Verifiable Accuracy and Abstention Rewards in Curriculum RL to Alleviate Lost-in-Conversation
作者: Ming Li
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-21
💡 一句话要点
提出RLAAR框架,通过可验证奖励的课程强化学习缓解多轮对话中的信息丢失问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 课程学习 多轮对话 信息丢失 可验证奖励 大型语言模型 弃权机制
📋 核心要点
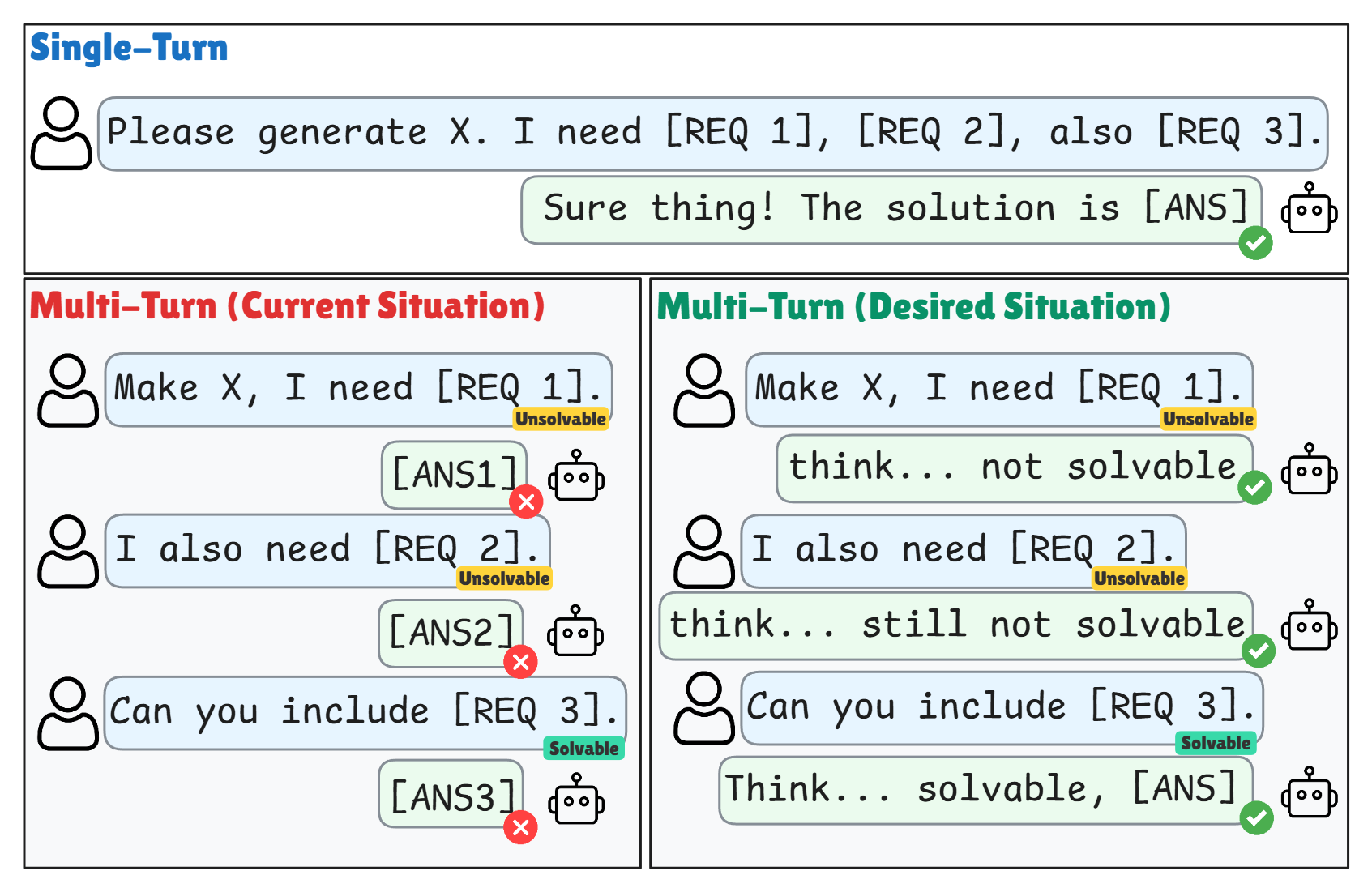
- 现有大型语言模型在多轮对话中存在信息丢失问题,即随着对话轮数的增加,性能显著下降。
- 论文提出RLAAR框架,通过课程学习和可验证的奖励机制,鼓励模型判断问题可解性并适时选择弃权。
- 实验表明,RLAAR显著降低了信息丢失带来的性能衰减,并提高了模型在多轮对话中的可靠性。
📝 摘要(中文)
大型语言模型在单轮指令跟随方面表现出强大的能力,但在多轮对话环境中,随着信息的逐步揭示,性能会下降,即出现信息丢失(Lost-in-Conversation, LiC)现象。受可验证奖励强化学习(RLVR)最新进展的启发,我们提出了具有可验证准确性和弃权奖励的课程强化学习(RLAAR)框架。该框架鼓励模型不仅生成正确的答案,还要判断多轮对话中问题的可解性。我们的方法采用了一种能力门控课程,逐步增加对话难度(以指令碎片的形式),在稳定训练的同时提高可靠性。通过使用多轮、on-policy的rollout和混合奖励系统,RLAAR教导模型在解决问题和知情弃权之间取得平衡,从而减少导致LiC的过早回答行为。在LiC基准测试中,RLAAR显著降低了LiC的性能衰减(从62.6%提高到75.1%),并提高了校准后的弃权率(从33.5%提高到73.4%)。这些结果共同为构建多轮可靠和值得信赖的LLM提供了一个实用的方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在多轮对话中出现的“信息丢失”(Lost-in-Conversation, LiC)问题。现有方法在处理多轮对话时,往往难以保持对先前信息的有效利用,导致性能随着对话轮数的增加而下降。痛点在于模型无法准确判断何时应该尝试回答,何时应该选择放弃,从而避免因信息不足而产生错误答案。
核心思路:RLAAR的核心思路是通过强化学习训练模型,使其具备判断问题可解性的能力,并学会适时选择“弃权”。通过引入可验证的准确性奖励和弃权奖励,鼓励模型在不确定时选择放弃,从而避免因信息不足而导致的错误回答。课程学习则用于逐步增加对话难度,稳定训练过程,并提高模型的泛化能力。
技术框架:RLAAR框架主要包含以下几个关键模块:1) 环境:模拟多轮对话场景,逐步揭示问题信息。2) 智能体:大型语言模型,负责生成答案或选择弃权。3) 奖励函数:包含可验证的准确性奖励和弃权奖励,用于指导智能体的学习。4) 课程学习:逐步增加对话难度,从简单的单轮对话到复杂的多轮对话。5) 能力门控:根据模型的能力动态调整课程难度,确保训练的稳定性和有效性。
关键创新:RLAAR的关键创新在于将可验证奖励的强化学习与课程学习相结合,并引入了弃权机制。这使得模型不仅能够学习生成正确的答案,还能够学习判断问题的可解性,并在不确定时选择放弃。这种方法有效地缓解了多轮对话中的信息丢失问题,提高了模型的可靠性。
关键设计:RLAAR的关键设计包括:1) 混合奖励系统:平衡准确性奖励和弃权奖励,鼓励模型在解决问题和知情弃权之间取得平衡。2) 能力门控课程:根据模型的能力动态调整课程难度,确保训练的稳定性和有效性。3) 多轮、on-policy的rollout:利用多轮对话数据进行训练,提高模型对多轮对话场景的适应性。4) 损失函数:采用合适的损失函数来优化模型的参数,例如交叉熵损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RLAAR框架显著降低了LiC的性能衰减(从62.6%提高到75.1%),并提高了校准后的弃权率(从33.5%提高到73.4%)。这些数据表明,RLAAR能够有效地缓解多轮对话中的信息丢失问题,并提高模型在不确定情况下的判断能力。相较于基线模型,RLAAR在多轮对话任务中表现出更强的鲁棒性和可靠性。
🎯 应用场景
RLAAR框架可应用于各种需要多轮对话交互的场景,例如智能客服、虚拟助手、教育辅导等。通过提高模型在多轮对话中的可靠性和准确性,可以提升用户体验,并减少错误信息的传播。该研究对于构建更值得信赖和可靠的大型语言模型具有重要意义,并为未来的多轮对话系统设计提供了新的思路。
📄 摘要(原文)
Large Language Models demonstrate strong capabilities in single-turn instruction following but suffer from Lost-in-Conversation (LiC), a degradation in performance as information is revealed progressively in multi-turn settings. Motivated by the current progress on Reinforcement Learning with Verifiable Rewards (RLVR), we propose Curriculum Reinforcement Learning with Verifiable Accuracy and Abstention Rewards (RLAAR), a framework that encourages models not only to generate correct answers, but also to judge the solvability of questions in the multi-turn conversation setting. Our approach employs a competence-gated curriculum that incrementally increases dialogue difficulty (in terms of instruction shards), stabilizing training while promoting reliability. Using multi-turn, on-policy rollouts and a mixed-reward system, RLAAR teaches models to balance problem-solving with informed abstention, reducing premature answering behaviors that cause LiC. Evaluated on LiC benchmarks, RLAAR significantly mitigates LiC performance decay (62.6% to 75.1%) and improves calibrated abstention rates (33.5% to 73.4%). Together, these results provide a practical recipe for building multi-turn reliable and trustworthy LLMs.