WebSeer: Training Deeper Search Agents through Reinforcement Learning with Self-Reflection
作者: Guanzhong He, Zhen Yang, Jinxin Liu, Bin Xu, Lei Hou, Juanzi Li
分类: cs.CL
发布日期: 2025-10-21
🔗 代码/项目: GITHUB
💡 一句话要点
WebSeer:通过自反思强化学习训练更深度的搜索Agent
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自反思 搜索Agent 信息检索 工具使用 深度探索 HotpotQA SimpleQA
📋 核心要点
- 现有搜索Agent在复杂交互环境中工具使用深度不足,且迭代交互易累积误差,限制了性能。
- WebSeer通过引入自反思机制,结合强化学习,使Agent能够生成更长、更具反思性的工具使用轨迹。
- 实验结果表明,WebSeer在HotpotQA和SimpleQA数据集上取得了SOTA,并展现出良好的泛化能力。
📝 摘要(中文)
搜索Agent在交互式环境中实现智能信息检索和决策方面取得了显著进展。尽管强化学习已被用于训练能够进行更动态交互式检索的Agent模型,但现有方法受到工具使用深度较浅以及多次迭代交互中误差累积的限制。本文提出了WebSeer,一种通过自反思机制增强的强化学习训练的更智能的搜索Agent。具体而言,我们构建了一个用反思模式注释的大型数据集,并设计了一个两阶段训练框架,该框架在基于真实Web环境的自反思范例中统一了冷启动和强化学习,从而使模型能够生成更长且更具反思性的工具使用轨迹。我们的方法大大扩展了工具使用链并提高了答案准确性。使用单个14B模型,我们在HotpotQA和SimpleQA上实现了最先进的结果,准确率分别为72.3%和90.0%,并证明了对分布外数据集的强大泛化能力。
🔬 方法详解
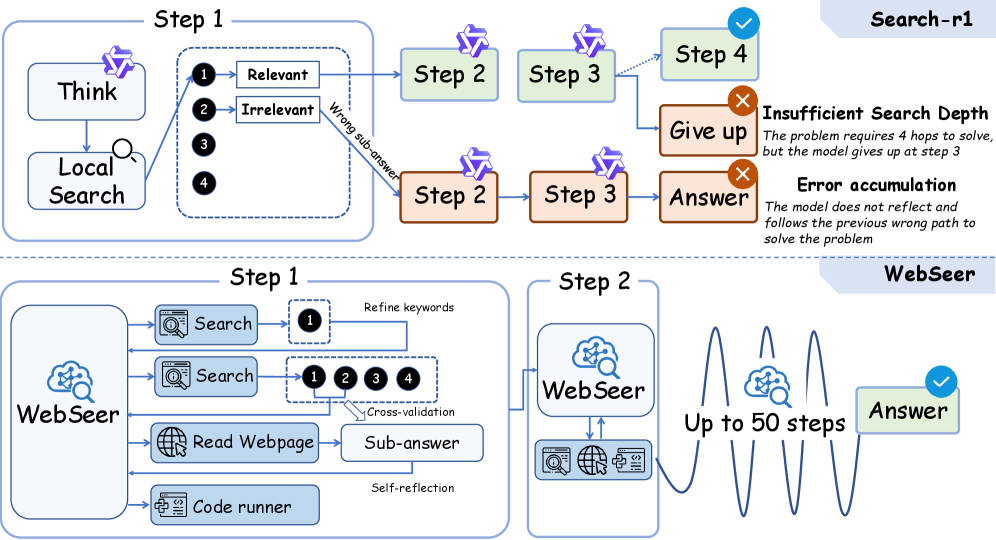
问题定义:现有基于强化学习的搜索Agent在处理复杂问题时,工具使用链较短,难以进行深度探索。此外,在多轮交互过程中,早期步骤的错误会逐渐累积,导致最终结果不准确。因此,如何提升Agent的工具使用深度,并减少误差累积是本文要解决的关键问题。
核心思路:WebSeer的核心思路是引入自反思机制,使Agent能够评估自身行为,并从中学习,从而改进后续的决策。通过自反思,Agent可以识别并纠正错误,避免误差累积,并探索更有效的工具使用策略。这种自反思能力使得Agent能够进行更深度的探索,并生成更准确的答案。
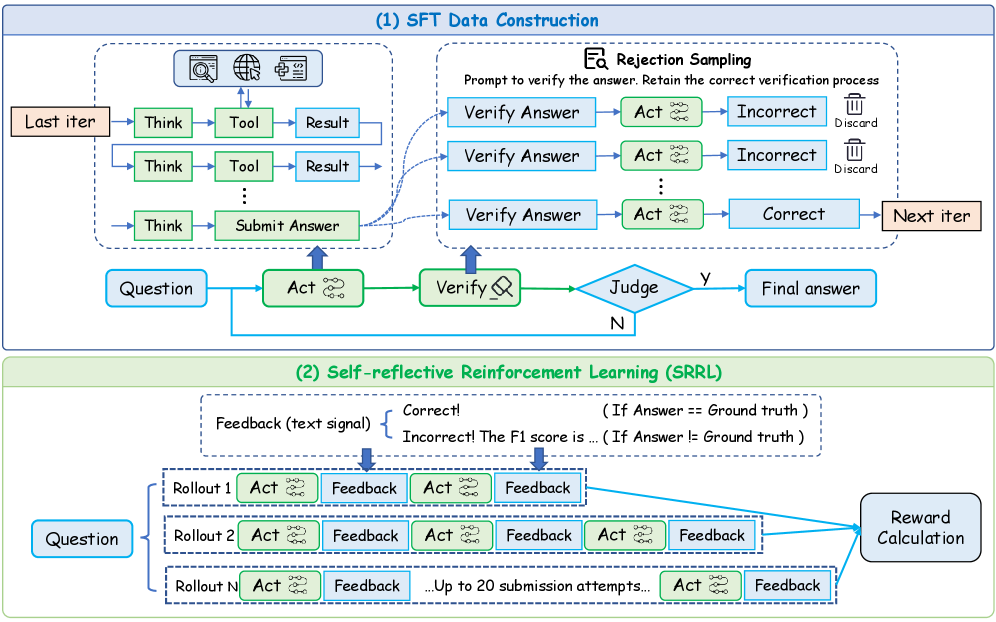
技术框架:WebSeer采用两阶段训练框架。第一阶段是冷启动阶段,利用一个用反思模式注释的大型数据集进行预训练,使Agent初步具备自反思能力。第二阶段是强化学习阶段,Agent在真实Web环境中与环境交互,并通过奖励信号进行优化。在强化学习过程中,Agent会生成工具使用轨迹,并根据自反思结果调整策略。
关键创新:WebSeer的关键创新在于将自反思机制融入到强化学习框架中,从而提升了Agent的工具使用深度和答案准确性。与现有方法相比,WebSeer能够生成更长且更具反思性的工具使用轨迹,并能够更好地应对复杂问题。
关键设计:WebSeer的关键设计包括:1) 构建了一个用反思模式注释的大型数据集,用于预训练Agent的自反思能力;2) 设计了一个两阶段训练框架,将冷启动和强化学习相结合;3) 使用奖励塑形技术,引导Agent学习有效的工具使用策略;4) 采用14B参数的Transformer模型作为Agent的基础架构。
🖼️ 关键图片

📊 实验亮点
WebSeer在HotpotQA和SimpleQA数据集上取得了SOTA结果,准确率分别达到72.3%和90.0%。相较于之前的最佳模型,WebSeer在HotpotQA上取得了显著的性能提升。此外,实验还表明WebSeer具有良好的泛化能力,能够在分布外数据集上保持较高的准确率。这些结果验证了WebSeer的有效性和优越性。
🎯 应用场景
WebSeer技术可应用于智能客服、信息检索、决策支持等领域。例如,在智能客服中,Agent可以利用WebSeer进行更深入的信息挖掘,从而更准确地回答用户的问题。在决策支持系统中,Agent可以利用WebSeer进行更全面的分析,从而为决策者提供更可靠的建议。该研究的未来影响在于推动Agent在复杂交互环境中实现更智能的决策。
📄 摘要(原文)
Search agents have achieved significant advancements in enabling intelligent information retrieval and decision-making within interactive environments. Although reinforcement learning has been employed to train agentic models capable of more dynamic interactive retrieval, existing methods are limited by shallow tool-use depth and the accumulation of errors over multiple iterative interactions. In this paper, we present WebSeer, a more intelligent search agent trained via reinforcement learning enhanced with a self-reflection mechanism. Specifically, we construct a large dataset annotated with reflection patterns and design a two-stage training framework that unifies cold start and reinforcement learning within the self-reflection paradigm for real-world web-based environments, which enables the model to generate longer and more reflective tool-use trajectories. Our approach substantially extends tool-use chains and improves answer accuracy. Using a single 14B model, we achieve state-of-the-art results on HotpotQA and SimpleQA, with accuracies of 72.3% and 90.0%, respectively, and demonstrate strong generalization to out-of-distribution datasets. The code is available at https://github.com/99hgz/WebSeer