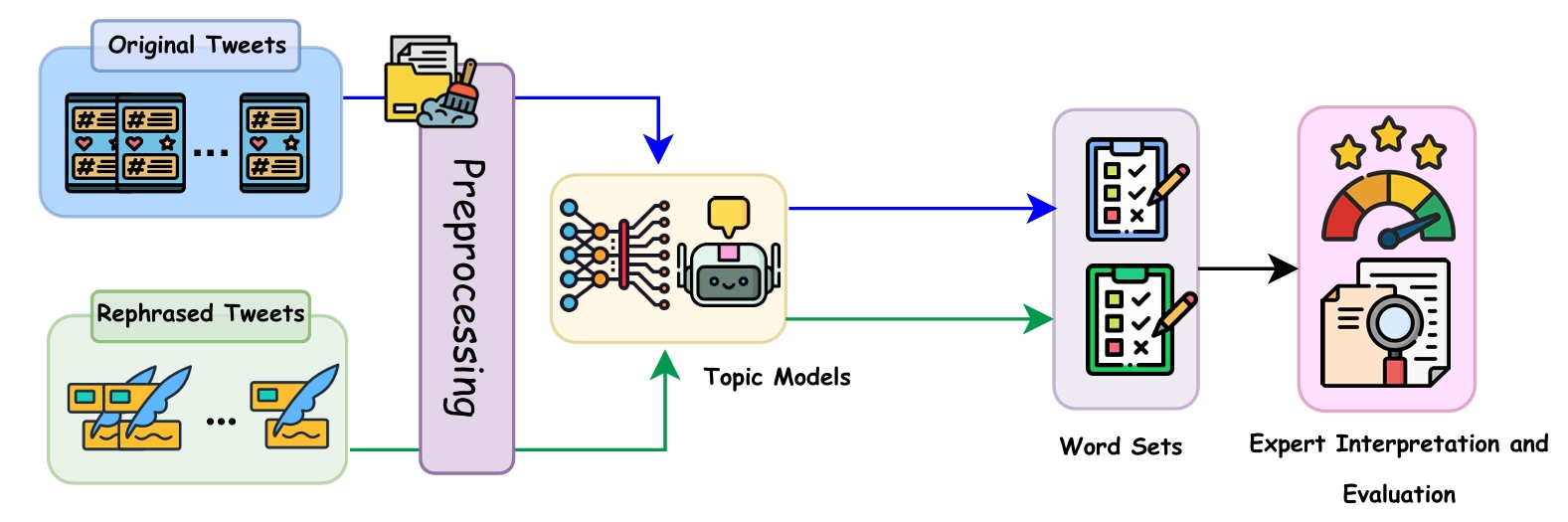
📊 实验亮点
实验结果表明,TM-Rephrase框架在主题一致性、主题唯一性和主题多样性三个指标上均有提升,并减少了主题冗余。其中,口语转正式重述策略效果最佳,尤其是在LDA算法上表现突出。具体的性能提升幅度在论文中未给出明确的数值,属于未知信息。
🎯 应用场景
该研究成果可应用于公共卫生事件舆情分析、社会热点话题挖掘、品牌声誉管理等领域。通过提升社交媒体文本主题建模的准确性和可解释性,可以帮助研究人员和决策者更好地理解公众观点、发现潜在风险,并制定更有效的应对策略。未来,该方法可以扩展到其他类型的短文本数据,如新闻评论、产品评价等。
📄 摘要(原文)
Social media platforms such as Twitter (now X) provide rich data for analyzing public discourse, especially during crises such as the COVID-19 pandemic. However, the brevity, informality, and noise of social media short texts often hinder the effectiveness of traditional topic modeling, producing incoherent or redundant topics that are often difficult to interpret. To address these challenges, we have developed \emph{TM-Rephrase}, a model-agnostic framework that leverages large language models (LLMs) to rephrase raw tweets into more standardized and formal language prior to topic modeling. Using a dataset of 25,027 COVID-19-related Twitter posts, we investigate the effects of two rephrasing strategies, general- and colloquial-to-formal-rephrasing, on multiple topic modeling methods. Results demonstrate that \emph{TM-Rephrase} improves three metrics measuring topic modeling performance (i.e., topic coherence, topic uniqueness, and topic diversity) while reducing topic redundancy of most topic modeling algorithms, with the colloquial-to-formal strategy yielding the greatest performance gains and especially for the Latent Dirichlet Allocation (LDA) algorithm. This study contributes to a model-agnostic approach to enhancing topic modeling in public health related social media analysis, with broad implications for improved understanding of public discourse in health crisis as well as other important domains.