CEFR-Annotated WordNet: LLM-Based Proficiency-Guided Semantic Database for Language Learning
作者: Masato Kikuchi, Masatsugu Ono, Toshioki Soga, Tetsu Tanabe, Tadachika Ozono
分类: cs.CL
发布日期: 2025-10-21
💡 一句话要点
提出基于LLM的CEFR标注WordNet,用于提升语言学习效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: WordNet CEFR 语言学习 大型语言模型 语义相似度 词汇分类 自然语言处理
📋 核心要点
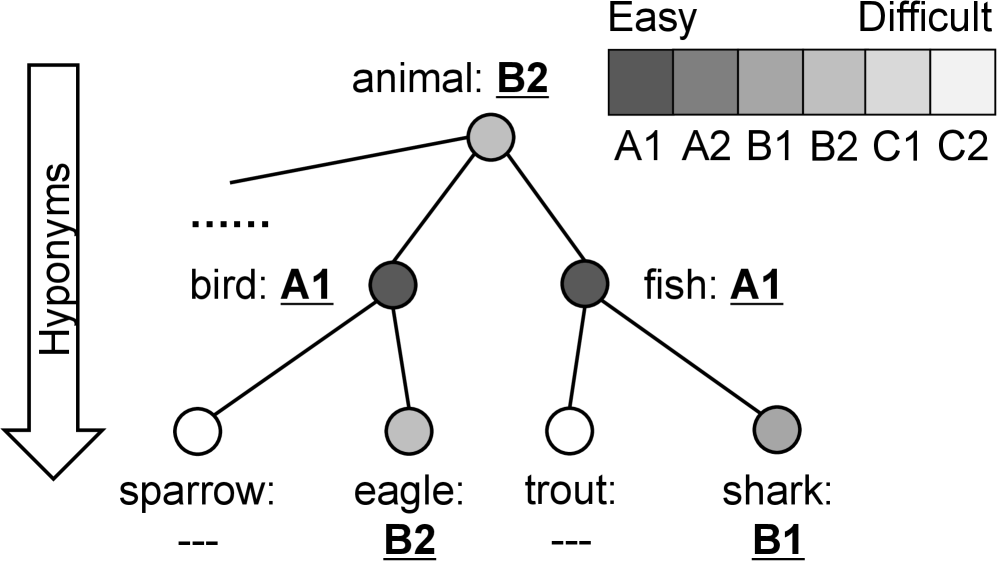
- WordNet的细粒度语义区分对二语学习者构成挑战,难以有效利用其丰富的语义信息。
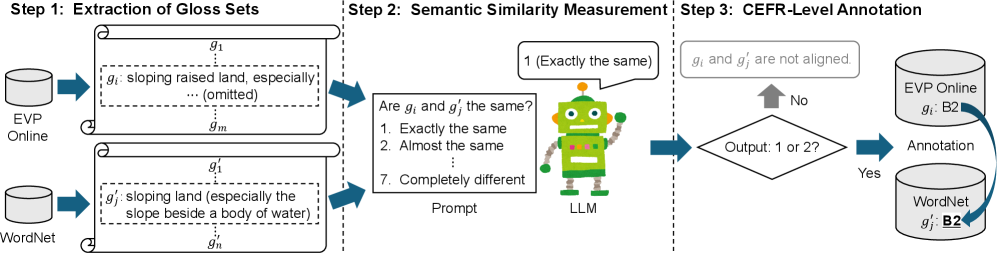
- 利用大型语言模型测量WordNet词义定义与英语词汇Profile Online条目的语义相似度,实现CEFR等级标注。
- 构建大规模语料库并训练词汇分类器,实验表明模型性能与金标准数据训练的模型相当,Macro-F1达到0.81。
📝 摘要(中文)
本文提出了一种基于通用欧洲语言参考框架(CEFR)标注的WordNet,旨在将语义网络与语言能力水平相结合,从而解决WordNet细粒度的语义区分对二语学习者构成挑战的问题。该方法利用大型语言模型自动测量WordNet中词义定义与英语词汇Profile Online条目之间的语义相似度。为了验证该方法,构建了一个包含词义和CEFR等级信息的大规模语料库,并用于开发上下文词汇分类器。实验结果表明,在本文语料库上微调的模型性能与在金标准标注数据上训练的模型相当。此外,通过将本文语料库与金标准数据相结合,开发了一个实用的分类器,其Macro-F1得分为0.81,表明标注具有高准确性。本文标注的WordNet、语料库和分类器已公开,旨在弥合自然语言处理和语言教育之间的差距,从而促进更有效和高效的语言学习。
🔬 方法详解
问题定义:WordNet虽然拥有结构化的语义网络和广泛的词汇,但其细粒度的词义区分对于第二语言学习者来说可能过于复杂,难以理解和应用。现有的语言学习资源缺乏与学习者能力水平相对应的语义信息,导致学习效率低下。
核心思路:本文的核心思路是利用大型语言模型(LLM)的语义理解能力,自动将WordNet中的词义与通用欧洲语言参考框架(CEFR)的等级进行对齐。通过将词义的复杂程度与学习者的语言能力水平相匹配,从而为学习者提供更适合其当前水平的语义信息。
技术框架:整体框架包括以下几个主要阶段:1) 数据准备:收集WordNet的词义定义和英语词汇Profile Online (EVPO) 的词汇条目。2) 语义相似度计算:使用LLM计算WordNet词义定义和EVPO词汇条目之间的语义相似度。3) CEFR等级标注:基于语义相似度,将WordNet词义标注为相应的CEFR等级。4) 语料库构建:构建包含词义和CEFR等级信息的大规模语料库。5) 模型训练与评估:使用语料库训练上下文词汇分类器,并与金标准数据进行比较评估。
关键创新:最重要的技术创新点在于利用LLM自动进行CEFR等级标注,避免了传统人工标注的成本和主观性。通过语义相似度计算,将词义的复杂程度与学习者的语言能力水平相关联,从而实现了个性化的语言学习资源。与现有方法相比,该方法能够更有效地利用WordNet的语义信息,并将其应用于语言学习领域。
关键设计:在语义相似度计算中,使用了预训练的LLM(具体模型未知)来编码WordNet词义定义和EVPO词汇条目,然后计算它们之间的余弦相似度。CEFR等级的分配基于相似度阈值,阈值的具体数值未知。损失函数和网络结构的选择取决于上下文词汇分类器的具体实现,论文中未详细说明。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在本文构建的语料库上微调的上下文词汇分类器性能与在金标准标注数据上训练的模型相当。通过将本文语料库与金标准数据相结合,开发了一个实用的分类器,其Macro-F1得分为0.81,表明标注具有高准确性,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于在线语言学习平台、智能词典、语言教学辅助工具等领域。通过提供与学习者能力水平相匹配的语义信息,可以提高语言学习的效率和效果。未来,可以将该方法扩展到其他语言和知识领域,构建更智能化的学习资源。
📄 摘要(原文)
Although WordNet is a valuable resource owing to its structured semantic networks and extensive vocabulary, its fine-grained sense distinctions can be challenging for second-language learners. To address this, we developed a WordNet annotated with the Common European Framework of Reference for Languages (CEFR), integrating its semantic networks with language-proficiency levels. We automated this process using a large language model to measure the semantic similarity between sense definitions in WordNet and entries in the English Vocabulary Profile Online. To validate our method, we constructed a large-scale corpus containing both sense and CEFR-level information from our annotated WordNet and used it to develop contextual lexical classifiers. Our experiments demonstrate that models fine-tuned on our corpus perform comparably to those trained on gold-standard annotations. Furthermore, by combining our corpus with the gold-standard data, we developed a practical classifier that achieves a Macro-F1 score of 0.81, indicating the high accuracy of our annotations. Our annotated WordNet, corpus, and classifiers are publicly available to help bridge the gap between natural language processing and language education, thereby facilitating more effective and efficient language learning.