KAT-Coder Technical Report
作者: Zizheng Zhan, Ken Deng, Jinghui Wang, Xiaojiang Zhang, Huaixi Tang, Minglei Zhang, Zhiyi Lai, Haoyang Huang, Wen Xiang, Kun Wu, Wenhao Zhuang, Shaojie Wang, Shangpeng Yan, Kepeng Lei, Zongxian Feng, Huiming Wang, Zheng Lin, Mengtong Li, Mengfei Xie, Yinghan Cui, Xuxing Chen, Chao Wang, Weihao Li, Wenqiang Zhu, Jiarong Zhang, Jingxuan Xu, Songwei Yu, Yifan Yao, Xinping Lei, C. Zhang, Han Li, Junqi Xiong, Zuchen Gao, Dailin Li, Haimo Li, Jiaheng Liu, Yuqun Zhang, Junyi Peng, Haotian Zhang, Bin Chen
分类: cs.CL
发布日期: 2025-10-21 (更新: 2025-10-31)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
KAT-Coder:通过多阶段训练提升LLM在交互式软件开发中的自主编码能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic编码 大型语言模型 多阶段训练 强化学习 软件开发 代码生成 工具使用 指令对齐
📋 核心要点
- 现有大型语言模型在静态文本训练和动态真实世界agentic执行之间存在差距,这是核心挑战。
- KAT-Coder通过多阶段训练,包括中期训练、监督微调、强化微调和强化到部署的适应,来解决上述挑战。
- KAT-Coder实现了强大的工具使用可靠性、指令对齐和长上下文推理,为现实世界的智能编码代理奠定了基础。
📝 摘要(中文)
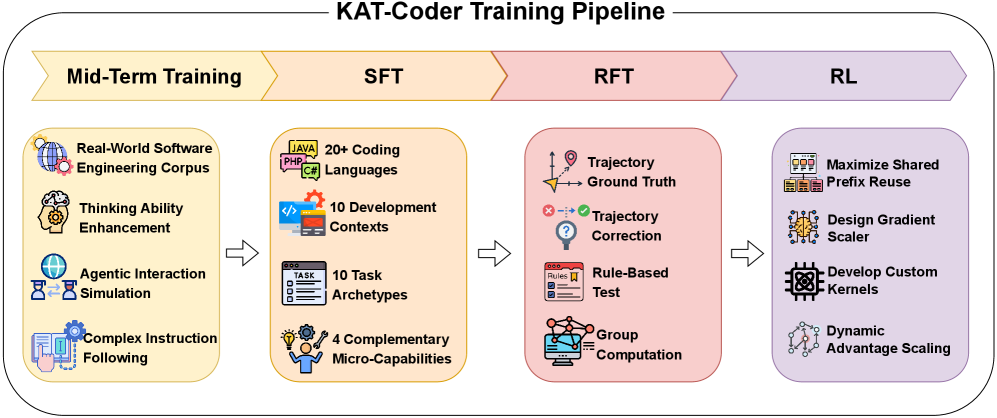
本技术报告介绍了KAT-Coder,一个大规模的agentic代码模型,通过多阶段课程训练而成,包括中期训练、监督微调(SFT)、强化微调(RFT)和强化到部署的适应。中期训练通过真实的软件工程数据和合成的agentic交互来增强推理、规划和反思能力。SFT阶段构建了一个包含百万样本的数据集,平衡了二十种编程语言、十种开发环境和十种任务原型。RFT阶段引入了一种新颖的多重真值奖励公式,用于稳定和样本高效的策略优化。最后,强化到部署阶段使用错误掩码SFT和树状结构轨迹训练,使模型适应生产级IDE环境。这些阶段使KAT-Coder能够实现强大的工具使用可靠性、指令对齐和长上下文推理,为现实世界中的智能编码代理奠定可部署的基础。我们的KAT系列32B模型KAT-Dev已在https://huggingface.co/Kwaipilot/KAT-Dev上开源。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在静态文本数据上训练,难以适应动态的、交互式的软件开发环境。它们在工具使用、指令对齐和长上下文推理方面存在不足,无法有效地自主完成复杂的编码任务。因此,需要一种能够弥合静态训练和动态执行之间差距的方法。
核心思路:KAT-Coder的核心思路是通过多阶段的训练课程,逐步提升LLM在agentic编码方面的能力。从增强基础的推理和规划能力开始,然后通过监督学习使其掌握各种编程语言和开发环境,再利用强化学习优化其策略,最后通过适应性训练使其能够部署到实际的IDE环境中。
技术框架:KAT-Coder的训练框架包含四个主要阶段:1) 中期训练:利用真实软件工程数据和合成的agentic交互,提升模型的推理、规划和反思能力。2) 监督微调(SFT):构建一个包含百万样本的数据集,覆盖多种编程语言、开发环境和任务类型,进行有监督的训练。3) 强化微调(RFT):引入多重真值奖励公式,进行策略优化,提高模型的性能。4) 强化到部署的适应:使用错误掩码SFT和树状结构轨迹训练,使模型适应生产级IDE环境。
关键创新:KAT-Coder的关键创新在于其多阶段的训练课程和针对每个阶段设计的特定技术。例如,RFT阶段的多重真值奖励公式能够更准确地评估模型的行为,从而实现更稳定和样本高效的策略优化。此外,强化到部署的适应阶段能够有效地将模型从模拟环境迁移到真实的IDE环境中。
关键设计:在中期训练阶段,使用了大量的真实软件工程数据和合成的agentic交互数据。在SFT阶段,数据集包含了20种编程语言、10种开发环境和10种任务原型,保证了模型的泛化能力。在RFT阶段,多重真值奖励公式考虑了多种可能的正确答案,避免了单一奖励信号带来的偏差。在强化到部署的适应阶段,错误掩码SFT能够有效地纠正模型在真实环境中的错误,树状结构轨迹训练能够帮助模型更好地理解复杂的任务流程。
🖼️ 关键图片


📊 实验亮点
KAT-Coder通过多阶段训练,显著提升了LLM在agentic编码方面的能力。具体性能数据和对比基线在报告中未明确给出,但强调了其在工具使用可靠性、指令对齐和长上下文推理方面的提升,使其能够更好地适应真实世界的软件开发环境。KAT-Dev模型已开源,为进一步研究和应用提供了基础。
🎯 应用场景
KAT-Coder的研究成果可以广泛应用于智能软件开发领域,例如自动化代码生成、智能代码补全、自动化缺陷修复、智能代码审查等。它可以帮助开发者提高编码效率,降低开发成本,并提升软件质量。未来,KAT-Coder有望成为智能编码代理的基础,实现更加智能化的软件开发流程。
📄 摘要(原文)
Recent advances in large language models (LLMs) have enabled progress in agentic coding, where models autonomously reason, plan, and act within interactive software development workflows. However, bridging the gap between static text-based training and dynamic real-world agentic execution remains a core challenge. In this technical report, we present KAT-Coder, a large-scale agentic code model trained through a multi-stage curriculum encompassing Mid-Term Training, Supervised Fine-Tuning (SFT), Reinforcement Fine-Tuning (RFT), and Reinforcement-to-Deployment Adaptation. The Mid-Term stage enhances reasoning, planning, and reflection capabilities through a corpus of real software engineering data and synthetic agentic interactions. The SFT stage constructs a million-sample dataset balancing twenty programming languages, ten development contexts, and ten task archetypes. The RFT stage introduces a novel multi-ground-truth reward formulation for stable and sample-efficient policy optimization. Finally, the Reinforcement-to-Deployment phase adapts the model to production-grade IDE environments using Error-Masked SFT and Tree-Structured Trajectory Training. In summary, these stages enable KAT-Coder to achieve robust tool-use reliability, instruction alignment, and long-context reasoning, forming a deployable foundation for real-world intelligent coding agents. Our KAT series 32B model, KAT-Dev, has been open-sourced on https://huggingface.co/Kwaipilot/KAT-Dev.