MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
作者: Wenxuan Li, Chengruidong Zhang, Huiqiang Jiang, Yucheng Li, Yuqing Yang, Lili Qiu
分类: cs.CL, cs.DC, cs.LG
发布日期: 2025-10-21
🔗 代码/项目: GITHUB
💡 一句话要点
MTraining:分布式动态稀疏注意力加速超长上下文LLM训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文学习 动态稀疏注意力 分布式训练 大型语言模型 训练加速 计算负载均衡 通信优化
📋 核心要点
- 现有动态稀疏注意力方法在超长上下文LLM分布式训练中面临工作节点和步骤级别的不平衡问题,导致训练效率低下。
- MTraining提出了一种新的分布式方法,通过动态稀疏训练模式、平衡稀疏环形注意力和分层稀疏环形注意力来解决计算不平衡和通信开销问题。
- 实验结果表明,MTraining在保持模型准确性的前提下,将Qwen2.5-3B的上下文窗口扩展到512K tokens,并实现了高达6倍的训练吞吐量。
📝 摘要(中文)
长上下文窗口已成为大型语言模型(LLM)的标准配置,扩展的上下文显著增强了其复杂推理能力,并拓宽了其在各种场景中的适用性。动态稀疏注意力是降低长上下文计算成本的一种有前景的方法。然而,在超长上下文中,尤其是在分布式环境中,使用动态稀疏注意力高效训练LLM仍然是一个重大挑战,这主要是由于工作节点和步骤级别的不平衡。本文介绍了一种新的分布式方法MTraining,它利用动态稀疏注意力来实现超长上下文LLM的高效训练。具体来说,MTraining集成了三个关键组件:动态稀疏训练模式、平衡稀疏环形注意力和分层稀疏环形注意力。这些组件旨在协同解决在训练具有扩展上下文长度的模型期间,动态稀疏注意力机制中固有的计算不平衡和通信开销。我们通过训练Qwen2.5-3B,成功地将其上下文窗口从32K扩展到512K tokens,并在32个A100 GPU集群上验证了MTraining的有效性。我们在包括RULER、PG-19、InfiniteBench和Needle In A Haystack在内的一系列下游任务上的评估表明,MTraining在保持模型准确性的同时,实现了高达6倍的训练吞吐量。
🔬 方法详解
问题定义:论文旨在解决超长上下文大型语言模型(LLM)在分布式训练中,由于动态稀疏注意力机制引入的计算不平衡和通信开销问题。现有方法在处理超长上下文时,由于不同worker和step之间计算负载差异大,导致训练效率低下,难以充分利用分布式计算资源。
核心思路:MTraining的核心思路是通过设计一种新的分布式训练方法,来平衡不同worker和step之间的计算负载,并减少通信开销。具体来说,它通过动态调整稀疏模式、平衡稀疏环形注意力和分层稀疏环形注意力等机制,使得每个worker的计算量尽可能接近,并优化数据传输方式,从而提高整体训练效率。
技术框架:MTraining的整体框架包含三个主要组件:动态稀疏训练模式、平衡稀疏环形注意力和分层稀疏环形注意力。动态稀疏训练模式负责根据输入数据的特点动态调整稀疏连接的模式,以适应不同的计算需求。平衡稀疏环形注意力通过重新分配计算任务,使得每个worker的计算负载更加均衡。分层稀疏环形注意力则通过分层聚合的方式,减少通信开销。
关键创新:MTraining的关键创新在于其针对动态稀疏注意力机制的分布式训练优化策略。与传统的静态稀疏或稠密注意力机制不同,MTraining能够根据输入数据的特点动态调整稀疏模式,从而更好地适应不同的计算需求。此外,平衡稀疏环形注意力和分层稀疏环形注意力也为解决分布式训练中的计算不平衡和通信开销问题提供了新的思路。
关键设计:在动态稀疏训练模式中,论文可能使用了某种采样策略来选择重要的token进行关注,具体的采样方法(如基于梯度或注意力权重的采样)未知。平衡稀疏环形注意力可能涉及到对worker进行分组,并根据每个组的计算能力分配任务,具体的分配策略未知。分层稀疏环形注意力可能采用了某种树状结构来聚合信息,具体的树结构和聚合方式未知。损失函数方面,论文可能使用了标准的交叉熵损失函数,但具体是否进行了修改或添加正则化项未知。
🖼️ 关键图片

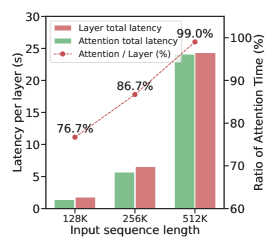

📊 实验亮点
MTraining在32个A100 GPU上成功将Qwen2.5-3B的上下文窗口从32K扩展到512K tokens。在RULER、PG-19、InfiniteBench和Needle In A Haystack等下游任务上的评估表明,MTraining在保持模型准确性的前提下,实现了高达6倍的训练吞吐量提升,证明了其在超长上下文LLM训练方面的有效性。
🎯 应用场景
MTraining技术可广泛应用于需要处理超长上下文的LLM训练场景,例如长文档摘要、代码生成、复杂推理等。该方法能够显著提高训练效率,降低训练成本,加速LLM的开发和部署。未来,该技术有望推动LLM在更多领域的应用,例如智能客服、金融分析、医疗诊断等。
📄 摘要(原文)
The adoption of long context windows has become a standard feature in Large Language Models (LLMs), as extended contexts significantly enhance their capacity for complex reasoning and broaden their applicability across diverse scenarios. Dynamic sparse attention is a promising approach for reducing the computational cost of long-context. However, efficiently training LLMs with dynamic sparse attention on ultra-long contexts-especially in distributed settings-remains a significant challenge, due in large part to worker- and step-level imbalance. This paper introduces MTraining, a novel distributed methodology leveraging dynamic sparse attention to enable efficient training for LLMs with ultra-long contexts. Specifically, MTraining integrates three key components: a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention. These components are designed to synergistically address the computational imbalance and communication overheads inherent in dynamic sparse attention mechanisms during the training of models with extensive context lengths. We demonstrate the efficacy of MTraining by training Qwen2.5-3B, successfully expanding its context window from 32K to 512K tokens on a cluster of 32 A100 GPUs. Our evaluations on a comprehensive suite of downstream tasks, including RULER, PG-19, InfiniteBench, and Needle In A Haystack, reveal that MTraining achieves up to a 6x higher training throughput while preserving model accuracy. Our code is available at https://github.com/microsoft/MInference/tree/main/MTraining.