DuoLens: A Framework for Robust Detection of Machine-Generated Multilingual Text and Code
作者: Shriyansh Agrawal, Aidan Lau, Sanyam Shah, Ahan M R, Kevin Zhu, Sunishchal Dev, Vasu Sharma
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-10-21
备注: Accepted to 39th Conference on Neural Information Processing Systems (NeurIPS 2025): 4th Workshop on Deep Learning for Code
期刊: Neural Information Processing Systems (NeurIPS 2025)
💡 一句话要点
提出DuoLens框架以解决机器生成多语言文本和代码检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器生成内容 多语言检测 小型语言模型 RoBERTA CodeBERTa 微调 二分类 计算效率
📋 核心要点
- 现有的机器生成内容检测器在准确性和计算成本之间存在权衡,导致检测效果不理想。
- 本文提出通过微调小型语言模型(SLMs),特别是RoBERTA和CodeBERTa,以提高检测准确性并降低计算资源消耗。
- 实验结果显示,所提方法在AUROC和宏F1得分上均优于现有方法,同时显著降低了延迟和内存占用。
📝 摘要(中文)
随着大型语言模型(LLMs)在生成多语言文本和源代码方面的普及,机器生成内容检测器的准确性和效率变得愈发重要。目前的检测器主要采用零-shot方法,如Fast DetectGPT或GPTZero,面临高计算成本或准确性不足的挑战,且常常在两者之间存在权衡。为了解决这些问题,本文提出对编码器小型语言模型(SLMs)进行微调,特别是使用RoBERTA和CodeBERTa的预训练模型,利用专门的数据集进行二分类任务,证明SLMs在计算资源占用上远低于LLMs,同时在准确性上有显著提升。我们的编码器在AUROC和宏F1得分上均表现优异,并在跨生成器转移和对抗性变换下保持高性能。
🔬 方法详解
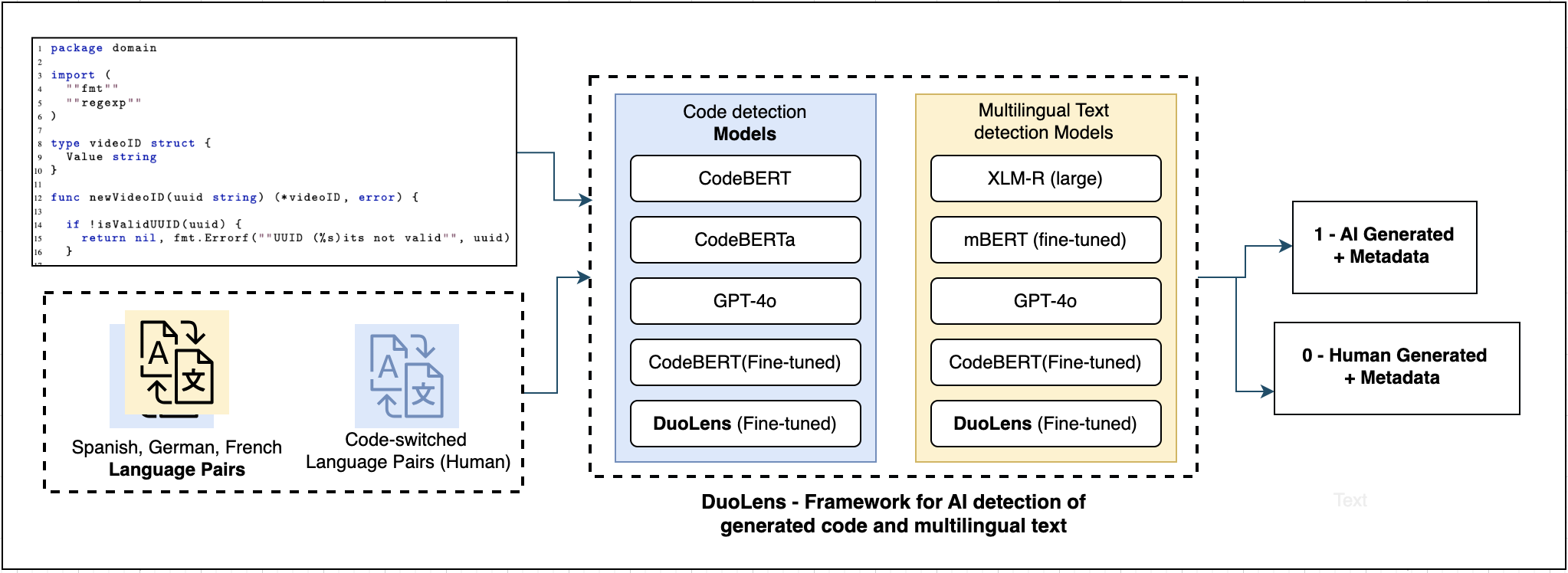
问题定义:本文旨在解决现有机器生成内容检测器在准确性和计算成本之间的权衡问题,现有方法如Fast DetectGPT和GPTZero在这方面表现不佳。
核心思路:通过微调小型语言模型(SLMs),特别是RoBERTA和CodeBERTa,利用专门的数据集进行二分类任务,证明SLMs在计算效率和准确性上均优于大型语言模型(LLMs)。
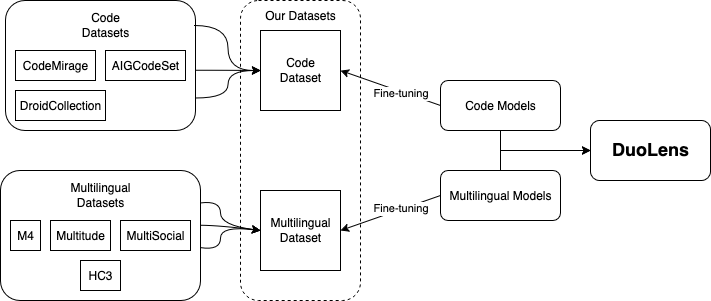
技术框架:整体架构包括数据预处理、模型微调和评估三个主要模块。首先,使用专门的数据集对模型进行微调,然后在不同的生成器和对抗性变换下进行评估。
关键创新:最重要的创新点在于通过微调SLMs实现了在计算资源占用上大幅降低,同时在准确性上显著提升,与现有方法相比,提供了一种更高效的解决方案。
关键设计:在模型微调过程中,采用了特定的损失函数和参数设置,以确保模型在处理源代码和自然语言时的高效性和准确性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,所提SLMs在AUROC得分上达到0.97至0.99,宏F1得分为0.89至0.94,同时在延迟上减少了8至12倍,峰值显存减少了3至5倍,表现出显著的性能提升。
🎯 应用场景
该研究的潜在应用领域包括教育、软件开发和内容审核等,能够有效识别机器生成的文本和代码,从而提高内容的可信度和安全性。未来,该框架有望在多语言环境下的自动化检测和内容管理中发挥重要作用。
📄 摘要(原文)
The prevalence of Large Language Models (LLMs) for generating multilingual text and source code has only increased the imperative for machine-generated content detectors to be accurate and efficient across domains. Current detectors, predominantly utilizing zero-shot methods, such as Fast DetectGPT or GPTZero, either incur high computational cost or lack sufficient accuracy, often with a trade-off between the two, leaving room for further improvement. To address these gaps, we propose the fine-tuning of encoder-only Small Language Models (SLMs), in particular, the pre-trained models of RoBERTA and CodeBERTa using specialized datasets on source code and other natural language to prove that for the task of binary classification, SLMs outperform LLMs by a huge margin whilst using a fraction of compute. Our encoders achieve AUROC $= 0.97$ to $0.99$ and macro-F1 $0.89$ to $0.94$ while reducing latency by $8$-$12\times$ and peak VRAM by $3$-$5\times$ at $512$-token inputs. Under cross-generator shifts and adversarial transformations (paraphrase, back-translation; code formatting/renaming), performance retains $\geq 92%$ of clean AUROC. We release training and evaluation scripts with seeds and configs; a reproducibility checklist is also included.