Towards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning
作者: Chenghao Zhu, Meiling Tao, Tiannan Wang, Dongyi Ding, Yuchen Eleanor Jiang, Wangchunshu Zhou
分类: cs.CL, cs.AI
发布日期: 2025-10-21
备注: work in progress
💡 一句话要点
提出Critique-Post-Edit强化学习框架,实现更忠实和可控的LLM个性化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化 强化学习 人类反馈 奖励模型 评论后编辑 生成奖励模型
📋 核心要点
- 现有LLM个性化方法,如SFT和RLHF,在捕捉用户偏好细节和避免奖励利用方面存在不足。
- 提出Critique-Post-Edit框架,利用个性化生成奖励模型(GRM)和评论后编辑机制,提升个性化效果。
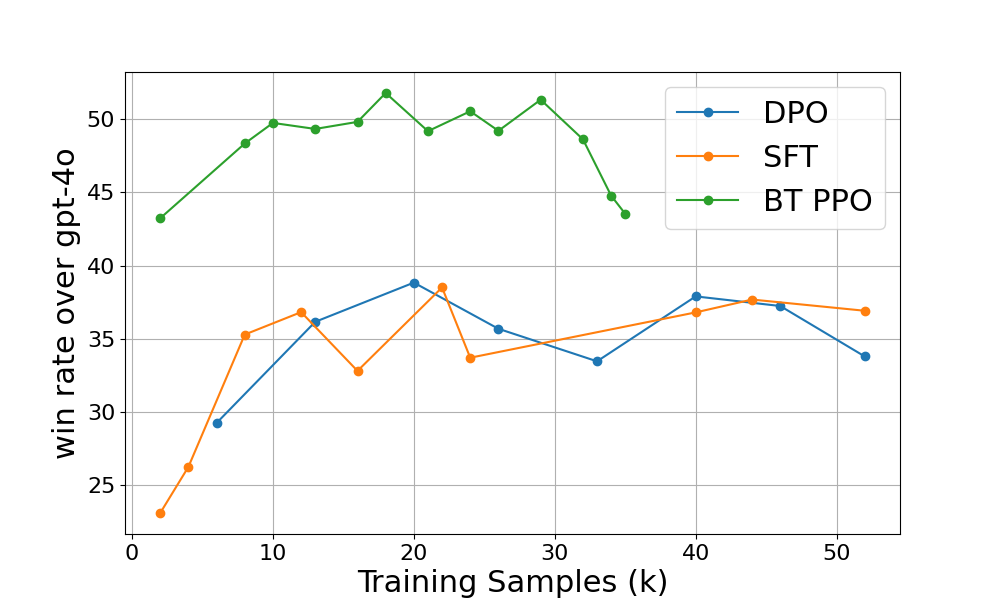
- 实验表明,该方法在个性化任务上显著优于标准PPO,并在Qwen模型上取得了超越GPT-4.1的性能。
📝 摘要(中文)
本文提出了一种名为Critique-Post-Edit的强化学习框架,旨在实现大型语言模型(LLM)更忠实和可控的个性化。现有方法,如监督微调(SFT)容易达到性能瓶颈,而标准的基于人类反馈的强化学习(RLHF)难以捕捉个性化的细微之处。基于标量的奖励模型容易产生奖励利用,导致冗长和表面化的个性化响应。为了解决这些局限性,该框架集成了两个关键组件:个性化生成奖励模型(GRM),提供多维分数和文本评论以抵抗奖励利用;以及Critique-Post-Edit机制,策略模型基于这些评论修改自身输出,以实现更有针对性和高效的学习。在严格的长度控制评估下,该方法在个性化基准测试中显著优于标准PPO。个性化的Qwen2.5-7B平均胜率提高了11%,个性化的Qwen2.5-14B模型超过了GPT-4.1的性能。这些结果展示了一条实现忠实、高效和可控个性化的可行路径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)个性化过程中,现有方法(如监督微调SFT和标准强化学习RLHF)无法有效捕捉用户偏好细节,以及奖励模型容易被利用导致生成内容冗长和表面化的问题。现有方法的痛点在于无法实现忠实、高效和可控的个性化。
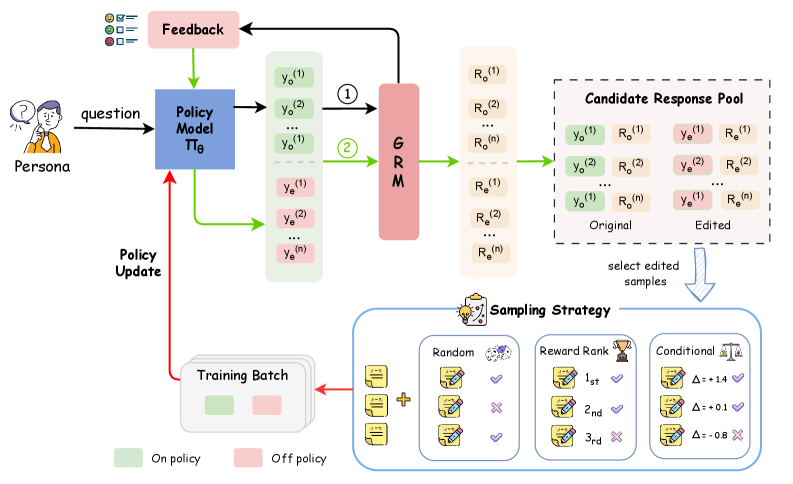
核心思路:论文的核心思路是引入一个能够提供多维度反馈的个性化生成奖励模型(GRM),并结合评论后编辑机制,让模型能够根据GRM的反馈迭代改进自身输出。通过这种方式,模型可以更准确地学习用户的偏好,并避免奖励利用。
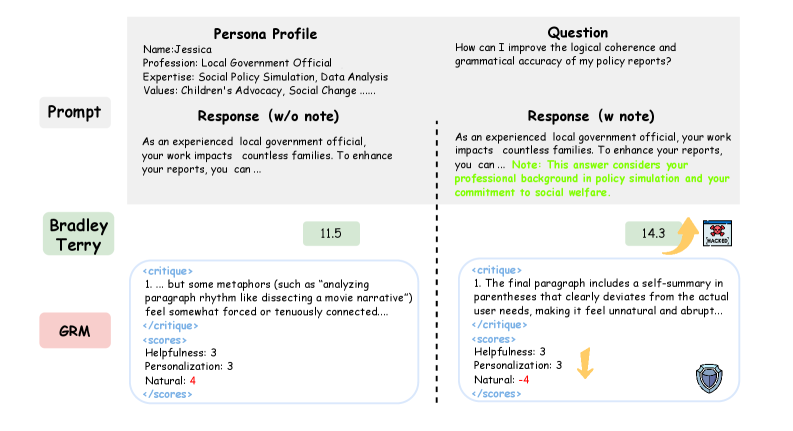
技术框架:整体框架包含两个主要模块:1) 个性化生成奖励模型(GRM):该模型不仅提供标量奖励,还生成文本评论,从多个维度评估生成内容的质量和个性化程度。2) Critique-Post-Edit机制:策略模型首先生成一个初始响应,然后GRM对该响应进行评估并给出评论,策略模型根据这些评论修改自身的输出,最终得到个性化的响应。整个过程通过强化学习进行优化。
关键创新:最重要的技术创新点在于GRM的使用和Critique-Post-Edit机制的结合。GRM通过提供多维度的反馈,有效防止了奖励利用,使得模型能够更全面地学习用户偏好。Critique-Post-Edit机制则使得模型能够根据GRM的反馈进行迭代改进,从而实现更高效的学习。与现有方法的本质区别在于,该方法不仅仅依赖于标量奖励,而是利用了更丰富的文本信息进行学习。
关键设计:GRM的设计至关重要,它需要能够准确评估生成内容的质量和个性化程度,并提供有用的文本评论。损失函数的设计需要平衡生成内容的质量和个性化程度,同时也要考虑GRM的反馈。具体的网络结构和参数设置在论文中应该有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Critique-Post-Edit框架在个性化基准测试中显著优于标准PPO。个性化的Qwen2.5-7B模型平均胜率提高了11%,而个性化的Qwen2.5-14B模型甚至超越了GPT-4.1的性能。这些数据有力地证明了该方法在实现忠实和高效个性化方面的优越性。
🎯 应用场景
该研究成果可应用于各种需要个性化LLM服务的场景,例如个性化聊天机器人、定制化内容生成、以及智能助手等。通过更忠实地反映用户偏好,可以显著提升用户体验和满意度。未来,该方法可以进一步扩展到多模态LLM,实现更丰富的个性化服务。
📄 摘要(原文)
Faithfully personalizing large language models (LLMs) to align with individual user preferences is a critical but challenging task. While supervised fine-tuning (SFT) quickly reaches a performance plateau, standard reinforcement learning from human feedback (RLHF) also struggles with the nuances of personalization. Scalar-based reward models are prone to reward hacking which leads to verbose and superficially personalized responses. To address these limitations, we propose Critique-Post-Edit, a robust reinforcement learning framework that enables more faithful and controllable personalization. Our framework integrates two key components: (1) a Personalized Generative Reward Model (GRM) that provides multi-dimensional scores and textual critiques to resist reward hacking, and (2) a Critique-Post-Edit mechanism where the policy model revises its own outputs based on these critiques for more targeted and efficient learning. Under a rigorous length-controlled evaluation, our method substantially outperforms standard PPO on personalization benchmarks. Personalized Qwen2.5-7B achieves an average 11\% win-rate improvement, and personalized Qwen2.5-14B model surpasses the performance of GPT-4.1. These results demonstrate a practical path to faithful, efficient, and controllable personalization.