LightMem: Lightweight and Efficient Memory-Augmented Generation
作者: Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, Ningyu Zhang
分类: cs.CL, cs.AI, cs.CV, cs.LG, cs.MA
发布日期: 2025-10-21 (更新: 2025-11-26)
备注: Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
LightMem:一种轻量高效的记忆增强生成模型,提升LLM在动态环境中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 记忆增强 大型语言模型 动态环境 分层记忆 轻量级 高效推理 离线更新
📋 核心要点
- 大型语言模型难以有效利用历史交互信息,限制了其在动态环境中的应用。
- LightMem借鉴人类记忆模型,设计了感知记忆、短期记忆和长期记忆三个阶段。
- 实验表明,LightMem在多个数据集上显著提升了QA准确率,并大幅降低了token使用量和API调用次数。
📝 摘要(中文)
大型语言模型(LLM)在动态复杂环境中有效利用历史交互信息方面存在困难。记忆系统通过引入持久的信息存储、检索和利用机制,使LLM能够超越无状态交互。然而,现有的记忆系统通常会带来大量的时间和计算开销。为此,我们提出了一种新的记忆系统LightMem,它在记忆系统的性能和效率之间取得了平衡。受到Atkinson-Shiffrin人类记忆模型的启发,LightMem将记忆组织成三个互补的阶段。首先,受认知启发的感知记忆通过轻量级压缩快速过滤不相关的信息,并根据主题对信息进行分组。接下来,主题感知的短期记忆巩固这些基于主题的组,组织和总结内容以便更结构化的访问。最后,具有睡眠时间更新的长期记忆采用离线程序,将巩固与在线推理分离。在LongMemEval和LoCoMo上,使用GPT和Qwen作为backbone,LightMem始终优于强大的基线,QA准确率提高了高达7.7%/29.3%,总token使用量减少了高达38倍/20.9倍,API调用减少了高达30倍/55.5倍,而纯在线测试时成本甚至更低,实现了高达106倍/117倍的token减少和159倍/310倍的API调用减少。代码可在https://github.com/zjunlp/LightMem获得。
🔬 方法详解
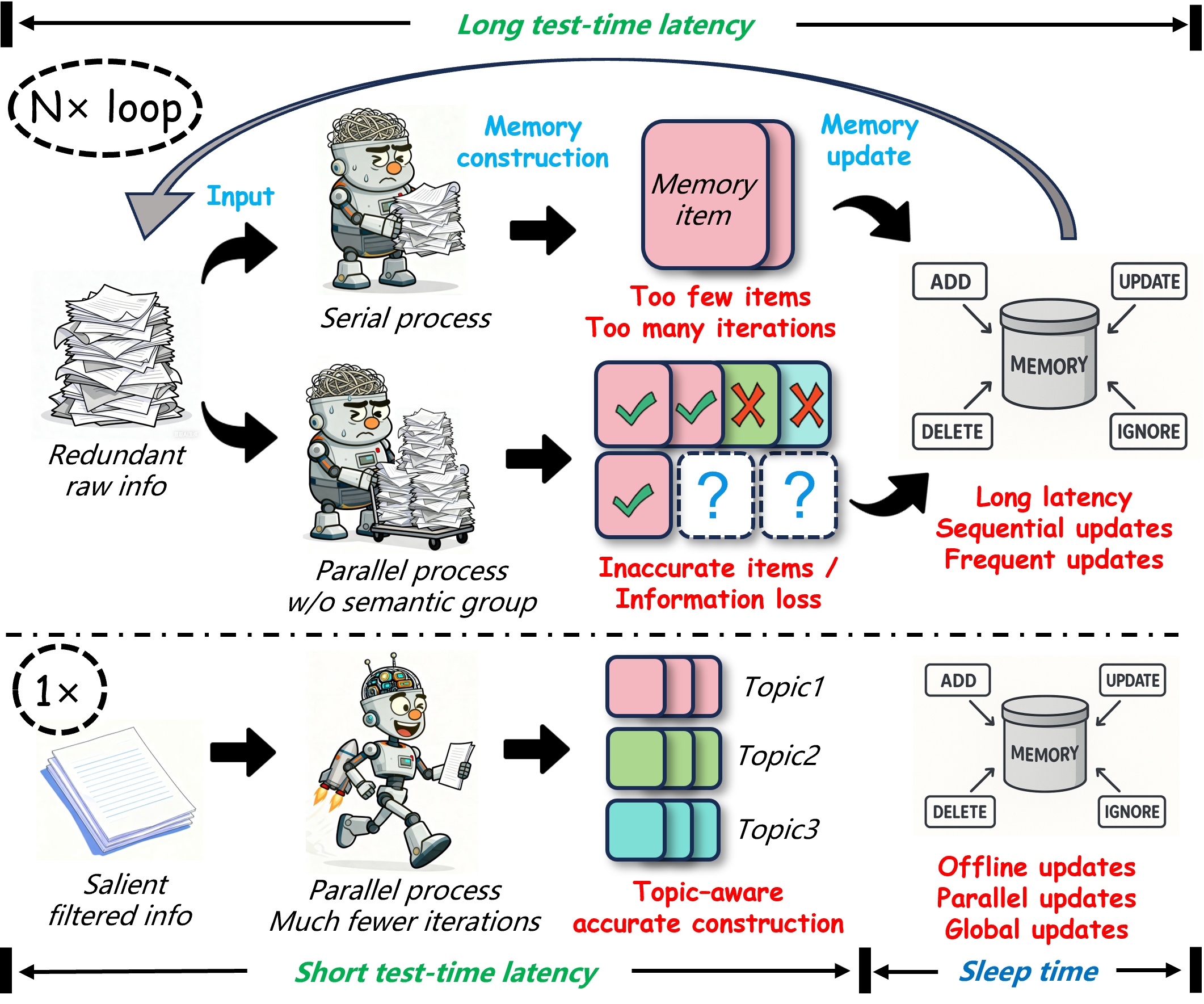
问题定义:现有的大型语言模型在处理动态和复杂的环境时,难以有效地利用历史交互信息。传统的记忆系统虽然可以增强LLM的记忆能力,但通常会引入显著的时间和计算开销,限制了其应用。
核心思路:LightMem的核心思路是模仿人类的记忆机制,将记忆过程分解为三个阶段:感知记忆、短期记忆和长期记忆。通过这种分层结构,可以有效地过滤不相关信息,组织和总结内容,并实现离线更新,从而在性能和效率之间取得平衡。
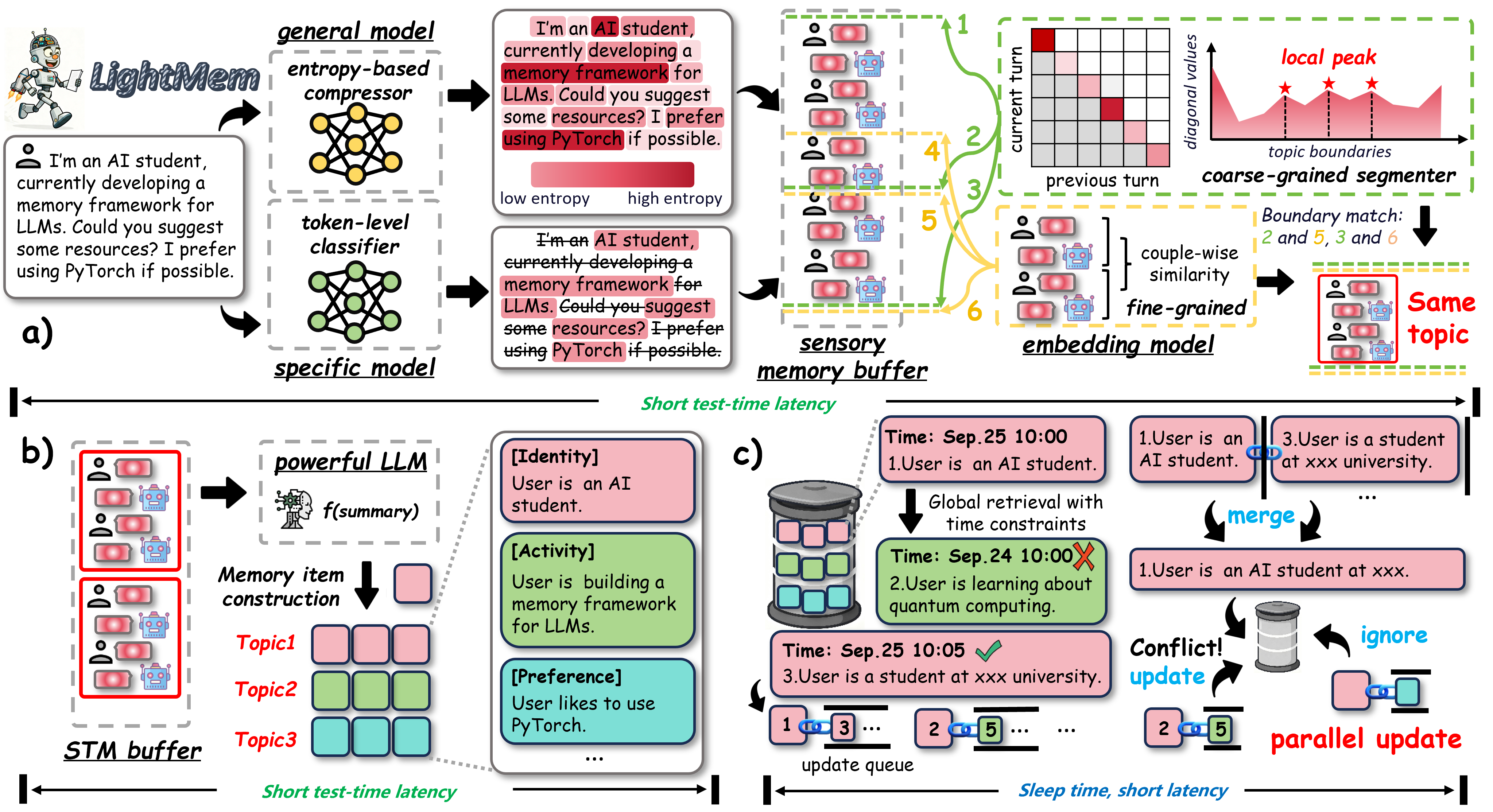
技术框架:LightMem包含三个主要模块: 1. 感知记忆(Sensory Memory):快速过滤不相关信息,通过轻量级压缩和主题分组,减少后续处理的负担。 2. 短期记忆(Short-Term Memory):巩固感知记忆中基于主题的信息组,组织和总结内容,提供更结构化的访问方式。 3. 长期记忆(Long-Term Memory):采用离线更新机制,将记忆的巩固与在线推理分离,降低在线推理的计算成本。
关键创新:LightMem的关键创新在于其分层记忆结构和离线更新机制。与传统的记忆系统相比,LightMem能够更有效地管理和利用历史信息,同时降低计算开销。离线更新机制使得长期记忆的更新不会影响在线推理的效率。
关键设计:感知记忆使用轻量级的压缩算法(具体算法未知)来减少信息冗余。短期记忆使用主题模型(具体模型未知)来组织和总结内容。长期记忆的更新频率和更新策略(具体策略未知)是影响性能的关键参数。损失函数的设计目标是提高QA准确率,同时降低token使用量和API调用次数(具体函数形式未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LightMem在LongMemEval和LoCoMo数据集上显著优于现有基线。使用GPT和Qwen作为backbone时,LightMem将QA准确率提高了高达7.7%/29.3%,总token使用量减少了高达38倍/20.9倍,API调用减少了高达30倍/55.5倍。纯在线测试时成本甚至更低,实现了高达106倍/117倍的token减少和159倍/310倍的API调用减少。
🎯 应用场景
LightMem具有广泛的应用前景,例如智能客服、对话系统、智能助手等需要长期记忆和高效推理的场景。它可以帮助LLM更好地理解用户意图,提供更个性化和准确的服务。此外,LightMem的轻量级设计使其更适合部署在资源受限的设备上,例如移动设备和嵌入式系统。
📄 摘要(原文)
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. On LongMemEval and LoCoMo, using GPT and Qwen backbones, LightMem consistently surpasses strong baselines, improving QA accuracy by up to 7.7% / 29.3%, reducing total token usage by up to 38x / 20.9x and API calls by up to 30x / 55.5x, while purely online test-time costs are even lower, achieving up to 106x / 117x token reduction and 159x / 310x fewer API calls. The code is available at https://github.com/zjunlp/LightMem.